1 ▒│Š░
ļSų°ą┼Žó╝╝ąg(sh©┤)Ą─čĖ├═░l(f©Ī)š╣Ż¼╚╦éā┐╔ęį└¹ė├ėŗ(j©¼)╦ŃÖC(j©®)ĘĮ▒ŃĄž½@╚Ī║═┤µā”(ch©│)┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)ĪŻĄ½╩ŪŻ¼āHāH═Ż┴¶į┌ī”(du©¼)ė┌ęč½@Ą├Ą─öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąę╗ą®▒ĒīėĄ─╠Ä└Ē(╚ń▓ķįāĪóĮy(t©»ng)ėŗ(j©¼)Ą╚)ęčįĮüĒ(l©ói)įĮ▓╗─▄ØMūŃ╚š│Ż╣żū„Ą─ąĶ꬯¼ę“Č°╚╦éā░čąĶę¬╔Ņ╚ļ═┌Š“öĄ(sh©┤)ō■(j©┤)ų«ķgĄ─ā╚(n©©i)į┌ĻP(gu©Īn)ŽĄ║═ļ[║¼Ą─ą┼Žóū„×ķŽ┬ę╗▓ĮĄ─蹊┐─┐ś╦(bi©Īo)ĪŻ╚╦éāŲ╚ŪąąĶę¬ę╗ĘN─▄ē“ųŪ─▄Ą─Īóūįäė(d©░ng)Ą─īóöĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ│╔ėąė├ą┼Žó║═ų¬ūR(sh©¬)Ą─╝╝ąg(sh©┤)║═╣żŠ▀Ż¼▀@ĘNī”(du©¼)ÅŖ(qi©óng)ėą┴”öĄ(sh©┤)ō■(j©┤)Ęų╬÷╣żŠ▀Ą─Ų╚ŪąąĶŪ¾╩╣Ą├öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)│╔×ķ┴╦ą┼Žó╝╝ąg(sh©┤)ųąĄ─ę╗éĆ(g©©)Ū░螥─Į╣³c(di©Żn)ĪŻ
2 öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ŽÓĻP(gu©Īn)└Ēšō
2.1 öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─Ė┼─Ņ
öĄ(sh©┤)ō■(j©┤)═┌Š“Å─┤¾┴┐Ą─Ż¼▓╗═Ļš¹Ą─Ż¼ėąįļ┬Ģ▀M(j©¼n)ąą─Ż║²ļSÖC(j©®)į┌įŁ╩╝öĄ(sh©┤)ō■(j©┤)Ż¼╠ß╚Īļ[▓mŻ¼╚╦éā╩┬Ž╚▓╗ų¬Ą└Ż¼Č°Ūę╩ŪØōį┌ėąė├Ą─Ż¼┐╔ą┼Ą─Ż¼ą┬ĘfĄ─ą┼Žó║═ų¬ūR(sh©¬)Ą─▀^(gu©░)│╠ĪŻöĄ(sh©┤)ō■(j©┤)═┌Š“ė╔╚²éĆ(g©©)▓Į¾EĮM│╔Ż║öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└ĒļAČ╬Īó─Żą═įO(sh©©)ėŗ(j©¼)ļAČ╬║═öĄ(sh©┤)ō■(j©┤)Ęų╬÷ļAČ╬(ęŖ(ji©żn)łD1)ĪŻ
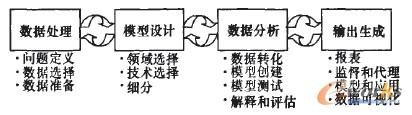
łD1 öĄ(sh©┤)ō■(j©┤)═┌Š“┴„│╠
(1)öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└ĒļAČ╬(Data Preprocessing Phase)ųąŻ¼╠žČ©Ą─śI(y©©)äš(w©┤)å¢(w©©n)Ņ}▒žĒÜĄ├ĄĮ├„┤_Ą─Č©┴xŻ¼Ę±ätöĄ(sh©┤)ō■(j©┤)═┌Š“?q©▒)óūāĄ├┬■¤o(w©▓)─┐Ą─ĪŻį┌śI(y©©)äš(w©┤)å¢(w©©n)Ņ}Ą─ė“ų¬ūR(sh©¬)╗∙ĄA(ch©│)╔ŽŻ¼įōļAČ╬Ą─╚╬äš(w©┤)░³└©“×(y©żn)ūCĪó▀xō±║═£╩(zh©│n)éõ▒╗ę¬Ū¾ė├üĒ(l©ói)šō╩÷å¢(w©©n)Ņ}Ą─öĄ(sh©┤)ō■(j©┤)ĪŻį┌śŗ(g©░u)įņ┴╝║├Ą─öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Łh(hu©ón)Š│└’Ż¼▀@ą®▓Į¾EŽÓī”(du©¼)║å(ji©Żn)å╬ą®Ż¼Ą½╩Ū╚į╚╗Ģ■(hu©¼)╔µ╝░ĄĮī”(du©¼)▓╔śė║═ŲĮ║ŌöĄ(sh©┤)ō■(j©┤)Ą─┐╝æ]ĪŻ
