Å─╦─éĆĘĮ├µ║═┤¾╝ęĮ╗┴„ę╗Ž┬Ż║įŲėŗ╦Ń┼c┤¾öĄō■Ż¼įŲ╔Ž┤¾öĄō■ŲĮ┼_Į©įOĄ─╠¶æŻ¼┤¾öĄō■╗∙ĄAŲĮ┼_Ż¼öĄō■Ė±╩ĮĪŻ
ę╗ĪóįŲėŗ╦Ń┼c┤¾öĄō■
ŽÓą┼┤¾╝ęŲĮĢrĮėė|Ė³ČÓĄ─╩Ū╬’└ĒÖCĘĮ░ĖĄ─┤¾öĄō■Ż¼▒ŠüĒ▀@éĆįÆŅ}╬ę▓ó▓╗Žļ┐éųvŻ¼ę“×ķį┌╬ęéā┐┤üĒ┤¾öĄō■Ą─░lš╣ĘĮŽ“╩ŪįŲ╗»║═ķ_į┤Ż¼╩Ūę╗éĆĒś└Ē│╔š┬Ą─╩┬ŪķŻ¼Ą½╩Ūį┌īŹļHīŹ╩®ųąĢ■ė÷ĄĮę╗ą®ūĶ┴”Ż¼▀@╩Ūę“×ķ╬ęéāėąŽÓ«öę╗▓┐Ęų╚╦▀Ć╩Ū╬’└ĒÖC╩└Įńū÷┤¾öĄō■Ą─╦╝ŠSŻ¼▀Ćėąī”įŲėŗ╦ŃĄ─▓╗ą┼╚╬Ż¼╔į╬óėą’L┤Ą▓▌äėŠ═æčę╔įŲėŗ╦ŃŻ¼▀@’@╚╗╩Ū▓╗ī”Ą─ĪŻæčę╔┤¾öĄō■įŲ╗»¤o═Ō║§Š═╩ŪĘĆČ©ąį║═ąį─▄Ż¼▓╗▀^║├Ž¹Žó╩ŪįĮüĒįĮČÓĄ─╚╦ęčĮøęŌūRĄĮę▓šJ┐╔▀@éĆ░lš╣ĘĮŽ“Ż¼ŽÓą┼ęį║¾▀@Š═▓╗į┘╩ŪéĆįÆŅ}┴╦ĪŻ
╬ęéā▀Ć╩ŪÅ─┤¾öĄō■▒Š╔Ē│÷░lĪŻ╬ęéāį┌£╩éõū÷ę╗éĆ┤¾öĄō■ĒŚ─┐Ą─Ģr║“Ż¼╩ūŽ╚╩Ū┤_Č©ąĶŪ¾Ż¼╚╗║¾Š═╩ŪŲĮ┼_Ą─▀xą═Ż¼ŲĮ┼_Ą─▀xą═╩Ūę╗éĆūŅļyĪóūŅųžę¬Ą─Īóę▓╩Ū┤¾╝ęūŅ└¦╗¾Ą─Łh╣ØŻ¼╬ęė÷ĄĮĄ─┐═æ¶╗∙▒Š╔ŽČ╝į┌▀@éĆå¢Ņ}╔Žėą▓╗═¼│╠Č╚Ą─╝mĮYŻ¼▀@éĆ═Ļ╚½┐╔ęį└ĒĮŌŻ¼ę“×ķ¢|╬„╠½ČÓ┴╦Ż¼▓óŪę▀ĆėąĖ³ČÓĄ─ą┬¢|╬„į┤į┤Ąž▓╗öÓĄž│÷üĒĪŻ
ŲõīŹŲĮ┼_Ą─▀xą══Ļ╚½╚ĪøQė┌─ŃĄ─ąĶŪ¾Ż¼─Ń╩ŪīŹĢrėŗ╦Ń▀Ć╩ŪļxŠĆėŗ╦ŃŻ¼╩Ū╠Ä└ĒĮYśŗ╗»öĄō■▀Ć╩ŪĘŪĮYśŗ╗»öĄō■Ż¼─ŃĄ─æ¬ė├ėąø]ėą╩┬äšąįę¬Ū¾Ą╚Ą╚ĪŻ┤_Č©▀@ą®ąĶŪ¾║¾Š═šęŽÓæ¬Ą─ŲĮ┼_Š═ąą┴╦Ż¼▀@Š═ę¬Ū¾╬ęéāī”├┐éĆŲĮ┼_Ą─╠ž³cę¬┴╦ĮŌĪŻ╬ęéāų¬Ą└ø]ėąę╗éĆŲĮ┼_─▄ĮŌøQ╦∙ėąĄ─å¢Ņ}Ż¼ Spark į┘ÅŖ┤¾ę▓ø]ėą┤µā”Ż¼║▄ČÓł÷Š░ąĶę¬║═ Hadoop / HBase / ī”Ž¾┤µā”Ą╚┼õ║ŽŲüĒ╩╣ė├Ż¼Ė³äešf╠µōQöĄō■é}Äņ┴╦ĪŻ
