öĄō■ÄņĄ─ÖMŽ“öUš╣ęčĮø│╔×ķĖ„éĆŲ¾śIė├æ¶Ą─╗∙▒ŠąĶŪ¾Ż¼ę╗ĘĮ├µļSų°Ų¾śIŪ░Č╦śI䚎ĄĮyĄ─┼“├øŻ¼║¾Č╦öĄō■ÄņŽĄĮyĄ─žō▌dę▓į┌▓╗öÓį÷ķLŻ¼Ų¾śI▀Mąą┐vŽ“öUš╣╝╝ągļyČ╚▌^┤¾Ż¼┴Ēę╗ĘĮ├µŻ¼öĄō■ÄņŽĄĮyĄ─ĻPµIąį▓╗öÓ╠ßĖ▀Ż¼ÖMŽ“öUš╣▓╗āH╠ßĖ▀╠Ä└Ēąį─▄Ż¼ę▓śO┤¾Ą─╠ßĖ▀┴╦öĄō■ÄņŽĄĮyĄ─╚▌Õe─▄┴”ĪŻ
ĪĪĪĪ
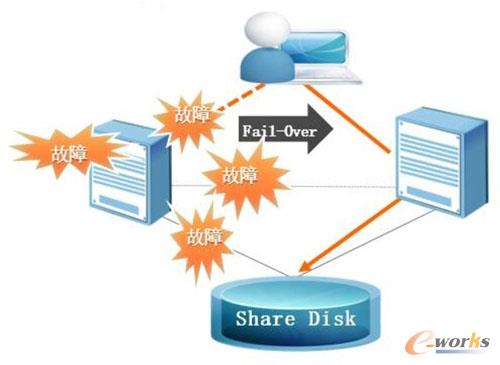
─┐Ū░Ż¼öĄō■ÄņÖMŽ“öUš╣ėąČÓĘNīŹ¼FĘĮ╩ĮŻ¼▌^×ķų„┴„Ą─╩Ū╣▓ŽĒ┤µā”(Shared Disk)╝╝ągŻ¼▓╗Š├Ū░Ż¼└╦│▒░l▓╝Ą─K-DBöĄō■ÄņŻ¼▀@┐Ņ«aŲĘŠ═╗∙ė┌╣▓ŽĒ┤µā”╝╝ągŻ¼īŹ¼F┴╦ļpÖCĖ▀┐╔ė├(HA)ĪóČÓÖC╝»╚║(KRAC)Ą╚öĄō■ÄņÖMŽ“öUš╣ĪŻ
ĪĪĪĪ
└╦│▒K-DB▓╔ė├╗∙ė┌╣▓ŽĒ┤µā”(Shared Disk)Ą─ļpÖC╗“ČÓÖC╝»╚║(KRAC)╝▄śŗĪŻ
ĪĪĪĪ
KRACŠ▀ėąā╔┤¾╠ž³cŻ║╣╩šŽ▐DęŲ║═žō▌dŠ∙║ŌĪŻę╗ĘĮ├µŻ¼KRAC╝»╚║╝╝ąg╠ß╣®Ė▀┐╔ė├ĮŌøQĘĮ░ĖŻ¼×ķė├æ¶╠ß╣®Įyę╗öĄō■Ę■䚥─═¼Ģr╠ß╣®╣╩šŽŪąōQ┼c╗ųÅ═─▄┴”(Fail Over╝»╚║╣”─▄)Ż¼▒▄├Ōå╬³c╣╩šŽŻ¼£p╔┘═ŻÖCĢrķgŻ¼┤_▒ŻŽĄĮy╚½─Ļ7*24ĘĆČ©▀\ąąĪŻ┴Ēę╗ĘĮ├µŻ¼║¾Č╦öĄō■ÄņŽĄĮyĄ─žō║╔ļSų°æ¬ė├ŽĄĮyē║┴”Ą─╔Ž╔²ę▓į┌▓╗öÓĄ─į÷╝ėŻ¼╝»╚║╝╝ąg─▄ē“īŹ¼FöĄō■ÄņŽĄĮyĄ─ÖMŽ“öUš╣Ż¼īóöĄō■ÄņĄ─ē║┴”ŲĮŠ∙Ęų┼õį┌ČÓ┼_öĄō■ÄņĘ■äšŲ„╔ŽĪŻĪĪKRAC ¾wŽĄĮYśŗ
ĪĪĪĪ