(2)─Żą═įO(sh©©)ėŗ(j©¼)ļAČ╬(Model Design Phase)ąĶę¬╔Ņ╚ļĄžÖz▓ķöĄ(sh©┤)ō■(j©┤)Ż¼▓óÅ─ųą▀xō±─Ūą®’@╩Š┼cå¢(w©©n)Ņ}ūŅėąĻP(gu©Īn)ŽĄĄ─ūųČ╬Ż¼╦³ę▓ąĶę¬▀xō±ę╗éĆ(g©©)š²┤_Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©ęįæ¬(y©®ng)ė├ė┌öĄ(sh©┤)ō■(j©┤)(╚ńŻ║øQ▓▀śõ(sh©┤)ĪóęÄ(gu©®)ätÜw╝{)ĪŻ╚╗║¾Ż¼ūŅąĪ╗»Ąž╝Ü(x©¼)Ęų?j©½n)?sh©┤)ō■(j©┤)Ż¼ę╗░ŃąĶę¬īóöĄ(sh©┤)ō■(j©┤)Ęų×ķę╗éĆ(g©©)š{(di©żo)š¹╝»╗“š▀ČÓéĆ(g©©)£y(c©©)įć╝»ĪŻ
(3)öĄ(sh©┤)ō■(j©┤)Ęų╬÷ļAČ╬(Data Analysis Phase)Ąõą═Ąž░³└©ę╗éĆ(g©©)ĖĮ╝ėĄ─£╩(zh©│n)éõ╗Ņäė(d©░ng)(öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ)üĒ(l©ói)ųžĮMöĄ(sh©┤)ō■(j©┤)Ż¼ęįŪ¾Ė³║├ĄžŲź┼õ╝║▀xō±Ą─╦ŃĘ©║═śI(y©©)äš(w©┤)å¢(w©©n)Ņ}(└²╚ńŻ¼╠Ä└ĒöĄ(sh©┤)ō■(j©┤)ųą╚▒╔┘Ą─ųĄ)ĪŻ┤╦║¾īóęčĮø(j©®ng)▀xō±║├Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀æ¬(y©®ng)ė├ė┌öĄ(sh©┤)ō■(j©┤)Ż¼Ąõą═ŪķørŽ┬░³└©äō(chu©żng)Į©ę╗éĆ(g©©)▓╔ė├öĄ(sh©┤)ō■(j©┤)ą▐š²╝»Ą──Żą═Ż¼╚╗║¾ė├ų┴╔┘ę╗éĆ(g©©)£y(c©©)įćöĄ(sh©┤)ō■(j©┤)Ą─¬Ü(d©▓)┴ó╝»üĒ(l©ói)ūC├„▀@éĆ(g©©)─Żą═ĪŻ─Żą═Ą─£╩(zh©│n)┤_ąį║═ėąą¦ąįąĶėąą¦Ąžįu(p©¬ng)╣└ĪŻ│§╩╝Ą──Żą═īó║▄┐╔─▄ø](m©”i)Ę©▀_(d©ó)ĄĮöĄ(sh©┤)ō■(j©┤)═┌Š“Ą──┐Ą─Ż¼įSČÓĘ┤Å═(f©┤)╩Ūėą▒žę¬Ą─Ż¼ė╚Ųõ╩Ūį┌─Żą═įO(sh©©)ėŗ(j©¼)║═öĄ(sh©┤)ō■(j©┤)Ęų╬÷ļAČ╬ųąĪŻ
2.2 øQ▓▀śõ(sh©┤)Ą─Ė┼─Ņ
øQ▓▀śõ(sh©┤)╩Ūū„×ķ┼cśė▒Šī┘ąįĮY(ji©”)³c(di©Żn)Ż¼ė├ī┘ąįĄ─╚ĪųĄū„×ķĘųų¦Ą─śõ(sh©┤)ą═ĮY(ji©”)śŗ(g©░u)ĪŻ╦³╩Ū▀M(j©¼n)ąą┴╦Ęų╬÷║═Üw╝{└¹ė├ą┼Žó└ĒšōĄ─įŁätŻ¼Ęų╬÷┤¾ęÄ(gu©®)─ŻĄ─śė▒Šī┘ąįČ°«a(ch©Żn)╔·Ą─ĪŻøQ▓▀śõ(sh©┤)Ą─Ė∙╣Ø(ji©”)³c(di©Żn)╩ŪūŅ┤¾Ą─ī┘ąįą┼ŽóĄ─ā╚(n©©i)╚▌Ż¼į┌╦∙ėąśė▒ŠĪŻśõ(sh©┤)Ą─ųąķg╣Ø(ji©”)³c(di©Żn)╩Ūį┌╩Š└²ūė╝»Ą─Ė∙śõ(sh©┤)░³║¼Ą─ą┼Žóā╚(n©©i)╚▌ūŅ┤¾Ą─ī┘ąį³c(di©Żn)ĪŻøQ▓▀śõ(sh©┤)Ą─╚~³c(di©Żn)╩ŪśėŲĘŅÉäeĄ─ār(ji©ż)ųĄĪŻøQ▓▀śõ(sh©┤)╩╣ė├ą┬Ą─śė▒ŠĘųŅÉŻ¼╝┤═©▀^(gu©░)ą┬Ą─øQ▓▀śõ(sh©┤)ī┘ąįųĄ£y(c©©)įćĄ─śė▒ŠŻ¼Å─śõ(sh©┤)Ą─Ė∙╣Ø(ji©”)³c(di©Żn)ķ_(k©Īi)╩╝Ż¼Ė∙ō■(j©┤)śė▒Šī┘ąįųĄųØuŽ“Ž┬čžøQ▓▀śõ(sh©┤)Ż¼ų▒ĄĮśõ(sh©┤)Ą─╚~ūė³c(di©Żn)Ż¼▀@ę╗³c(di©Żn)▒Ē¼F(xi©żn)Ą─ŅÉ╩Ūą┬Ą─śė▒ŠŅÉäeĪŻøQ▓▀śõ(sh©┤)ĘĮĘ©╩Ūį┌öĄ(sh©┤)ō■(j©┤)═┌Š“ųąĘŪ│Żėąą¦Ą─ĘĮĘ©ĪŻøQ▓▀śõ(sh©┤)╩Ūę╗ĘNų¬ūR(sh©¬)Ą─ę╗ĘN▒Ē¼F(xi©żn)ą╬╩ĮŻ¼╦³╩Ū╦∙ėąĖ▀▓╔śėöĄ(sh©┤)ō■(j©┤)š¬ę¬Ż¼╝┤øQ▓▀śõ(sh©┤)─▄£╩(zh©│n)┤_ūR(sh©¬)äe╦∙ėąĄ─śė▒ŠŅÉäeŻ¼ę▓┐╔ęįėąą¦ūR(sh©¬)äeĄžą┬śė▒ŠĄ─ŅÉäeĪŻ
øQ▓▀śõ(sh©┤)░³║¼įSČÓ▓╗═¼Ą─╦ŃĘ©Ż¼ų„ę¬Ęų×ķ3ŅÉŻ║