▀xō±ŲĮ┼_╗“╣żŠ▀▓╗─▄┌sĢr„ųŻ¼▀mė├▓┼╩ŪūŅš²┤_Ą─Ż¼ėąą®¢|╬„▓óę╗Č©Š═ų╗ėą Hadoop ╗“ Spark ▓┼─▄ĮŌøQŻ¼▒╚╚ń redis ╠ß╣®┴╦ę╗éĆ║▄║├Ą─öĄō■ĮYśŗ hyperloglogs ė├üĒĮyėŗ¬Ü┴ó╩┬╝■Ż¼Č°ā╚┤µūŅČÓų╗Ģ■ė├ĄĮ 12k ūų╣ØŻ¼Ė·ČÓ╔┘éƬÜ┴ó╩┬╝■¤oĻPŻ¼š`▓Ņ▓╗│¼▀^ 1 % Ż¼─Ū├┤ė├▀@éĆüĒĮyėŗ├┐éĆĢrČ╬Ą─¬Ü┴ó╩┬Ūķ▒╚╚ń UV ▀Ć╩Ū║▄▓╗ÕeĄ─▀xō±ĪŻ
├┐éĆŲĮ┼_ėąūį╝║╠žČ©Ą─╩╣ė├ł÷Š░Ż¼╬ęéā▓╗Ą½ę¬┴╦ĮŌ╦³Ż¼╔§ų┴║▄ČÓĢr║“╬ęéā▀ĆĢ■ī”Ė„éĆ║“▀xŲĮ┼_ū÷éĆ POC ╗“ benchmark £yįćŻ¼▀@éĆĢr║“įŲėŗ╦ŃŠ═¾w¼F│÷ā×ä▌┴╦Ż¼─Ń┐╔ęį┐ņ╦┘ĄžĪóĄ═│╔▒ŠĄžū÷įć“×ĪŻ
«ö╚╗įŲėŗ╦ŃĄ─ā×ä▌▓╗āHāH▀@ą®Ż¼┤¾öĄō■Ģr┤·ėą║▄ČÓ▓╗┤_Č©ąįĄ─¢|╬„Ż¼─▄ē“šf│÷░ļ─Ļų«║¾─ŃĄ─öĄō■┴┐ę╗Č©Ģ■į÷╝ėĄĮČÓ╔┘Ą─╚╦▓╗Ģ■╠½ČÓŻ¼įŲėŗ╦ŃĄ─ÅŚąį─▄║▄║├ĄžĮŌøQ▀@éĆå¢Ņ}Ż¼ąĶę¬ČÓ╔┘Š═į÷╝ėČÓ╔┘┘Yį┤Ż¼▀Ć─▄ßīĘ┼▀^╩Ż┘Yį┤ĮoŲõ╦³śIäš╩╣ė├Ż¼╔ŽŽ┬ū¾ėę╚╬ęŌĄž╔ņ┐sŻ¼▀@ą®Č╝┐╔ęį═©▀^╩¾ś╦³cō¶ÄūĘųńŖ═Ļ│╔ĪŻ─Ń╔§ų┴┐╔ęį═©▀^š{ė├ API Ą─ĘĮ╩ĮüĒ▓┘┐ž▀@ą®ŲĮ┼_Ż¼▒╚╚ńšf╬ęĄ─│╠ą“└’Įė╩šĄĮöĄō■Ż¼╬ęåóäė╬ęĄ─ Spark ╝»╚║üĒ╠Ä└Ē▀@ą®öĄō■Ż¼╠Ä└Ē═Ļų«║¾╬ę┐╔ęįĻPķ]╝»╚║Ż╗ę▓┐╔ęį═©▀^Č©ĢrŲ„╗“ūįäė╔ņ┐s╣”─▄╚ź═Ļ│╔▀@ą®╩┬ŪķŻ¼Å─Č°śO┤¾Ą─╣Ø╝s│╔▒ŠĪŻ
įŲėŗ╦Ń▓╗āHāHėąÅŚąįĪó├¶Į▌ąįŻ¼▀ĆĘŪ│Żņ`╗ŅŻ¼─Ń┐╔ęį╚╬ęŌ┤Ņ┼õę╗ą®ĮM╝■ĮM│╔▓╗═¼Ą─ĮŌøQĘĮ░ĖĪŻ▒╚╚ń╬ęéā¼Fį┌ę¬ū÷Ą─ę╗╝■╩┬ŪķŠ═╩Ū╗∙ė┌öĄō■╚╬ęŌŪąōQėŗ╦Ńę²ŪµŻ¼ę“×ķ╬ęéāų¬Ą└┤¾öĄō■╩Ūėŗ╦ŃĖ·ų°öĄō■ū▀Ż¼öĄō■į┌─Ūā║Ż¼ėŗ╦Ń┼▄ĄĮ─Ūā║Ż¼─Ū├┤ėąĄ─ė├æ¶ī” MapReduce ▒╚▌^╩ņŽżŻ¼╦¹┐╔─▄Š═╩Ūė├Ą─ Hadoop