KRACė╔ČÓéĆ╣سcĄ─öĄō■ÄņĘ■äšŲ„║═╣▓ŽĒ┤µā”ĮM│╔ĪŻ╣▓ŽĒ┤µā”╔Žų„ę¬┤µĘ┼Ą─╩ŪöĄō■Äņ▒žąĶĄ─╬─╝■Ż¼░³└©öĄō■╬─╝■Īó╚šųŠ╬─╝■╝░┐žųŲ╬─╝■Ą╚ĪŻöĄō■ÄņĘ■äšŲ„╔Ž▀\ąąų°öĄō■Äņī”æ¬Ą─īŹ└²Ż¼ČÓīŹ└²ų«ķg═©▀^ā╚ŠW▀MąąöĄō■Ą─é„▌öĪŻKRAC Ą─Ė„éĆ╣سc┐╔ęį═¼Ģrī”┤┼▒P▀MąąūxīæŻ¼īŹ¼F┴╦ČÓūxČÓīæĄ─šµš²╝»╚║╝╝ągĪŻ
ĪĪĪĪ
KRACŠ▀ėąā╔┤¾╠ž³cŻ║╣╩šŽ▐DęŲ║═žō▌dŠ∙║ŌĪŻ
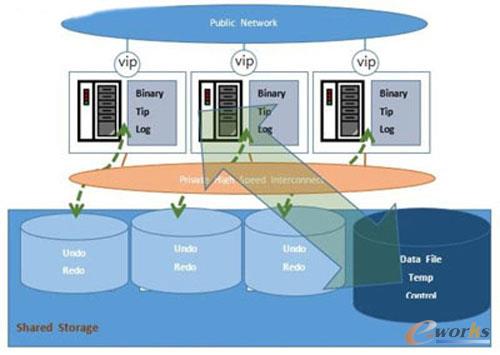
łD1 KRACĄ─¾wŽĄĮYśŗĪĪĪĪ
╠ž³cę╗Ż║╣╩šŽ▐DęŲ
łD2 KRAC╣╩šŽ▐DęŲ
KRAC öĄō■Äņ┐╔ęįī”öĄō■ÄņŽĄĮyųą│÷¼FĄ─╚╬║╬å╬³c╣╩šŽ╣سcĄ─session ▐DęŲĄĮŲõ╦¹š²│ŻĄ─╣سc╔ŽŻ¼╚ń┤┼▒PĪóŠWĮjĪóĘ■äšŲ„Ą╚Ż¼▒ŻšŽæ¬ė├ŽĄĮyĄ─▓╗ķgöÓŻ¼ūŅ┤¾│╠Č╚Ą─£p╔┘ė├æ¶Ą─ōp╩¦ĪŻ
╠ž³cČ■Ż║žō▌dŠ∙║Ō
ĪĪĪĪ
ĪĪĪĪ
KRAC Ģ■īó╦∙ėąĄ─ė├æ¶sessionŲĮŠ∙Ęų┼õĄĮĖ„éĆ╣سc╔ŽŻ¼╝»╚║ųąĄ─Ė„éĆ╣سcŠ∙─▄ī”┤┼▒P▀MąąūxīæŻ¼▀_ĄĮæ¬ė├ŽĄĮyĄ─ŠĆąįöUš╣Ż¼Å─š¹¾w╔Ž╠ßĖ▀öĄō■ÄņĄ─═╠═┬┴┐ĪŻ
ĪĪĪĪ
öĄō■ÄņĖ„éĆ╣سcĄ─īŹ└²ų«ķg═©▀^Ė▀╦┘Ą─ā╚ŠWé„╦═öĄō■Ż¼▒▄├Ō┴╦╣سcķgįLå¢öĄō■Č°«a╔·Ą─▓╗▒žę¬Ą─IOŻ¼Č°ė░ĒæĄĮąį─▄ĪŻČ°į┌KRAC ╝»╚║ųąŻ¼ė╔ė┌ėąČÓéĆ╣سcČ╝Š▀ėąblock bufferŻ¼▀@Š═ąĶę¬╣سcķgĄ─block buffer┐╔ęį╗źŽÓé„▌öįLå¢Ż¼▓┼─▄▀_ĄĮę╗ų┬ąįĄ─ĀŅæBĪŻ