(1)╗∙ė┌Įy(t©»ng)ėŗ(j©¼)šōĄ─ĘĮĘ©Ż¼ęįCART×ķ┤·▒ĒŻ¼į┌▀@ŅÉ╦ŃĘ©ųąŻ¼ī”(du©¼)ė┌ĘŪĮKČ╦ĮY(ji©”)³c(di©Żn)üĒ(l©ói)šf(shu©Ł)Ż¼ėąā╔éĆ(g©©)Ęųų”ĪŻ
(2)╗∙ė┌ą┼ŽóšōĄ─ĘĮĘ©Ż¼ęįD13╦ŃĘ©×ķ┤·▒ĒŻ¼┤╦ŅÉ╦ŃĘ©ųąŻ¼ĘŪĮKČ╦ĮY(ji©”)³c(di©Żn)Ą─Ęųų”öĄ(sh©┤)ė╔śė▒ŠŅÉäeéĆ(g©©)öĄ(sh©┤)øQČ©ĪŻ
(3)ęįAIDŻ¼CHAIN×ķ┤·▒ĒĄ─╦ŃĘ©Ż¼į┌┤╦ŅÉ╦ŃĘ©ųąŻ¼ĘŪĮKČ╦ĮY(ji©”)³c(di©Żn)Ą─Ęųų”öĄ(sh©┤)į┌ā╔éĆ(g©©)ĄĮśė▒ŠŅÉäeéĆ(g©©)öĄ(sh©┤)ĘČć·ā╚(n©©i)Ęų▓╝ĪŻ
▀xō±øQ▓▀śõ(sh©┤)╦ŃĘ©Ą─ā×(y©Łu)³c(di©Żn)ėąŻ║į┌īW(xu©”)┴Ģ(x©¬)▀^(gu©░)│╠ųą▓╗ąĶę¬╩╣ė├š▀┴╦ĮŌ║▄ČÓĄ─▒│Š░ų¬ūR(sh©¬)▀@═¼Ģr(sh©¬)╩Ū╦³Ą──▄ē“ų▒Įė¾w¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)Ą─╠ž³c(di©Żn)Ż¼║▄╚▌ęū▒╗╚╦└ĒĮŌĪŻ╦┘Č╚┐ņĪŻęūĖ─įņĘųŅÉęÄ(gu©®)ätĪŻų╗ę¬čžśõ(sh©┤)Ą─Ė∙╚~Ž“Ž┬Ż¼čž═Š┐╔ęįų╗┤_Č©ę╗éĆ(g©©)ĘųŅÉęÄ(gu©®)ätĄ─┴čūāŚl╝■ĪŻĖ³Ė▀Ą─Š½Č╚ĪŻ═¼Ģr(sh©¬)Ż¼╦³ę▓ėąįSČÓ▓╗ūŃų«╠ÄŻ¼ęį╠Ä└ĒįO(sh©©)ų├├┐éĆ(g©©)╦ŃĘ©(ļx╔óŻ¼śėŲĘ)Ż¼▓╗āHį÷╝ė┴╦┼┼ą“╦ŃĘ©Ą─ķ_(k©Īi)õNŻ¼Č°ŪęĮĄĄ═┴╦┤¾ą═öĄ(sh©┤)ō■(j©┤)ĘųŅÉĄ─£╩(zh©│n)┤_ąįĪŻ
2.3 øQ▓▀śõ(sh©┤)Ą─ų„ę¬▓Į¾E
øQ▓▀śõ(sh©┤)╦ŃĘ©śŗ(g©░u)įņøQ▓▀śõ(sh©┤)üĒ(l©ói)░l(f©Ī)¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)ųą╠N(y©┤n)║ŁĄ─ĘųŅÉęÄ(gu©®)ätŻ¼╚ń║╬śŗ(g©░u)įņŠ½Č╚Ė▀ĪóęÄ(gu©®)─ŻąĪĄ─øQ▓▀śõ(sh©┤)╩ŪøQ▓▀śõ(sh©┤)╦ŃĘ©Ą─║╦ą─ā╚(n©©i)╚▌ĪŻøQ▓▀śõ(sh©┤)śŗ(g©░u)įņ┐╔ęįĘųā╔▓Į▀M(j©¼n)ąąŻ║
Ą┌ę╗▓ĮŻ¼øQ▓▀śõ(sh©┤)Ą─╔·│╔Ż║ė╔ė¢(x©┤n)ŠÜśė▒Š╝»╔·│╔øQ▓▀śõ(sh©┤)Ą─▀^(gu©░)│╠ĪŻę╗░ŃŪķørŽ┬Ż¼ė¢(x©┤n)ŠÜśė▒ŠöĄ(sh©┤)ō■(j©┤)╝»╩Ūō■(j©┤)īŹ(sh©¬)ļHąĶę¬ėąÜv╩ĘĄ─Īóėąę╗Č©ŠC║Ž│╠Č╚Ą─Īóė├ė┌öĄ(sh©┤)ō■(j©┤)Ęų╬÷╠Ä└ĒĄ─öĄ(sh©┤)ō■(j©┤)╝»Ż╗
Ą┌Č■▓ĮŻ¼øQ▓▀śõ(sh©┤)Ą─╝¶ų”Ż║øQ▓▀śõ(sh©┤)Ą─╝¶ų”╩Ūī”(du©¼)╔Žę╗ļAČ╬╔·│╔Ą─øQ▓▀śõ(sh©┤)▀M(j©¼n)ąąÖz“×(y©żn)Ī󹯚²║═ą▐š²Ą─▀^(gu©░)│╠ĪŻų„ę¬╩Ūė├ą┬Ą─śė▒ŠöĄ(sh©┤)ō■(j©┤)╝»ū„×ķ£y(c©©)įćöĄ(sh©┤)ō■(j©┤)╝»ųąĄ─öĄ(sh©┤)ō■(j©┤)ąŻ“×(y©żn)øQ▓▀śõ(sh©┤)╔·│╔▀^(gu©░)│╠ųą«a(ch©Żn)╔·Ą─│§▓ĮęÄ(gu©®)ätŻ¼īó─Ūą®ė░ĒæŅA(y©┤)£y(c©©)£╩(zh©│n)┤_ąįĄ─Ęųų”╝¶│²ĪŻ
(1)śõ(sh©┤)ęį┤·▒Ēė¢(x©┤n)ŠÜśė▒ŠĄ─å╬éĆ(g©©)ĮY(ji©”)³c(di©Żn)ķ_(k©Īi)╩╝ĪŻ
(2)╚ń╣¹śė▒ŠČ╝į┌═¼ę╗éĆ(g©©)ŅÉŻ¼ätįōĮY(ji©”)³c(di©Żn)│╔×ķśõ(sh©┤)╚~Ż¼▓óė├įōŅÉś╦(bi©Īo)ėøĪŻ
(3)ʱätŻ¼╦ŃĘ©▀xō±ūŅėąĘųŅÉ─▄┴”Ą─ī┘ąįū„×ķøQ▓▀śõ(sh©┤)Ą─«ö(d©Īng)Ū░ĮY(ji©”)³c(di©Żn)ĪŻ