Ż¼Ą½▀^Č╬Ģrķg╦¹Žļė├ Spark ┴╦Ż¼▀@éĆĢr║“▓╗─▄ūīė├æ¶╚ź┐ĮžÉöĄō■ĄĮSpark╝»╚║Ż¼Č°æ¬įō╩ŪōQĄ¶╔Ž├µĄ─ MapReduce ūā│╔ Spark Ż¼öĄō■▀Ć╩ŪįŁüĒĄ─ HDFS ĪŻ╦∙ėąĄ─▀@ą®Č╝─▄Ä═╬ęéā░čĢrķg║═Š½┴”Ę┼į┌śIäšīė├µŻ¼Č°▓╗╩Ū╚źĄ╣“vÅ═ļsĄ─┤¾öĄō■ŲĮ┼_ĪŻ
Č■ĪóįŲ╔Ž┤¾öĄō■ŲĮ┼_Į©įOĄ─╠¶æ
┐╔ęį┐┤│÷įŲ╔ŽĄ─┤¾öĄō■─▄Įo╬ęéāĦüĒ¤o┼céÉ▒╚Ą─¾w“ׯ¼Ą½╩ŪįŲ╔Ž┤¾öĄō■ūŅĻPµIĄ─▓ó▓╗╩Ū▀@ą®¢|╬„Ż¼Č°╩ŪĘĆČ©ąį║═ąį─▄Ż¼▀@ę▓╩Ūæčę╔┤¾öĄō■įŲ╗»ūŅų„ꬥ─ā╔³cĪŻČ°▀@ā╔³c╦∙ę└┘ćĄ─╩Ū IaaS Ą──▄┴”Ż¼┐╝“×─ŃĄ─╩Ū╠ōöM╗»Ą─╝╝ąg║├▓╗║├Ż¼▓╗─▄ē║┴”ę╗╔ŽüĒŠ═ kenel panic Ż¼▓╗▀^╬ęéā╩ŪÅ─üĒø]ė÷ĄĮ▀^▀@éĆå¢Ņ}Ż¼╦∙ęį╬ęŠ═▓╗ČÓšf▀@éĆĪŻ
ąį─▄▀@éĆå¢Ņ}┤_īŹąĶę¬╗©┤¾┴”ÜŌšfŻ¼ąį─▄Ęų┤┼▒P I/O ąį─▄║═ŠWĮjąį─▄Ż¼┤┼▒Pąį─▄╚ń╣¹Å─ŽÓ═¼┼õų├Ą─å╬╣سcüĒšfŻ¼╠ōÖC┤_īŹø]ėą╬’└ĒÖCąį─▄║├Ż¼▀@╩Ūę“×ķ╠ōöM╗»┐é╩Ūėąōp║─Ą─Ż¼Ą½╩ŪŻ¼╚ń╣¹─Ń╠ōöM╗»╝╝ągūŃē“║├Ż¼ōp║─┐╔ęįĮĄĄĮ║▄Ą═Ż¼═¼ĢrįŲėŗ╦Ń╩Ū┐┐ÖMŽ“öUš╣ĮŌøQÅ═ļså¢Ņ}Ą─Ż¼Č°▓╗╩Ū┐┐┐vŽ“öUš╣Ż¼ę╗éĆ╣سc▓╗ąą╬ęČÓ╝ėę╗éĆ╣سcĪŻ▓óŪę╬ęéā¼Fį┌ŽļĄĮ┴╦Ė³║├Ą─▐kĘ©ĮŌøQ▀@éĆå¢Ņ}Ż¼ūī┤┼▒Pąį─▄Ą├ĄĮĖ³┤¾Ą─╠ß╔²ĪŻ
ŠWĮjąį─▄į┌╬’└Ē╩└Įńę▓┤µį┌Ż¼ė╚Ųõ╩Ū╣سcę╗ČÓŻ¼╚ń╣¹ę╗▓╗ąĪą─ŠWĮj┼õų├▓╗ē“║├Ż¼ąį─▄ę╗śėĢ■▓ŅĪŻ╬ęéāūŅĮ³äé░l▓╝Ą─ SDN 2.0 Š═Ä═╬ęéāĄ─┤¾öĄō■ĮŌøQ┴╦▀@éĆ┤¾å¢Ņ}Ż¼╦∙ėąĄ─ų„ÖCų«ķgŠWĮj═©ėŹČ╝╩Ūų▒▀BŻ¼Ė·╣سcČÓ╔┘ø]ėąĻPŽĄŻ¼▓óŪę╣سcķgĦīÆ─▄▀_ĄĮ 8 Gb Ż¼ęčĮøĮėĮ³╬’└ĒŠW┐©å╬┐┌Ą─╔ŽŽ▐┴╦ĪŻørŪę¼Fį┌ 25 Gb Ą─ŠW┐©│╔▒Šę▓įĮüĒįĮĮėĮ³ 10 Gb Ą─ŠW┐©Ż¼╦∙ęįŠWĮj▓╗æ¬įō╩Ūå¢Ņ}Ż¼«ö╚╗Ū░╠ß╩Ū─ŃĄ─ SDN ╝╝ągūŃē“┼ŻĪŻ