ĪĪĪĪ
ꬊ▀éõęį╔Ž2┤¾╠ž³cŻ¼Š═▓╗Ą├▓╗╠ßā╚┤µ╚┌║Ž╝╝ągŻ¼╦¹╩ŪīŹ¼FKRAC╣”─▄Ą─║╦ą─ĪŻ
ĪĪĪĪ
KRAC║╦ą─╝╝ągŻ║ā╚┤µ╚┌║Ž
łD3 KRAC ā╚┤µ╚┌║ŽĪĪĪĪ
KRAC ╝»╚║ā╚▓┐ĮM╝■
ĪĪĪĪ
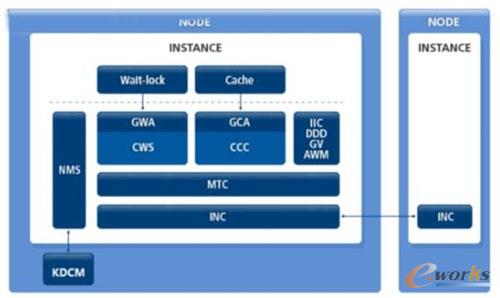
KRAC Ą─╝»╚║ųąė╔CCC(Cluster Cache Control)─ŻēK║═GCA(Global Cache Adapter)─ŻēKīŹ¼F╝»╚║ķgöĄō■ÄņĄ─╚┌║ŽĪŻé„▌öĄ─öĄō■ēKŅÉą═Ė∙ō■▓╗═¼ł÷Š░Ą─ąĶę¬Č°▓╗ę╗śėŻ¼ų„ę¬░³└©CR blockĪóGlobal dirty blockĪócurrent blockĪŻ╣سcķgöĄō■é„▌öĄ─╣”─▄ė╔─ŻēKINC(Inter-Node Communication)Ę■äšĪŻį┌╣سcķgšłŪ¾Ą─block buffer ė╔ CCC ║═CGA śŗįņ═Ļ«ģ║¾Ż¼INC žōž¤īóī”æ¬Ą─öĄō■ēKé„▌öĄĮ─┐Ą─╣سcĪŻ
ĪĪĪĪ
KRACā╚┤µ╚┌║Žų„ę¬¾w¼Fį┌4┤¾║╦ą─╝╝ąg╔ŽŻ║µiÖCųŲĪóĮŪ╔½ĪóPI BLOCK║═GLOBAL LOCK DIRETROYĪŻ
ĪĪĪĪ
Ž┬├µŻ¼╬ęéāīó×ķ┤¾╝ęįö╝ÜĮķĮB▀@4éĆ║╦ą─╝╝ąg³cĄ─▀\ąąÖCųŲĪŻ
ĪĪĪĪ
µiÖCųŲ
ĪĪĪĪ
į┌öĄō■ÄņųąŻ¼ī”ė┌öĄō■ēKĄ─block bufferĄ─▓ó░lūxīæ╩╣ė├µiÖCųŲ▀Mąą▒ŻūoĪŻ├┐ę╗éĆöĄō■ēKĄ─µi░³└©╚²ĘN─Ż╩ĮŻ¼Ęųäe×ķNULLĪó SHARED║═EXCLUSIVE ĪŻ╚²ĘN─Ż╩ĮĄ─╝µ╚▌┴ą▒Ē╚ńŽ┬Ż║«ö─│ę╗éĆė├æ¶│ųėąblock buffer Ą─µiĢrŻ¼╚ń╣¹Ųõ╦¹ė├æ¶ęį╝µ╚▌─Ż╩ĮĄ─µiĘĮ╩Į▀MąąįLå¢Ż¼─Ū├┤▀@2éĆė├æ¶┐╔ęį═¼ĢrįLå¢įōöĄō■ēKĪŻ
