ĪĪĪĪę╗ĪóĖ┼╩÷
ĪĪĪĪįŲėŗ(j©¼)╦ŃŻ©cloud computingŻ®Ż¼╩ŪĘų▓╝╩Įėŗ(j©¼)╦Ń╝╝ąg(sh©┤)Ą─ę╗ĘNĪŻįŲėŗ(j©¼)╦Ń═Ė▀^ŠW(w©Żng)Įj(lu©░)▀BĮėŻ¼īóę╗Ūąļ[ø]į┌įŲČ╦Ż¼Ųš═©ė├æ¶▓╗į┌ĻP(gu©Īn)ą─öĄ(sh©┤)ō■(j©┤)┤µį┌──└’Ż¼▓╗į┌ĻP(gu©Īn)ą─öĄ(sh©┤)ō■(j©┤)Ą─░▓╚½Ż¼▓╗į┌ĻP(gu©Īn)ą─æ¬(y©®ng)ė├│╠ą“╩ŪʱąĶę¬╔²╝ēŻ¼▓╗į┌ĻP(gu©Īn)ą─ėŗ(j©¼)╦ŃÖC(j©®)▓ĪČŠŻ¼▀@ę╗Ūą╣żū„Č╝ė╔įŲėŗ(j©¼)╦Ńųąą─žō(f©┤)ž¤(z©”)ĮŌøQŻ¼Ųš═©ė├æ¶ę¬ū÷Ą─Š═╩Ū▀xō±ūį╝║Ž▓É█Ą─įŲĘ■äš(w©┤)╔╠▓ó┘Å┘Iūį╝║ąĶꬥ─Ę■äš(w©┤)ĪŻįŲėŗ(j©¼)╦Ń╩╣Ųš═©ė├æ¶ėą┴╦ŽĒ╩▄Ė▀ąį─▄ėŗ(j©¼)╦ŃĄ─ÖC(j©®)Ģ■(hu©¼)Ż¼įŲėŗ(j©¼)╦Ńųąą─Äū║§┐╔─▄╠ß╣®¤oŽ▐ųŲĄ─ėŗ(j©¼)╦Ń─▄┴”ĪŻ
ĪĪĪĪGoogle ╠ß│÷Ą─įŲėŗ(j©¼)╦ŃÅŖ(qi©óng)š{(di©żo)Ą─╩ŪįŲĄ─ųžę¬ąįŻ¼ę“?y©żn)ķGoogleÅ─üĒČ╝ø]ėąČ╦Ż¼▓óŪęīóGFS Æü│÷ū„×ķšTDė¹š╝ų„äė(d©░ng)Ż╗╬ó▄øätÅŖ(qi©óng)š{(di©żo)“įŲ”╝ė“Č╦”▓┼╩ŪįŲėŗ(j©¼)╦ŃŻ¼ę“?y©żn)ķ╬ó▄øĄ─ęĢ┤░ę╗ų▒╩?ldquo;Č╦”Ą─░įų„Ż╗VMware ätšJ(r©©n)×ķ╠ōöM╗»╩ŪįŲėŗ(j©¼)╦ŃĄ─║╦ą─╝╝ąg(sh©┤)Ż╗Sun ╣½╦Šätųž╠ßČÓ─ĻŪ░╦¹éāšfĄ─└ŽįÆ“ŠW(w©Żng)Įj(lu©░)Š═╩Ūėŗ(j©¼)╦ŃÖC(j©®)”Ż╗Adobeät═©▀^Flex š╝ŅI(l©½ng)ė├æ¶Ą─č█Ū“Ż¼╩╣Flash Player ▀M(j©¼n)▄ŖįŲėŗ(j©¼)╦ŃŻ╗┴Ē═Ō┤¾┴┐Ą─Ę■äš(w©┤)Ų„═ą╣▄╣½╦ŠätīóĘ■äš(w©┤)Ų„Ą─ūŌė├ĘQ×ķįŲėŗ(j©¼)╦ŃĪŻįŲ┤µā”(ch©│)╩Ūį┌įŲėŗ(j©¼)╦ŃĖ┼─Ņ╔Žčė╔ņ║═░l(f©Ī)š╣│÷üĒĄ─ę╗éĆ(g©©)ą┬Ą─Ė┼─ŅŻ¼╩ŪįŲ┤µā”(ch©│)ųžę¬Ą─┤µā”(ch©│)┘Yį┤ĪŻ╦³═©▀^╝»╚║ėŗ(j©¼)╦ŃĪóŠW(w©Żng)Ė±ėŗ(j©¼)╦Ń║═Ęų▓╝╩Įėŗ(j©¼)╦ŃĄ╚╣”─▄Ż¼═Ė▀^ŠW(w©Żng)Įj(lu©░)Ż¼īó▓╗═¼ŅÉą═Ą─┤µā”(ch©│)įO(sh©©)éõ═©▀^▄ø╝■ģf(xi©”)═¼╣żū„Ż¼ī”ŠW(w©Żng)Įj(lu©░)ė├æ¶╠ß╣®öĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)║═įLå¢╣”─▄ĪŻ