ĻPė┌┤┼▒P I/O Ą─å¢Ņ}╬ęį┘ča│õę╗³cŻ¼╬ęéāų¬Ą└ HDFS ─¼šJĄ─Ė▒▒Šę“ūė╩Ū Ż│ Ż¼Ą½╩Ūį┌įŲ╔ŽŠ═Ģ■ūāĄ├▓╗ę╗śėŻ¼─Ń╚ń╣¹į┌ę╗╝ęįŲĘ■äš╔╠╔Žūį╝║▓┐╩ Hadoop Ż¼Š═▓╗æ¬įōįOČ© 3 éĆĖ▒▒Šę“ūėĪŻ▀@╩Ūę“×ķ Hadoop įOėŗĄ┌╚²éĆĖ▒▒ŠĄ─│§ųį╩ŪĘ└ų╣š¹éĆÖC╝▄│÷å¢Ņ}Č°░čĄ┌╚²éĆĖ▒▒ŠĘ┼į┌┴Ē═Ōę╗éĆÖC╝▄╔ŽŻ¼─Ńį┌äe╚╦╝ę▓┐╩Ą─Ģr║“─Ń┐ŽČ©▓╗ų¬Ą└▀@éĆą┼ŽóĄ─Ż¼╦∙ęįĄ┌╚²éĆĖ▒▒Š╩Ūø]ėąęŌ┴xĄ─Ż¼═¼Ģr╚╬║╬ę╗╝ę IaaS Ę■äš╔╠ę╗Č©Ģ■╠ß╣®┘Yį┤īė├µĄ─Ė▒▒ŠĄ─Ż¼öĄō■Ą─░▓╚½ąį─▄Ą├ĄĮ▒ŻšŽŻ¼╦∙ęįĖ³æ¬įō╚źĄ¶Ą┌╚²éĆĖ▒▒ŠŻ¼╚źĄ¶▀@éĆĖ▒▒Š┐╔ęį╣Ø╩Ī 1/3 Ą─┐šķgŻ¼ąį─▄▀Ć─▄Ą├ĄĮ╠ß╔²ĪŻ
Ą½╩ŪŻ¼▓╗─▄ę“×ķ IaaS ėąĖ▒▒ŠŠ═░č HDFS ĮĄĄ═ĄĮę╗éĆĖ▒▒ŠŻ¼įŁę“╩Ū─ŃąĶ꬜Iäšīė├µĄ─ HA Ż¼ IaaS Ą─Ė▒▒Šų╗─▄▒ŻūCöĄō■▓╗üGŻ¼╬’└ĒÖC│÷╣╩šŽŪąōQąĶę¬ÄūĘųńŖĄ─ĢrķgŻ¼╚ń╣¹ HDFS ų╗ėąę╗éĆĖ▒▒ŠĄ─įÆ▀@éĆŪąōQ▀^│╠śIäšĢ■╩▄ė░ĒæŻ¼╦∙ęį 2 éĆĖ▒▒Š▀Ć╩Ū▒žĒÜĄ─ĪŻ╝┤▒Ń▀@śėŲõīŹ▀Ć▓╗╩ŪūŅāץ─ĘĮ░ĖŻ¼ę“×ķśIäšīė 2 éĆĖ▒▒Š╝ė╔Ž IaaS īėų┴╔┘ 2 éĆĖ▒▒ŠŻ¼╝ėŲüĒŠ═ų┴╔┘ 4 éĆĖ▒▒Š┴╦Ż¼▒╚╬’└ĒÖCĘĮ░ĖĄ─ 3 éĆĖ▒▒Š▀Ć╩Ūėą▓ŅŠÓĪŻ╦∙ęįūŅ║├Š═╩Ū╚źĄ¶ĄūīėĄ─Ė▒▒ŠŻ¼į┌įŲ╔ŽīŹ¼F╬’└ĒÖC╩└ĮńĄ─ 3 éĆĖ▒▒ŠĘĮ░ĖŻ¼╚╗║¾╝ė╔Ž Rack awareness Ż¼▀@éĆŠ═Ė·╬’└ĒÖC▓┐╩ę╗śė┴╦Ż¼Ą½╩Ū╩ŪęįįŲĄ─ĘĮ╩ĮĮ╗ĖČĮo┤¾╝ęĪŻ▀@éĆ╣żū„ IaaS ╠ß╣®╔╠╩Ū┐╔ęįū÷Ą─Ż¼ę“×ķ▀@ą®ą┼Žó╩Ū┐╔ęį─├ĄĮĄ─ĪŻ
╚²Īó┤¾öĄō■╗∙ĄAŲĮ┼_
łD1 ŽĄĮy╝▄śŗ