ĪĪĪĪ
Č°ę╗Ą®2éĆė├æ¶ęį▓╗╝µ╚▌ĘĮ╩ĮįLå¢═¼ę╗éĆöĄō■ēKĢrŻ¼║¾├µĄ─ė├æ¶▒žĒÜĄ╚ĄĮŪ░ę╗ė├æ¶ßīĘ┼µių«║¾▓┼─▄ķ_╩╝▓┘ū„ĪŻ▀@ĘNĮŌøQĘĮ░Ė╩Ūå╬īŹ└²K-DBöĄō■ÄņĄ─ĮŌøQĘĮ░ĖĪŻČ°į┌KRAC ųąŻ¼K-DBöĄō■Äņį┌┤╦╗∙ĄA╔ŽŻ¼į÷╝ė┴╦Ņ~═Ō┴╦╣▄└ĒĘĮ╩Į-ĮŪ╔½║═Past image BlocköĄō■ēKĪŻ
ĪĪĪĪ
ĮŪ╔½
ĪĪĪĪ
K-DB ī”ė┌öĄō■ēKĄ─Ęų┼õ┴╦2ĘNĮŪ╔½Ż¼Ęųäe╩ŪLOCAL ║═ GLOBALŻ¼«ööĄō■block bufferų╗į┌ę╗éĆ╣سc┼c┤┼▒P╔ŽĄ─öĄō■▓╗ę╗śė(┼KöĄō■)Ż¼įōblock bufferĄ─ĮŪ╔½×ķLOCALĀŅæBĪŻ«öį┌ČÓéĆ╣سc╔Ž┤µį┌“┼KöĄō■”ĢrŻ¼block buffer Ą─ĮŪ╔½×ķGLOBALĪŻ
ĪĪĪĪ
PI BLOCK
ĪĪĪĪ
╚ń╣¹ę╗éĆblock į┌─│ę╗éĆ╣سcųą▒╗ą▐Ė─║¾Ż¼╚╗║¾įōblock é„▌öĄĮ┴╦Ųõ╦¹╣سcŻ¼─Ū├┤▒Š╣سc┤µā”Ą─blockēK×ķPI(Past Image)blockĪŻPI BLOCK ēKį┌ęįŽ┬2éĆĘĮ├µŠ▀ėąę╗Č©Ą─ā×╗»ū„ė├Ż║
ĪĪĪĪ
1Īó╠ß╔²CR ēKśŗĮ©Ą─╦┘Č╚ĪŻ«ö▒ŠĄžśŗĮ©Ą─CRēKĄ─SCN ąĪė┌PI BLOCK Ą─SCNĢrŻ¼¤oąĶÅ─Ųõ╦¹╣سcé„▌öūŅą┬Ą─currentöĄō■ÄņŻ¼ų▒Įėį┌▒ŠĄž╩╣ė├PI BLOCK┐╔ęįśŗįņĪŻ
ĪĪ