(4)Ė∙ō■(j©┤)«ö(d©Īng)Ū░øQ▓▀ĮY(ji©”)³c(di©Żn)ī┘ąį╚ĪųĄĄ─▓╗═¼Ż¼īóė¢(x©┤n)ŠÜśė▒ŠöĄ(sh©┤)ō■(j©┤)╝»äØĘų×ķ╚¶Ė╔ūė╝»ĪŻ├┐éĆ(g©©)╚ĪųĄą╬│╔ę╗éĆ(g©©)Ęųų”Ż¼ėąÄūéĆ(g©©)╚ĪųĄą╬│╔ÄūéĆ(g©©)Ęųų”ĪŻ
(5)ßśī”(du©¼)╔Žę╗▓ĮĄ├ĄĮĄ─ę╗éĆ(g©©)ūė╝»Ż¼ųžÅ═(f©┤)▀M(j©¼n)ąąŽ╚Ū░▓Į¾EŻ¼ļA╠▌ą╬│╔├┐éĆ(g©©)äØĘųśė▒Š╔ŽĄ─øQ▓▀śõ(sh©┤)ĪŻ├┐«ö(d©Īng)─│éĆ(g©©)ī┘ąį│÷¼F(xi©żn)į┌ĮY(ji©”)³c(di©Żn)╔ŽĄ─Ģr(sh©¬)║“Ż¼į┌įōĮY(ji©”)³c(di©Żn)╔ŽŠ═▓╗ąĶę¬ū÷║¾└m(x©┤)┐╝æ]┴╦ĪŻ
(6)ļA╠▌äØĘų▓Į¾EāH«ö(d©Īng)Ž┬┴ąŚl╝■ų«ę╗░l(f©Ī)╔·Ģr(sh©¬)═Żų╣Ż║
ó┘ĮoČ©ĮY(ji©”)³c(di©Żn)Ą─╦∙ėąśė▒Šī┘ė┌═¼ę╗ŅÉĪŻ
ó┌«ö(d©Īng)╩ŻėÓī┘ąį¤o(w©▓)Ę©┐╔ęįė├ū÷▀M(j©¼n)ę╗▓ĮäØĘųśė▒ŠĪŻ
┤╦Ģr(sh©¬)ąĶę¬╩╣ė├ČÓöĄ(sh©┤)▒ĒøQŻ¼░čĮoČ©Ą─ĮY(ji©”)³c(di©Żn)▐D(zhu©Żn)ōQ│╔śõ(sh©┤)╚~Ż¼▓óęįśė▒Šųąį¬ĮMéĆ(g©©)öĄ(sh©┤)ūŅČÓĄ─ŅÉäeū„×ķŅÉäeś╦(bi©Īo)ėøŻ¼═¼Ģr(sh©¬)ę▓┐╔ęį┤µĘ┼įōĮY(ji©”)³c(di©Żn)śė▒ŠĄ─ŅÉäeĘų▓╝ĪŻ
ó█╚ń╣¹─│ę╗Ęųų”test-attributeŻĮa*ø](m©”i)ėąśė▒ŠŻ¼ätęįśė▒ŠĄ─ČÓöĄ(sh©┤)ŅÉäō(chu©żng)Į©ę╗éĆ(g©©)śõ(sh©┤)╚~ĪŻ
3 öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)į┌īŹ(sh©¬)ļHųąĄ─æ¬(y©®ng)ė├Ī¬Ī¬ęį┐═æ¶ĻP(gu©Īn)ŽĄŽĄĮy(t©»ng)×ķ└²
į┌Ėé(j©¼ng)ĀÄ(zh©źng)╚½Ū“╗»Ą─Łh(hu©ón)Š│Ž┬Ż¼ą┼Žó╗»└╦│▒═Ųäė(d©░ng)┴╦äė(d©░ng)æB(t©żi)┬ō(li©ón)├╦Ą─╔·«a(ch©Żn)Ż¼ę▓═¼Ģr(sh©¬)Ė─ūā┴╦Ėé(j©¼ng)ĀÄ(zh©źng)ĘĮ╩ĮŻ¼ī¦(d©Żo)ų┬Ėé(j©¼ng)ĀÄ(zh©źng)▓╗į┘╩Ūå╬ę╗Ų¾śI(y©©)Ą─Ėé(j©¼ng)ĀÄ(zh©źng)Ż¼Č°╩Ūš¹éĆ(g©©)╣®æ¬(y©®ng)µ£Ą─Ėé(j©¼ng)ĀÄ(zh©źng)ĪŻ▀@ę¬Ū¾é„Įy(t©»ng)╣▄└Ē─Ż╩ĮŽ“╣®æ¬(y©®ng)µ£╣▄└ĒĘĮ╩ĮĄ─▐D(zhu©Żn)ūāĪŻį┌▀BµiĄĻĄ─Ė„Ų¾śI(y©©)╣®æ¬(y©®ng)╩Ūę╗éĆ(g©©)└¹ęµ╣▓═¼¾wŻ¼ęčĮø(j©®ng)«ö(d©Īng)═©▀^(gu©░)ā×(y©Łu)ä┘┴ė╠Ł║═ģf(xi©”)═¼ą¦æ¬(y©®ng)▓╗─▄╔·«a(ch©Żn)ā×(y©Łu)ä▌(sh©¼)Ų¾śI(y©©)Ą─¬Ü(d©▓)┴óąįŻ¼ę▓╩╣Ą├ā╔╝ęÅ─═©▀^(gu©░)ļpĘĮĮ©┴ó║Žū„╗’░ķĻP(gu©Īn)ŽĄ╠ßĖ▀╔·«a(ch©Żn)┴”Ż¼╣Ø(ji©”)╝s┘Yį┤Ż¼ęįĮĄĄ═│╔▒ŠŻ¼½@Ą├ą¦ęµŻ¼═¼Ģr(sh©¬)äō(chu©żng)įņĖ³┤¾Ą─┐═æ¶ār(ji©ż)ųĄĪŻ▀@ę▓øQČ©┴╦┐═æ¶ĻP(gu©Īn)ŽĄ╩ŪŲ¾śI(y©©)Ą─ųžę¬øQČ©Ż¼╚ń║╬▀M(j©¼n)ąą┼┼ą“╣▄└ĒĪó║Y▀x┐═æ¶ĻP(gu©Īn)ŽĄī”(du©¼)Ų¾śI(y©©)Ą─ĮĪ┐Ą░l(f©Ī)š╣ėąųžę¬ęŌ┴xĪŻ
3.1 ęįöĄ(sh©┤)ō■(j©┤)═┌Š“?y©żn)ķ║╦ą─Ą─ŽĄĮy(t©»ng)╝▄śŗ(g©░u)
öĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūę╗éĆ(g©©)ĘŪ│ŻÅ═(f©┤)ļsĄ─▀^(gu©░)│╠ĪŻ├┐éĆ(g©©)ŅÉą═Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)Č╝ėąūį╝║Ą─╠ž³c(di©Żn)┼cīŹ(sh©¬)¼F(xi©żn)ĘĮĘ©Ż¼▌ö╚ļ▌ö│÷öĄ(sh©┤)ō■(j©┤)Ą─ą╬╩Įę¬Ū¾ĪóĮY(ji©”)śŗ(g©░u)ĪóģóöĄ(sh©┤)įO(sh©©)ų├Īó┼Óė¢(x©┤n)Īó£y(c©©)įć║═─Żą═įu(p©¬ng)ār(ji©ż)ĘĮĘ©Ą╚Č╝ėą▓╗═¼ę¬Ū¾Ż¼Ęųäeįō╦ŃĘ©Ą─æ¬(y©®ng)ė├│╠ą“ė“Ą─ęŌ┴x║═─▄┴”ę▓ėą▓Ņ«ÉĪŻöĄ(sh©┤)ō■(j©┤)═┌Š“║═Š▀¾w▀mė├å¢(w©©n)Ņ}├▄ŪąŽÓĻP(gu©Īn)Ą─Ż¼├┐éĆ(g©©)öĄ(sh©┤)ō■(j©┤)═┌Š“å¢(w©©n)Ņ}Ą─æ¬(y©®ng)ė├│╠ą“▒žĒÜīŹ(sh©¬)¼F(xi©żn)Ą──┐ś╦(bi©Īo)Ż¼öĄ(sh©┤)ō■(j©┤)╩š╝»═Ļš¹│╠Č╚Ż¼å¢(w©©n)Ņ}ŅI(l©½ng)ė“?q©▒)Ż╝ęĄ─ų¦│ų│╠Č╚Ż¼Ą╚Ą╚╦ŃĘ©Ą─▀xō±ø](m©”i)ėą╚╬║╬╣▓═¼ų«╠ÄĪŻ
ßśī”(du©¼)┐═æ¶ą┼Žó▀M(j©¼n)ąą═┌Š“Ż¼ąĶę¬Į©┴óøQ▓▀śõ(sh©┤)Ż¼╚╗║¾ī”(du©¼)┐═æ¶ųžę¬ąįū÷│÷┼ąäeŻ¼ūŅ║¾ųĖī¦(d©Żo)╣½╦ŠøQ▓▀ĪŻ¼F(xi©żn)▓╔ė├ęįŽ┬Ą─┴„│╠üĒ(l©ói)Į©┴óøQ▓▀śõ(sh©┤)Ą──Żą═Ż¼╚ńłD2╦∙╩ŠĪŻ
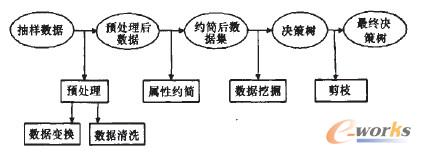
łD2 øQ▓▀śõ(sh©┤)Į©─Ż┴„│╠łD
3.2 ŽĄĮy(t©»ng)öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Ą─įO(sh©©)ėŗ(j©¼)┼cīŹ(sh©¬)¼F(xi©żn)
3.2.1 öĄ(sh©┤)ō■(j©┤)Ą─▀xō±
═┌Š“║¾┤_Č©Ą──┐ś╦(bi©Īo)Ż¼▒žĒÜī”(du©¼)öĄ(sh©┤)ō■(j©┤)═┌Š“ū÷│÷£╩(zh©│n)éõĪŻöĄ(sh©┤)ō■(j©┤)ąą×ķĄ─ųŲéõĖ∙ō■(j©┤)ąĶŪ¾Ą─═┌Š“Ż¼╩š╝»öĄ(sh©┤)ō■(j©┤)Ż¼▓óĮ©┴ó┴╦öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼┴╝║├Ą─┐╔░l(f©Ī)Š“ĪŻöĄ(sh©┤)ō■(j©┤)š╝ė├Ą─ųŲéõį┌š¹éĆ(g©©)öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠ųąŻ¼ęÄ(gu©®)─ŻūŅ┤¾Ą─ę╗┤╬ĪŻį┌▀xō±öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Å─SQL senrerĄ─┐═æ¶ą┼Žóū└Ū░▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ī”(du©¼)Ž¾ĪŻį┌┐═æ¶ą┼Žó▒Ēųąėą┤¾┴┐Ą─┐═æ¶ą┼ŽóŻ¼▀xō±▓┐ĘųįŁ╩╝öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)═┌Š“ĪŻ┐═æ¶ą┼Žó▒Ēųą░³║¼Ą─ī┘ąįŻ¼╚ń▒Ē1╦∙╩ŠĪŻ
▒Ē1 ┐═æ¶ą┼Žóī┘ąį▒Ē
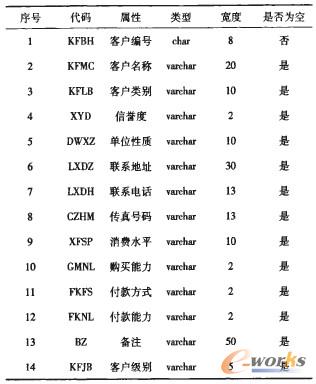
ŲõųąŻ¼┐═æ¶ŅÉäeĄ─╚ĪųĄ×ķŻ║{éĆ(g©©)╚╦Ż¼łF(tu©ón)¾w}Ż╗ą┼ūu(y©┤)Č╚Ą─╚ĪųĄ×ķŻ║{Ė▀Ż¼ę╗░Ń}Ż╗Ž¹┘M(f©©i)╦«ŲĮĄ─╚ĪųĄ×ķŻ║{Ė▀Ż¼ųąŻ¼Ą═}Ż╗┘Å(g©░u)┘I─▄┴”Ą─╚ĪųĄ×ķŻ║{ÅŖ(qi©óng)Ż¼ę╗░ŃŻ¼▓Ņ}Ż╗ĖČ┐ŅĘĮ╩ĮĄ─╚ĪųĄ×ķŻ║{¼F(xi©żn)ĮŻ¼ģRĖČŻ¼▒ŠŲ▒Ż¼ų¦Ų▒Ż¼Ųõ╦¹}Ż╗ĖČ┐Ņ─▄┴”Ą─╚ĪųĄ×ķŻ║{░┤Ģr(sh©¬)Ż¼═Ų▀t}Ż╗å╬╬╗ąį┘|(zh©¼)Ą─╚ĪųĄ×ķŻ║{ć°(gu©«)ėąŻ¼╦ĮĀI(y©¬ng)Ż¼éĆ(g©©)¾w}┐═æ¶╝ē(j©¬)äeĄ─╚ĪųĄ×ķŻ║{vipŻ¼Ųš═©Ż¼▓╗ųžę¬}ĪŻ