ĮėŽ┬üĒ╬ęéā┐┤┐┤ėą──ą®┤¾öĄō■ŲĮ┼_ęį╝░╦³éāĄ─╠ž³cŻ¼Å─öĄō■Ą─╔·├³ų▄Ų┌üĒšfĘų▓╔╝»Ż¼é„▌öŻ¼┤µā”Ż¼Ęų╬÷ėŗ╦Ńęį╝░š╣¼FÄūéĆļAČ╬Ż¼╔Ž├µ▀@ÅłłD├Ķ╩÷┴╦▀@ÄūéĆļAČ╬¼Fį┌▒╚▌^┴„ąąĄ─╣żŠ▀║═ŲĮ┼_ĪŻ
łD2 ėŗ╦ŃŲĮ┼_
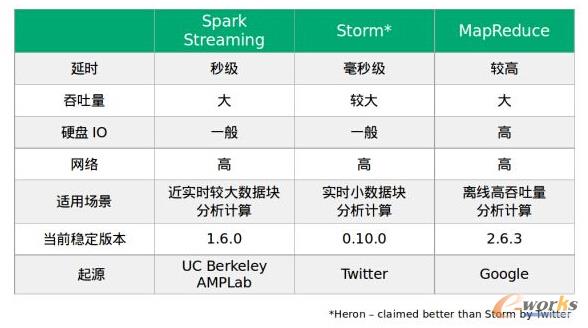
╩ūŽ╚ųvųvėŗ╦ŃŻ¼╚ń Spark ĪóStormĪóMapReduce Ą╚Ż¼╦¹éāĄ─ģ^äeų„ę¬į┌īŹĢrėŗ╦Ń║═ļxŠĆėŗ╦ŃŻ¼▀MČ°ė░Ēæų°Ė„ūįĄ─═╠═┬┴┐ĪŻ MapReduce ╩Ū└Ž┼ŲĄ─┤¾öĄō■ėŗ╦Ńę²ŪµŻ¼├┐éĆ Map Īó Reduce ļAČ╬═©▀^ė▓▒PüĒ▀MąąöĄō■Ą─Į╗╗źŻ¼ī”ė▓▒P I/O ę¬Ū¾▒╚▌^Ė▀Ż¼╦┘Č╚ę▓┬²Ż¼╦∙ęį▀m║ŽļxŠĆėŗ╦ŃŻ¼▀@Š═ī¦ų┬Ę▓╩ŪĖ· MapReduce ŽÓĻPĄ─¢|╬„Č╝▒╚▌^┬²Ż¼▒╚╚ń Hive ĪŻ
Storm īŹĢrąį▒╚▌^Ė▀Ż¼Ą½═╠═┬┴┐ŽÓī”üĒšf▒╚▌^ąĪŻ¼╦∙ęį╦³▀m║ŽīŹĢrąĪöĄō■ēKĘų╬÷ėŗ╦Ńł÷Š░ĪŻ Twitter ╠¢ĘQ Heron ▒╚ Storm čė▀tĖ³Ą═Ż¼═╠═┬┴┐Ė³Ė▀Ż¼╚ź─Ļ─ĻĄūĢ■ķ_į┤Ż¼Ą½╬ę║├Ž±ų┴Į±▓óø]ėą┐┤ĄĮĖ³ČÓĄ─ą┬┬äŻ¼─═ą─Ų┌┤²░╔ĪŻ
Spark Streaming Ė³▀m║ŽĮ³īŹĢr▌^┤¾öĄō■ēKĘų╬÷ėŗ╦ŃŻ¼ Spark ╩Ūę╗éĆ╗∙ė┌ā╚┤µĄ─Ęų▓╝╩Įėŗ╦ŃŽĄĮyŻ¼╣┘ĘĮ╔Ž┬ĢĘQ╦³▒╚ Hadoop Ą─ MapReduce ę¬┐ņ 100 ▒ČŻ¼ŲõīŹ Spark Ą─║╦ą─╩Ū RDD ėŗ╦Ń─Żą═ęį╝░╗∙ė┌╚½ŠųūŅāץ─ DAG ėąŽ“¤oŁhłDĄ─ŠÄ┼┼ĘĮ╩ĮŻ¼Č° MapReduce ╩Ūę╗ĘNų°č█ė┌Šų▓┐Ą─ėŗ╦Ń─Żą═Ż¼ų▒Įėī¦ų┬┴╦ Spark ╝┤╩╣╗∙ė┌ė▓▒Pę▓ę¬▒╚ MapReduce ┐ņ 10 ▒ČĪŻ Spark ╩Ūę╗éĆ║▄ųĄĄ├蹊┐Ą─ŲĮ┼_Ż¼ŽÓą┼┤¾╝ęČ╝ų¬Ą└╦³ėąČÓ├┤ā׹ŃĪŻ
ī”ė┌ SQL Ęų╬÷üĒšf¼Fį┌ų„ę¬Ęųā╔┤¾┴„┼╔Ż¼╗∙ė┌ MPP Ą─öĄō■é}Äņ║═ SQL-on-Hadoop ĪŻ