2Īó╣سcÕ┤ÖC║¾Ż¼╠ß╔²ŽĄĮy╗ųÅ═Ą─ąį─▄ĪŻ«ö─│ę╗éĆ╣سcÕ┤ÖC║¾Ż¼š¹éĆ╝»╚║Ģ■Ģ║Ģr═Żų╣Ę■䚯¼▀Mąąā╚▓┐╗ųÅ═ĪŻ╗ųÅ═Ą─įŁ└ĒŠ═╩ŪīóÕ┤Ą¶╣سcĄ─redo╚šųŠį┌Ųõ╦¹╣سc▀Mąą╗ųÅ═ĪŻį┌╗ųÅ═ĢrŻ¼ī”ė┌redo╚šųŠųąąĪė┌PI BLOCKĄ─SCN¤oąĶųžū÷Ż¼Å─┤¾ė┌Ą╚ė┌PI BLOCKĄ─SCN╠Äķ_╩╝╗ųÅ═Ż¼Å─š¹¾w╔Ž£p╔┘┴╦╗ųÅ═Ą─╣żū„┴┐ĪŻ
ĪĪĪĪ
GLOBAL LOCK DIRETROY
ĪĪĪĪ
į┌K-DBöĄō■ÄņųąŻ¼╦∙ėąĖ„éĆ╣سcī”ė┌buffer block Ą─µią┼ŽóŻ¼Č╝Ģ■ėøõøį┌Global Lock Directory(GLD)ĪŻĖ„éĆ╣سcį┌share pool ā╚┤µųąĘų┼õ│÷ę╗▓┐Ęųā╚┤µŻ¼╣▓═¼ĮM│╔š¹éĆĄ─GLDĪŻ─Ū├┤ę╗éĆ╣سcĢ■ėøõø──ę╗éĆöĄō■ēKĄ─µi║═ĮŪ╔½Ą─ŽÓĻPą┼Žó─žŻ┐
ĪĪĪĪ
į┌▀@└’Ż¼KRAC ėų╠ß│÷┴╦ę╗éĆą┬Ą─ÖCųŲŻ¼Š═╩ŪmasterÖCųŲĪŻ
ĪĪĪĪ
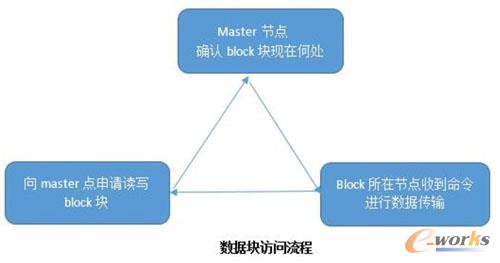
╦∙ėąĄ─buffer blockį┌«öŪ░Ą─š²į┌▀\ąąĀŅæBĄ─╝»╚║ųąŻ¼ų╗Ģ■ī”æ¬ĄĮę╗éĆmaster╣سcŻ¼įōmaster╣سcĢ■ėøõøŽÓī”æ¬Ą─buffer block į┌Ė„éĆ╣سcųąµiĀŅæB║═ĮŪ╔½Ą─ŽÓĻPą┼ŽóĪŻ╚╬║╬╣سcį┌įLå¢─│ę╗éĆbuffer blockĢrŻ¼Č╝ąĶꬎ“╦¹Ą─master╣سc▀Mąą╔ĻšłĪŻMaster ╣سcį┌╩šĄĮbuffer block įLå¢Ą─šłŪ¾║¾Ż¼Ģ■┤_Č©įōbuffer block ēKĄ─«öŪ░╬╗ų├Ż¼╚╗║¾īóįōbuffer blockēKé„╦═ĮošłŪ¾ė├æ¶ĪŻ╦∙ėąĄ─masterųąĄ─ą┼ŽóŻ¼╣▓═¼ĮM│╔┴╦GLR(Global Lock Directory)ĪŻ×ķ┴╦▒Ńė┌┤¾╝ęĖ³ų▒ė^└ĒĮŌā╚┤µ╚┌║ŽŻ¼Ž┬├µ═©▀^╚²éĆł÷Š░┼e└²šf├„Ż║