3.2.2 öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ē
öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ēį┌öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠ųą╩Ūę╗éĆ(g©©)ųžę¬▓Į¾EŻ¼ė╚Ųõ╩Ūį┌ī”(du©¼)░³║¼ėąįļ궯¼▓╗═Ļ╚½Ż¼╔§ų┴╩Ū▓╗ę╗ų┬Ą─öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)═┌Š“Ż¼ąĶę¬ī”(du©¼)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąŅA(y©┤)╠Ä└ĒŻ¼╠ßĖ▀öĄ(sh©┤)ō■(j©┤)═┌Š“?q©▒)”Ž¾║═ö?sh©┤)ō■(j©┤)═┌Š“ØMłD░ĖĄ─┘|(zh©¼)┴┐ĪŻöĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ē╝╝ąg(sh©┤)Ą─╝╝ąg(sh©┤)║═öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQĄ╚Ż¼öĄ(sh©┤)ō■(j©┤)ŪÕ└ĒŻ¼öĄ(sh©┤)ō■(j©┤)╝»│╔Ż¼öĄ(sh©┤)ō■(j©┤)šµīŹ(sh©¬)│÷╩█║═┘Å(g©░u)┘I░Ż╦╣╔w╠žį┌═¼ę╗éĆ(g©©)╝ę═źĪŻŅA(y©┤)╠Ä└Ē║¾Ż¼┐╔ęį╠ßĖ▀öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©Ą─Š½Č╚║═ėąą¦ąįŻ¼▓ó▒Ż┤µöĄ(sh©┤)ō■(j©┤)╠Ä└ĒĄ─Ģr(sh©¬)ķgĪŻį┌┐═æ¶ĻP(gu©Īn)ŽĄ╣▄└ĒŽĄĮy(t©»ng)Ą─╠ž³c(di©Żn)šJ(r©©n)×ķŻ¼¼F(xi©żn)╠ß│÷ęįŽ┬łD3Ą─öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ē─Żą═ĪŻ▀x╚Ī┐═æ¶ą┼Žó▒Ē500ČÓéĆ(g©©)śė▒Šū„×ķ蹊┐Ą─ī”(du©¼)Ž¾Ż¼▓óį┌▀@ą®įŁ╩╝Ą─┐═æ¶öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąŅA(y©┤)╠Ä└ĒĪŻ
łD3 öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ē
(1)öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQŻ¼╬ęéā▒žĒÜ└^└m(x©┤)Š═▓╗öÓļx╔óī┘ąįĄ─╠Ä└ĒĪŻ▀@éĆ(g©©)īŹ(sh©¬)“×(y©żn)╔µ╝░Ą─▓╗öÓī┘ąįĪ¬Ī¬Ž¹┘M(f©©i)╦«ŲĮĄ─ĒŚ(xi©żng)─┐Ż¼Įø(j©®ng)▀^(gu©░)Ęų╬÷Ż¼╬ęéāīóŲõå╬¬Ü(d©▓)Ą─ūā╗»(0Ż¼50╚f(w©żn))Ż║Ą═Ż¼(50╚f(w©żn)Ż¼100╚f(w©żn))Ż║(100╚f(w©żn))Ż║Ė▀ĪŻ▀`ęÄ(gu©®)╝sŅA(y©┤)╠Ä└Ē╩Ū▀^(gu©░)│╠ųąĄ─ųžę¬▓Į¾EŻ¼Ųõ─┐Ą─╩ŪŽ¹│²ę╗ą®═┌Š“ø](m©”i)ėąęŌ┴xĄ─ī┘ąįĪŻį┌ČÓöĄ(sh©┤)ŪķørŽ┬Ż¼╬ęéā▀xō±═┌Š“?q©▒)┘ąį▓╗║├Ż¼ī?du©¼)╬ęéāĄ─═┌Š“Ż¼į┌═┌Š“Ģr(sh©¬)Ż¼▀M(j©¼n)ąąÄ═ų·Ż¼╬ęéāę¬░┤šš▓╗═¼Ą─öĄ(sh©┤)ō■(j©┤)ŪķørŻ¼ėąĻP(gu©Īn)ė┌┐═æ¶ą┼Žó▒ĒŻ¼└²╚ń▀xō±ų«Ū░Ż¼æ¬(y©®ng)▀M(j©¼n)ąąĄ─ŠS╬ßĀ¢ūÕŚl┐Ņę╗░ŃęįŽ¹│²ŅI(l©½ng)ė“Ą─Ą┌ę╗┤╬║═┐═æ¶Ą─ą“┴ą╠¢(h©żo)Ą╚Ż¼┐═æ¶ąš├¹Ż¼ĄžųĘŻ¼ļŖįÆŻ¼é„šµ╠¢(h©żo)┤aŻ¼šł(q©½ng)ūóęŌŻ¼ę“?y©żn)ķ▀@ą®ą┼Žó┐╔─▄ø](m©”i)ėąĄĮöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ęŌ┴xĪŻ