¼Fį┌┐┤ŲüĒ║¾š▀š╝┴╦³c╔Ž’LŻ¼ų„ꬥ─įŁę“ų«ę╗╩ŪŪ░š▀ąĶę¬╠žČ©Ą─ė▓╝■ų¦│ųŻ¼▓╗▀^ MPP Ą─öĄō■é}Äņį┌é„ĮyąąśI▀Ćėą║▄┤¾╩ął÷Ż¼ę▓║▄╩▄é„ĮyąąśIĄ─ÜgėŁŻ¼ę“×ķ╦³ėą Hadoop ─┐Ū░▀Ćø]ėąĄ─¢|╬„Ż¼▒╚╚ńšµš²ęŌ┴x╔Žų¦│ųś╦£╩Ą─ SQL Ż¼ų¦│ųĘų▓╝╩Į╩┬╬’Ą╚Ż¼╩╣Ą├ MPP öĄō■é}Äņ─▄║▄║├Ą─╝»│╔é„ĮyąąśI¼FėąĄ─ BI ╣żŠ▀ĪŻ┴Ē═ŌŻ¼ MPP öĄō■é}Äņę▓į┌Ž“ Hadoop ┐┐önŻ¼ų¦│ųŲš═©Ą─ X86 Ę■äšŲ„Ż¼Ąūīėų¦│ų Hadoop Ą─┤µā”Ż¼▒╚╚ń Apache HAWQ ĪŻŪÓįŲ 3 į┬ĄūĄ─śėūėĢ■╠ß╣® MPP öĄō■é}ÄņĘ■䚯¼╩Ūė╔ HAWQ Ą─ū„š▀╝µ GreenPlum Ą─čą░l╚╦åT║═╬ęéā║Žū„ķ_░l▀@éĆĘ■äšĪŻ SQL-on-Hadoop Š═▒╚▌^ČÓ┴╦Ż¼▒╚╚ń Spark SQL Īó Hive Īó Phoenix Īó Kylin Ą╚Ą╚Ż¼Hive ╩Ū░č SQL ▐DōQ×ķ MapReduce ╚╬䚯¼╦∙ęį╦┘Č╚▒╚▌^┬²Ż¼╚ń╣¹ī”▀\ąą╦┘Č╚ėąę¬Ū¾Ż¼┐╔ęįćLįć Spark SQLŻ¼īWŲüĒę▓║▄║åå╬Ż¼Spark SQL 1.6.0 Ą─ąį─▄ėą║▄┤¾╠ß╔²Ż¼┤¾╝ęĖą┼d╚ż┐╔ęį¾w“×ę╗Ž┬ĪŻ
▀Ćėą╗∙ė┌ Hadoop Ą─ MPP Ęų╬÷ę²Ūµ Impala Īó Presto Ą╚Ą╚Ż¼╬ęŠ═▓╗ę╗ę╗ĮķĮB┴╦ĪŻąĶę¬ūóęŌĄ─╩Ūėąą®ĒŚ─┐▀Ćį┌ Apache Ą─ʧ╗»Ų„└’Ż¼╚ń╣¹Žļį┌╔·«aŁhŠ│ųą╩╣ė├ąĶ╝ėąĪą─ĪŻ▀@éĆĄžĘĮėąęŌ╦╝Ą─╩Ū┤¾╝ęČ╝Ė· Hive ▒╚Ż¼ĮYšōČ╝╩Ū▒╚ Hive ┐ņČÓ╔┘▒ČŻ¼▀@éĆ╩Ū┐ŽČ©Ą─Ż¼╬ęéāĖ³Žļ┐┤ĄĮĄ─▀@ą®ą┬│÷üĒĄ─ SQL ŽÓ╗źķg▒╚╩Ūį§├┤śėĄ─Ż¼äe┐é─├ Hive ▒╚Ż¼ę▓įS╩ŪąĪąųĄ▄║├Ų█žōĪŻ

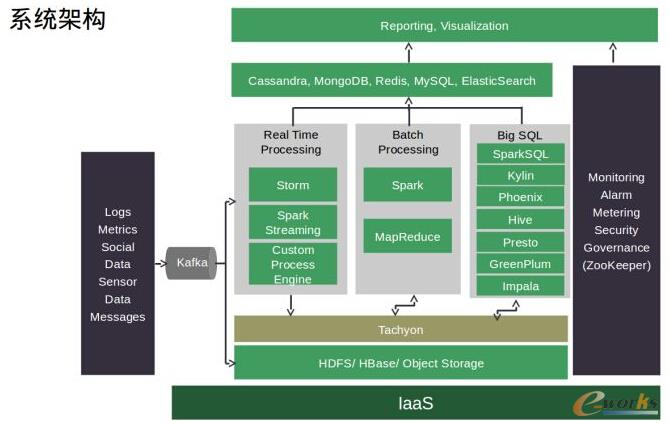
łD3 ┤µā”-Hadoop