łD4 öĄō■ēKįLå¢┴„│╠
ĪĪĪĪ
ł÷Š░╩Š└²——ā╚┤µ╚┌║Ž
£yįćģóöĄšf├„Ż║£yįćBlock Ą─master ╣سc╩ŪCĪŻMaster╣سcųąĻPė┌buffer blockę╗╣▓ėøõø┴╦4éĆģóöĄŻ¼Ą┌ę╗éĆ┤·▒ĒĄ─µi─Ż╩ĮŻ¼╚ńS(Shared)Ż¼E(Exclusive)Ż¼N(Null)ĪŻĄ┌Č■éĆģóöĄ╩ŪČ©┴xĄ─╩ŪĮŪ╔½Ż¼╚ńL(Local)Ż¼G(Global)ĪŻĄ┌╚²éĆģóöĄČ©┴xĄ─╩Ū╩Ūʱ×ķPIŻ¼ 0┤·▒ĒʱŻ¼1┤·▒Ē╩ŪĪŻĄ┌╦─éĆģóöĄ╩Ūįōµiī”æ¬Ą─instance ╣سcĪŻ
ĪĪĪĪ
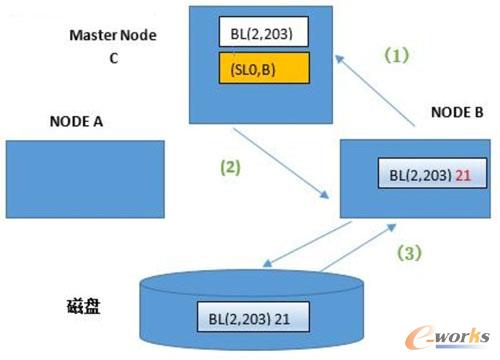
ł÷Š░ę╗ ╣سcBūx╚Ī┤┼▒PųąĄ─BLOCKēK
ĪĪĪĪ
(1)B╣سcŽ“master C╣سc╔Ļšłūx╚Īblock(2Ż¼203)Ż¼BLOCK ųąĄ─öĄō■×ķ21
ĪĪĪĪ
(2)ų„╣سcmaster C Ž“B╣سc┘xėĶblock(2Ż¼203)Ą─ local ĮŪ╔½shared ─Ż╩Įlock
ĪĪĪĪ
(3)B╣سcÅ─┤┼▒Pūx╚ĪblockēK(2Ż¼203)ł÷Š░Č■╣سcAĖ³ą┬╣سcBųąŠÅ┤µĄ─buffer block
łD5 BLOCKēKĪĪĪĪ
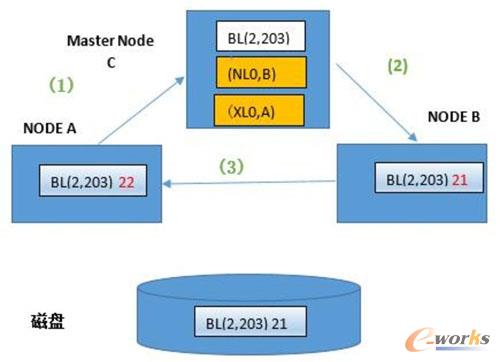
(1) A╣سcŽ“Master Node C╔ĻšłīæBL(2Ż¼203)Ż¼īó21ą▐Ė─×ķ22ĪŻ
ĪĪĪĪ
(2) Master╣Ø░l¼FB╣سcęįShared ─Ż╩Į│ųėąBL(2Ż¼203)ĪŻmasterų„╣سcę¬Ū¾B╣سcīó«öŪ░Ą─µiė╔SharedĮĄ×ķNull─Ż╩ĮĪŻ
ĪĪĪĪ
(3) ╣سcBīó▒ŠĄžĄ─µiĮĄ×ķNull─Ż╩Į║¾Ż¼īóBL(2Ż¼203)░l╦═ĮoA╣سcĪŻA╣سc½@╚Īlocal ĮŪ╔½Ą─exclusive ─Ż╩ĮĄ─µiŻ¼ą▐Ė─BL(2Ż¼2003)ųąĄ─öĄō■×ķ22ĪŻł÷Š░╚²B╣سcį┘┤╬Ė³ą┬═¼ę╗éĆBlock