ĪĪĪĪČ■ĪóįŲ┤µā”(ch©│)ĮY(ji©”)śŗ(g©░u)
ĪĪĪĪįŲ┤µā”(ch©│)īóįŲŽĄĮy(t©»ng)Ą─┤µā”(ch©│)┘Yį┤▀M(j©¼n)ąąĮy(t©»ng)ę╗š¹║Ž╣▄└ĒŻ¼╠ß╣®┤µā”(ch©│)╠ōöM╗»╣”─▄Ż¼×ķė├æ¶╠ß╣®ę╗éĆ(g©©)Įy(t©»ng)ę╗Ą─┤µā”(ch©│)┐šķgŻ¼Š▀ėą╝»ųą┤µā”(ch©│)ĪóĘų▓╝╩ĮöU(ku©░)š╣Īó░▓╚½šJ(r©©n)ūCĪóöĄ(sh©┤)ō■(j©┤)╝ė├▄Ą╚ĘĮ├µĄ─ā×(y©Łu)³c(di©Żn)ĪŻį┌įŲĀŅ┤µā”(ch©│)ŽĄĮy(t©»ng)ųąŻ¼╦∙ėą┤µā”(ch©│)┘Yį┤ī”╩╣ė├š▀Č╝╩Ū═Ė├„Ą─Ż¼╩╣ė├š▀▓╗▒žų¬Ą└┤µā”(ch©│)įO(sh©©)éõĄ─ą═╠¢(h©żo)ĪóĮė┐┌║═é„▌öģf(xi©”)ūhŻ¼ę▓▓╗▒žĮ©┴ó²ŗ┤¾Ą─¬Ü(d©▓)┴óĄ─öĄ(sh©┤)ō■(j©┤)éõĘ▌ŽĄĮy(t©»ng)║═æ¬(y©®ng)╝▒╚▌×─(z©Īi)ŽĄĮy(t©»ng)Ż¼▀@ą®ĀŅæB(t©żi)▒O(ji©Īn)┐žĪóŠSūo(h©┤)ĪóéõĘ▌║═æ¬(y©®ng)╝▒╚▌×─(z©Īi)į┌įŲ┤µā”(ch©│)ŽĄĮy(t©»ng)ųąČ╝─▄ē“ūįäė(d©░ng)═Ļ│╔Ż¼ęčĮø(j©®ng)ū„×ķįŲĄ─║▄ūį╚╗Ą─ę╗▓┐ĘųĪŻįŲ┤µā”(ch©│)Ą─ĮY(ji©”)śŗ(g©░u)╚ńłD1 ╦∙╩ŠĪŻįŲ┤µā”(ch©│)ĮY(ji©”)śŗ(g©░u)─Żą═ė╔4 īėĮM│╔ĪŻ
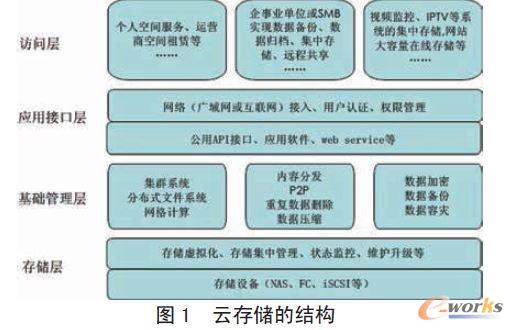
ĪĪĪĪ1. ┤µā”(ch©│)īė
ĪĪĪĪįŲ┤µā”(ch©│)įO(sh©©)éõ┐╔ęį╩Ū╣Ō└w═©Ą└┤µā”(ch©│)įO(sh©©)éõŻ¼ę▓┐╔ęį╩ŪNAS ╗“š▀ iSCSI Ą╚ŠW(w©Żng)Įj(lu©░)┤µā”(ch©│)įO(sh©©)éõĪŻį┌įŲųąŻ¼┤µā”(ch©│)įO(sh©©)éõöĄ(sh©┤)┴┐²ŗ┤¾Ż¼═©│ŻĢ■(hu©¼)Ęų▓╝į┌▓╗═¼Ą─ĄžĘĮŻ¼═©▀^ÅVė“ŠW(w©Żng)Īó╗ź┬ō(li©ón)ŠW(w©Żng)╗“š▀īŻė├Ą─╣Ō└wŠW(w©Żng)Įj(lu©░)▀BĮėĪŻ═©│ŻąĶę¬╠ß╣®ę╗éĆ(g©©)Įy(t©»ng)ę╗Ą─┤µā”(ch©│)įO(sh©©)éõ╣▄└ĒŽĄĮy(t©»ng)Ż¼īŹ(sh©¬)¼F(xi©żn)╬’└Ē┤µā”(ch©│)įO(sh©©)éõĄ─▀ē▌ŗ╗»║═╠ōöM╗»╣▄└ĒĪŻ