┤µā”ų„ꬊ═╩Ū Hadoop/HDFS ĪóHBase Īóī”Ž¾┤µā”ęį╝░ MPP öĄō■é}ÄņĪŻ Hadoop ╩Ū▀m║Ž┤¾╬─╝■ę╗┤╬ąįīæ╚ļĪóČÓ┤╬ūx╚ĪĄ─ł÷Š░Ż¼▓╗─▄īæ║▄ČÓąĪ╬─╝■Ż¼ NameNode ║▄╚▌ęū┐ÕĄ¶Ż¼╚ń╣¹ĘŪę¬īæąĪ╬─╝■Ą─įÆ┐╔ęįŠW╔Ž╦čę╗ą®ąĪ╝╝Ū╔ĪŻ HBase ▀m║ŽļSÖCūxīæł÷Š░Ż¼╦³╩Ūę╗éĆ NoSQL Ą─Ęų▓╝╩Į┴ą╩ĮöĄō■ÄņŻ¼╩Ūę╗éĆ sparse Īó distributed Īó persistentĪó multidimensional sorted map Ż¼░č├┐éĆå╬į~└ĒĮŌ═Ė┴╦Š═┐╔ęį└ĒĮŌ HBase ╩Ūę╗éĆ╩▓├┤¢|╬„Ż¼╦³Ą─Ąūīėė├Ą─▀Ć╩Ū HDFS Ż¼▓╗▀^į┌Ęų╬÷ł÷Š░╚ń scan öĄō■Ą─Ģr║“╦³Ą─ąį─▄╩Ū▒╚▓╗╔Ž Hadoop Ą─Ż¼ąį─▄▓Ņ 8 ▒Č▀Ćę¬ČÓĪŻ HBase ÅŖį┌ļSÖCūxīæŻ¼ Hadoop ÅŖį┌Ęų╬÷Ż¼¼Fį┌ Apache ʧ╗»Ų„└’ėąę╗éĆĮą Kudu Ą─“ųąė╣”ĒŚ─┐Ż¼Š═╩Ū╝µŅÖļSÖCūxīæ║═Ęų╬÷ąį─▄ĪŻ HBase ŽļÅŖš{Ą─ę╗³cĄ─╩ŪöĄō■─Żą═Ą─įOėŗŻ¼│²┴╦╬ęéā┤¾╝ęČ╝ų¬Ą└Ą─ rowkey įOėŗĄ─ųžę¬ąįų«═ŌŻ¼▓╗ę¬ė├é„ĮyĄ─ĻPŽĄą═öĄō■Äņ╦╝ŠSĮ©─ŻŻ¼į┌┤¾öĄō■ŅIė“└’Ė³ČÓĄ─╩Ū▒M┴┐ denormalize ĪŻ
é„▌ö¼Fį┌ų„┴„Š═╩Ū Kafka ║═ Flume Ż¼║¾š▀ėą╝ė├▄╣”─▄Ż¼ Kafka ąĶę¬į┌śIäšīėū÷╝ė├▄Ż¼╚ń╣¹ėąąĶŪ¾Ą─įÆĪŻ Kafka ╩Ūę╗éĆĘų▓╝╩ĮĪó┐╔Ęųģ^ĪóČÓĖ▒▒ŠĄ─Ė▀═╠═┬┴┐Ą═čė▀tŽ¹ŽóŽĄĮyŻ¼ī”ė┌╗Ņ▄SĄ─┴„╩ĮöĄō■╠Ä└Ē▒╚╚ń╚šųŠĘų╬÷╩ŪūŅ║├▓╗▀^Ą─▀xō±ĪŻ
łD4 Kafka ║═ Flume
╔ŽłD╩Ū╬ęÅ─ę╗éĆšµīŹ┐═æ¶Ą─ kafka īŹĢr▒O┐žłDĮž╚Ī▀^üĒĄ─Ż¼─▄┐┤│÷┴„╚ļ┴„│÷Ą─ā╔éĆŪ·ŠĆ═Ļ╚½ųž»B┴╦Ż¼╬ęéā─▄┐┤│÷╦³Ą─čė▀tĘŪ│ŻĄ═Ż©║┴├ļ╝ēäeŻ®ĪŻ
Ą½╩Ū╬ęéā▓╗─▄×Eė├ Kafka Ż¼╬ęį°Įøė÷ĄĮ▀^ėą╚╦Žļė├ Kafka ū÷Ęų▓╝╩Į╩┬äšąįĄ─śIäš╚ńĮ╗ęūŻ¼Ą½ Kafka ▓óø]ėąą¹ĘQ╦³ų¦│ųŽ¹ŽóĄ─é„▀f╩Ū exact once Ż¼╦³─▄ū÷ĄĮ╩Ū at least once Ż¼╦∙ęįĘų▓╝╩Į╩┬äšąįĄ─śIäšæ¬įō╩Ū▓╗▀m║ŽĄ─Ż¼ąĶ꬜Iäšīėū÷ę╗ą®╣żū„ĪŻ