(2)öĄ(sh©┤)ō■(j©┤)ŪÕ└ĒŻ¼į┌ų«Ū░Ą─öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą┴╦═┌Š“Ż¼ąĶę¬▀M(j©¼n)ąąĖ╔ā¶Ą─Ą┌ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)ĪŻ═©▀^(gu©░)┐═æ¶ĻP(gu©Īn)ŽĄŽĄĮy(t©»ng)Ą─╚š│Ż▀\(y©┤n)ū„░l(f©Ī)¼F(xi©żn)Ż¼į┌öĄ(sh©┤)ō■(j©┤)▒Ē┤µį┌Ą─┐š╚▒║═öĄ(sh©┤)ō■(j©┤)Å═(f©┤)ųŲĄ─ār(ji©ż)ųĄĪŻ═©│ŻĻP(gu©Īn)ė┌┐š╚▒ųĄöĄ(sh©┤)ō■(j©┤)Ż¼╦³╩╣ė├Ą─╠Ä└ĒĘĮĘ©░³└©Ż║║÷┬įąąĪó╚╦╣ż╠Ņīæ(xi©¦)┐š╚▒ųĄĪóŲĮŠ∙ųĄĘ©Ą╚ĪŻ
3.2.3 öĄ(sh©┤)ō■(j©┤)Į©─Ż
ė├øQ▓▀śõ(sh©┤)┴„│╠▀M(j©¼n)ąąĮ©─ŻŻ¼øQ▓▀śõ(sh©┤)╔·│╔╦ŃĘ©├Ķ╩÷╚ńŽ┬Ż║

ī”(du©¼)įŁ╩╝öĄ(sh©┤)ō■(j©┤)Įø(j©®ng)▀^(gu©░)ŅA(y©┤)╠Ä└ĒŻ¼│ķ╚ĪŲõųą▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)═┌Š“Ż¼Ą├ĄĮŚl╝■ī┘ąį╝»║ŽC={ą┼ūu(y©┤)Č╚Ż¼Ž¹┘M(f©©i)╦«ŲĮŻ¼┘Å(g©░u)┘I─▄┴”Ż¼┘Å(g©░u)┘I─▄┴”Ż¼ĖČ┐Ņ─▄┴”Ż¼å╬╬╗ąį┘|(zh©¼)Ż¼┐═æ¶ŅÉäe}Ż¼øQ▓▀ī┘ąį╝»║ŽD={┐═æ¶╝ē(j©¬)äe}ĪŻ
Įø(j©®ng)▀^(gu©░)╗∙ė┌ą┼Žóį÷굥─ID3╦ŃĘ©śŗ(g©░u)Į©øQ▓▀śõ(sh©┤)Ż¼╬ęéāĄ├ĄĮ╚ńłD4Ą─øQ▓▀śõ(sh©┤)ĮY(ji©”)╣¹Ż║
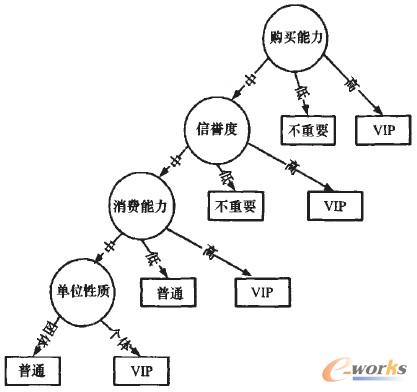
łD4 │§▓Į?j©®ng)Q▓▀śõ(sh©┤)
3.2.4 öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─īŹ(sh©¬)¼F(xi©żn)
į┌Analysis SenricesųąįO(sh©©)ų├īóę¬ė¢(x©┤n)ŠÜöĄ(sh©┤)ō■(j©┤)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“─Żą═ĪŻ╚╗║¾╩╣ė├┐═æ¶Č╦╣żŠ▀ī”(du©¼)╩▄ė¢(x©┤n)öĄ(sh©┤)ō■(j©┤)▀\(y©┤n)ąąĖ▀╝ē(j©¬)Ęų╬÷Ż¼äō(chu©żng)Į©öĄ(sh©┤)ō■(j©┤)═┌Š“─Żą═Ą─▓Į¾E╚ńŽ┬Ż║
(1)į┌Ī░┐═æ¶Ęų╬÷Ī▒śõ(sh©┤)┤░Ė±ųąėęō¶Ī░═┌Š“─Żą═Ī▒╬─╝■ŖAŻ¼╚╗║¾▀xō±Ī░ą┬Į©═┌Š“─Żą═Ī▒ĪŻ
(2)┤“ķ_(k©Īi)═┌Š“─Żą═Ž“?q©▒)¦Ż¼į┌Ī░ÜgėŁ╩╣ė├═┌Š“─Żą═Ž“?q©▒)¦Ī▒ųąŻ¼▀xō±Ī░Ž┬ę╗▓ĮĪ▒ĪŻ
(3)į┌Ī░▀xō±į┤ŅÉą═Ī▒ųąŻ¼▀xō±Ī░ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Ī▒ĪŻ╚╗║¾Ī░Ž┬ę╗▓ĮĪ▒ĪŻ
(4)į┌Ī░▀xō±╩┬└²▒ĒĪ▒ųąŻ¼▀xō±Ī░å╬éĆ(g©©)▒Ē░³║¼öĄ(sh©┤)ō■(j©┤)Ī▒Ż¼į┌Ī░┐╔ė├Ą─▒ĒĪ▒ųą▀xĪ░┐═æ¶Ęų╬÷Ī▒Ż¼╚╗║¾▀xō±Ī░Ž┬ę╗▓ĮĪ▒ĪŻ
(5)į┌Ī░▀xō±öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)Ī▒ųą▀xō±Ī░╝╝ąg(sh©┤)Ī▒ųąĄ─Ī░MicmsoftøQ▓▀śõ(sh©┤)Ī▒Ż¼╚╗║¾▀xō±Ī░Ž┬ę╗▓ĮĪ▒ĪŻ
(6)į┌Ī░▀xō±µI┴ąĪ▒ųą▀xō±Ī░╩┬└²µI┴ąĪ▒ųąĄ─Ī░IDĪ▒Ż¼╚╗║¾▀xĪ░Ž┬ę╗▓ĮĪ▒ĪŻ