ĪĪĪĪ
łD6 ł÷Š░Č■╣سcAĖ³ą┬╣سcBųąŠÅ┤µĄ─buffer block
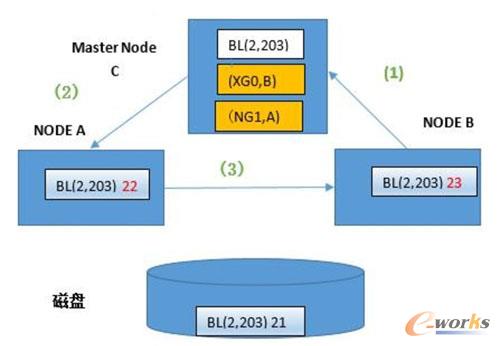
(1)B╣سcŽ“Master ╔ĻšłXµiŻ¼īæBlock BL(2Ż¼203)ĪŻīóöĄō■ą▐Ė─×ķ23
ĪĪ
(2)Master ╣سc░l¼FūŅą┬░µ▒ŠĄ─öĄō■ēKį┌A╣سc╔ŽŻ¼▓óŪęA ęįXµiš╝ėąįōöĄō■ēKĪŻMaster ╣سcę¬Ū¾A╣سcĄ─µiĮĄ×ķNULL─Ż╩ĮŻ¼ ═¼Ģrė╔ė┌┤╦║¾2éĆ╣سcųąČ╝┤µį┌┼c┤┼▒PųąĄ─öĄō■▓╗ę╗ų┬Ą─öĄō■Ż¼A╣سcĄ─ĮŪ╔½╔²╝ē×ķGLOBALŻ¼Aųą«öŪ░Ą─öĄō■Äņėø×ķPIēKĪŻ
ĪĪĪĪ
(3)A╣سcµiĮĄ╝ē║¾Ż¼īóöĄō■ēKBL(2Ż¼203)é„╦═ĄĮB ╣سcŻ¼╣سcBīóöĄō■ą▐Ė─×ķ23ĪŻ║├┴╦Ż¼═©▀^╔Ž╬─ĮķĮBŻ¼Žļ▒ž┤¾╝ęī”└╦│▒K-DBöĄō■ÄņĄ─KRAC╣”─▄║═▀\ąąįŁ└Ēėą┴╦╚½├µšJūRĪŻ
łD7 ł÷Š░╚²B╣سcį┘┤╬Ė³ą┬═¼ę╗éĆBlockĪĪĪĪ
┐éĮYüĒųvŻ¼└╦│▒K-DBöĄō■Äņ╩Ū│²┴╦Oracleęį═ŌŻ¼Ą┌Č■éĆ─▄ē“īŹ¼F╣▓ŽĒ┤µā”Ą─╝»╚║╝╝ągĄ─«aŲĘŻ¼▓╔ė├KRACČÓÖC╝»╚║╝▄śŗŻ¼Š▀ėą╣╩šŽūįäė▐DęŲĪóĖ▀╔ņ┐s─▄┴”║═ūįäėžō▌dŠ∙║Ō╠žąįŻ¼▒ŻšŽŽĄĮy┐╔ė├ąįĄ─═¼ĢrŻ¼┤¾Ę∙╠ß╔²┐╔ė├ąį║═ąį─▄ Ż¼▀Ć─▄īŹ¼FŽĄĮyąį─▄ŲĮ╗¼╔²╝ēŪęĮėĮ³ŠĆąįĄ─öUš╣ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║£\šäKRACā╚┤µ╚┌║Ž╝╝ąg