╦─ĪóöĄō■Ė±╩Į
ūŅ║¾ę╗éĆ╬ęŽļÅŖš{Ą─╩ŪöĄō■Ė±╩ĮŻ¼öĄō■Ė±╩ĮĄ─š²┤_▀xō±ī”┤¾öĄō■į§├┤ÅŖš{Č╝▓╗×ķ▀^ĪŻ▀xō±Õe┴╦Ģ■śO┤¾Ą─└╦┘M┤µā”┐šķgŻ¼┤¾öĄō■▒ŠüĒöĄō■┴┐Š═┤¾Ż¼Įø▓╗Ų│╔▒Č┐šķgĄ─└╦┘MŻ¼ąį─▄ę▓Ģ■ę“×ķĖ±╩Į▀xō±Õeš`╝▒äĪŽ┬ĮĄŻ¼╔§ų┴Č╝¤oĘ©▀MąąĪŻ
öĄō■Ė±╩Įę¬ėøūĪā╔³cŻ¼┐╔ĘųĖŅ║═┐╔ēKē║┐sĪŻ┐╔ĘųĖŅĄ─ęŌ╦╝Š═╩Ūę╗éĆ┤¾╬─╝■Å─ųąķgŪąĖŅŻ¼Ęų╬÷Ų„▀Ć─▄▓╗─▄å╬¬ÜĮŌ╬÷▀@ā╔éĆ╬─╝■Ż¼▒╚╚ń XML Ż¼╦³ėą open tag ║═ close tag Ż¼╚ń╣¹ųąķgüĒę╗ĄČŻ¼ XML Parser Š═▓╗Ģ■šJūRĪŻĄ½ CSV Š═▓╗ę╗śėŻ¼╦³╩Ūę╗éĆéĆĄ─ėøõøŻ¼├┐ę╗ąąå╬¬Ü─├│÷üĒ▀Ć╩ŪėąęŌ┴xĄ─ĪŻ
┐╔ēKē║┐sųĖĄ─╩Ū├┐éĆĘųĖŅ│÷üĒĄ─ēK─▄ʱ¬ÜūįĮŌē║┐sŻ¼▀@╩Ūę“×ķŪ░├µšf▀^Ą─┤¾öĄō■╩Ūėŗ╦ŃĖ·ų°öĄō■ū▀Ż¼╦∙ęį├┐éĆ╣سcĄ─ėŗ╦Ń╩ŪĘų╬÷▒ŠĄžĄ─öĄō■Ż¼Å─Č°ū÷ĄĮ▓óąąėŗ╦ŃĪŻĄ½ėąą®ē║┐sĖ±╩Į╚ń gzip Ż¼ CSV į┌ĮŌē║Ą─Ģr║“ąĶę¬Å─Ą┌ę╗ĘųĖŅēKķ_╩╝▓┼─▄ĮŌē║│╔╣”Ż¼▀@śėŠ═ū÷▓╗ĄĮšµš²Ą─▓óąąėŗ╦ŃĪŻ
╬ÕĪó┐éĮY
ūŅ║¾┐éĮYŪ░├µųvĄ─ÄūéĆė^³cŻ║┤¾öĄō■Ą─░lš╣ĘĮŽ“╩ŪįŲ╗»Ż¼įŲėŗ╦Ń▓┼╩Ū┤¾öĄō■╗∙ĄAŲĮ┼_ūŅ║├Ą─▓┐╩ĘĮ░ĖŻ╗┤¾öĄō■ĮŌøQĘĮ░Ėųąæ¬įōĖ∙ō■─ŃĄ─ąĶŪ¾üĒ▀xō±ŲĮ┼_Ż╗öĄō■Ė±╩ĮĄ─▀xō±║▄ųžę¬Ż¼═©│ŻŪķørėøūĪę¬▀xō±┐╔ĘųĖŅ║═┐╔ēKē║┐sĄ─öĄō■Ė±╩ĮĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌įŲėŗ╦ŃĄ─┤¾öĄō■ŲĮ┼_╗∙ĄAįO╩®Į©įOīŹ█`
▒Š╬─ŠWųĘŻ║http://m.vmgcyvh.cn/html/solutions/14019319895.html