(7)į┌Ī░▀xō±▌ö╚ļ┼c┐╔ŅA(y©┤)£y(c©©)┴ąĪ▒ųą▀xō±Ī░ųžę¬ąįĘų╬÷Ī▒Ż¼╚╗║¾ė├Ī░>Ī▒░┤ŌoęŲäė(d©░ng)ĄĮĪ░┐╔ŅA(y©┤)£y(c©©)┴ąĪ▒┐“ųąĪŻ
(8)▀@ą®┴ą▀Ćīóė├ū„▌ö╚ļ┴ąĪŻ▀xō±Ī░å╬╬╗ąį┘|(zh©¼)Ī▒ĪóĪ░┘Å(g©░u)┘I─▄┴”Ī▒ĪóĪ░ą┼ūu(y©┤)Č╚Ī▒ĪóĪ░ĖČ┐Ņ─▄┴”Ī▒ĪóĪ░ĖČ┐ŅĘĮ╩ĮĪ▒║═Ī░┬ō(li©ón)ŽĄļŖįÆĪ▒Ż¼▓ó═©▀^(gu©░)Ī░▌ö╚ļ┴ąĪ▒┴ą▒Ē┼į▀ģĄ─Ī░>Ī▒░┤ŌoīóŲõęŲäė(d©░ng)ĄĮĪ░▌ö╚ļ┴ąĪ▒┐“ųąĪŻå╬ō¶Ī░Ž┬ę╗▓ĮĪ▒░┤ćĪŻ
(9)ūŅ║¾į┌Ī░─Żą═├¹ĘQĪ▒┐“ųą▌ö╚ļĪ░ųžę¬┐═æ¶ŅA(y©┤)£y(c©©)Ī▒ĪŻ┤_▒Ż▀xō±┴╦Ī░▒Ż┤µ▓ó┴ó╝┤╠Ä└ĒĪ▒Ż¼╚╗║¾Ī░═Ļ│╔Ī▒ĪŻ
(10)│÷¼F(xi©żn)Ī░╠Ä└ĒĪ▒┤░┐┌Ż¼’@╩Šš²į┌╠Ä└ĒĄ──Żą═ĪŻ╠Ä└Ē═Ļ│╔ų«║¾│÷¼F(xi©żn)ę╗ätŽ¹ŽóŻ¼šf(shu©Ł)├„Ī░ęč│╔╣”═Ļ│╔╠Ä└ĒĪ▒Ż¼▀xō±Ī░ĻP(gu©Īn)ķ]Ī▒ĪŻ
Ž┬├µ╩╣ė├┤·┤a═©▀^(gu©░)DSO╚źäō(chu©żng)Į©┴╦ę╗éĆ(g©©)ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)═┌Š“─Żą═ĪŻ




4 ╦ŃĘ©įu(p©¬ng)╣└
▒ŠčąŠ┐▓╔ė├UCI╣½╣▓öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ųąĄ─3éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)üĒ(l©ói)▀M(j©¼n)ąąĘ┬šµįć“×(y©żn)Ż¼▓óīó▒ŠčąŠ┐ųą╠ß│÷Ą─øQ▓▀śõ(sh©┤)╦ŃĘ©Ą├│÷Ą─ĮY(ji©”)╣¹║═C4.5╦ŃĘ©ŽÓæ¬(y©®ng)ĮY(ji©”)╣¹▀M(j©¼n)ąą▒╚▌^ĪŻ▒Ē2×ķöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─╗∙▒Šą┼ŽóŻ║
▒Ē2 öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╗∙▒Šą┼Žó

▒Ē3 įć“×(y©żn)ĮY(ji©”)╣¹
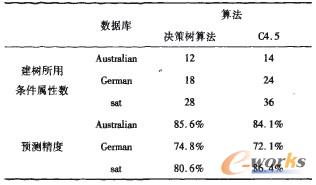
═©▀^(gu©░)ī”(du©¼)▒╚░l(f©Ī)¼F(xi©żn)øQ▓▀śõ(sh©┤)╦ŃĘ©├„’@£p╔┘┴╦Į©┴óøQ▓▀śõ(sh©┤)╦∙ė├Ą─ī┘ąįéĆ(g©©)öĄ(sh©┤)Ż¼øQ▓▀śõ(sh©┤)Ą─ėŗ(j©¼)╦Ń│╔▒Šš²▒╚ė┌Į©śõ(sh©┤)╦∙ė├ī┘ąįéĆ(g©©)öĄ(sh©┤)Ż¼ę“┤╦Ż¼▒Š╬─╠ß│÷Ą─╦ŃĘ©├„’@£p╔┘┴╦ėŗ(j©¼)╦Ń│╔▒ŠĪŻ═¼Ģr(sh©¬)Ż¼ė╔ė┌╦ŃĘ©Å═(f©┤)ļsČ╚▌^ąĪŻ¼śŗ(g©░u)Į©øQ▓▀śõ(sh©┤)Ą─ą¦┬╩ę▓īóėą╦∙╠ßĖ▀ĪŻīŹ(sh©¬)“×(y©żn)▒Ē├„Ż¼į┌Į©śõ(sh©┤)ęÄ(gu©®)─ŻŽÓ«ö(d©Īng)?sh©┤)─ŪķørŽ┬Ż¼▒ŠøQ▓▀śõ(sh©┤)╦ŃĘ©Ą─ŅA(y©┤)£y(c©©)Š½Č╚▒╚C4.5ėą╦∙╠ßĖ▀ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.vmgcyvh.cn/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╗∙ė┌øQ▓▀śõ(sh©┤)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©Ą─æ¬(y©®ng)ė├┼c蹊┐
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.vmgcyvh.cn/html/consultation/1083934857.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å(g©░u)┘I")
æ(zh©żn)┬į║Žū„")