ĪĪĪĪ2. ╗∙ĄA(ch©│)╣▄└Ēīė
ĪĪĪĪ╗∙ĄA(ch©│)╣▄└Ēīė╩ŪįŲ┤µā”(ch©│)║╦ą─Ą─▓┐ĘųĪŻįōīė═©▀^╝»╚║┤µā”(ch©│)ĪóĘų▓╝╩Į┤µā”(ch©│)║═ŠW(w©Żng)Ė±┤µā”(ch©│)Ą╚╝╝ąg(sh©┤)Ż¼īŹ(sh©¬)¼F(xi©żn)▒ŖČÓ┤µā”(ch©│)įO(sh©©)éõų«ķgĄ─ģf(xi©”)═¼╣żū„Ż¼ī”═Ō╠ß╣®Įy(t©»ng)ę╗Ą─┤µā”(ch©│)įLå¢Ę■äš(w©┤)ĪŻ
ĪĪĪĪ3. æ¬(y©®ng)ė├Įė┐┌īė
ĪĪĪĪ╩Ūė╔▒ŖČÓĄ─Ą┌╚²ĘĮ▄øė▓╝■ÅS╔╠╠ß╣®Ą─▓Õ╝■īėĪŻ▀\(y©┤n)ĀIå╬╬╗┐╔ęįĖ∙ō■(j©┤)īŹ(sh©¬)ļHśI(y©©)äš(w©┤)ąĶ꬯¼└¹ė├æ¬(y©®ng)ė├Įė┐┌┐ņ╦┘ķ_░l(f©Ī)ØMūŃąĶŪ¾Ą─æ¬(y©®ng)ė├│╠ą“Ż¼╚ńįŲ┤µā”(ch©│)Ą─ęĢŅl▒O(ji©Īn)┐žæ¬(y©®ng)ė├ĪóęĢŅl³c(di©Żn)▓źæ¬(y©®ng)ė├ĪóŠW(w©Żng)Įj(lu©░)┤µā”(ch©│)Ą─ė▓▒PĪó▀h(yu©Żn)│╠öĄ(sh©┤)ō■(j©┤)éõĘ▌æ¬(y©®ng)ė├Ą╚ĪŻ
ĪĪĪĪ4. įLå¢īė
ĪĪĪĪįLå¢īė╠ß╣®Įoė├æ¶Įy(t©»ng)ę╗Ą─įLå¢ĄŪõøĮė┐┌ĪŻė├æ¶ų╗ėąĄŪõø║¾Ż¼▓┼┐╔ęį╩╣ė├įŲ┤µā”(ch©│)Ę■äš(w©┤)ĪŻ▓╗═¼Ą─įŲ┤µā”(ch©│)ŽĄĮy(t©»ng)╠ß╣®Ą─įLå¢ŅÉą═║═įLå¢╩ųČ╬▓╗═¼Ż¼░▓╚½ąĶŪ¾ę▓Ģ■(hu©¼)Ū¦▓Ņ╚fäeĪŻė├æ¶┐╔ęįĖ∙ō■(j©┤)ūį╝║Ą─ąĶŪ¾▀xō±ŽÓæ¬(y©®ng)Ą─Ę■äš(w©┤)ĪŻ
ĪĪĪĪ╚²ĪóįŲ┤µā”(ch©│)ŲĮ┼_(t©ói)įO(sh©©)ėŗ(j©¼)┼cīŹ(sh©¬)¼F(xi©żn)
ĪĪĪĪŻ©ę╗Ż®įO(sh©©)ėŗ(j©¼)ĘĮ░ĖšōūC▒╚▌^
ĪĪĪĪGoogle GFS Google Ą─öĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)┼c╣▄└Ē╝╝ąg(sh©┤)Š▀ėąęįŽ┬╠ž³c(di©Żn)Ż║╗∙ė┌┤¾ęÄ(gu©®)─Ż( ÄūŪ¦ĄĮ╔Ž╚f╣Ø(ji©”)³c(di©Żn)) ═©ė├PC śŗ(g©░u)Į©╝»╚║Ż╗╝»╚║╣Ø(ji©”)³c(di©Żn)═¼Ģr(sh©¬)╠ß╣®┤µā”(ch©│)┼cėŗ(j©¼)╦ŃĘ■äš(w©┤)Ż╗╗∙ė┌▓╗┐╔┐┐ė▓╝■Łh(hu©ón)Š│īŹ(sh©¬)¼F(xi©żn)┴╦Ė▀┐╔┐┐Ą─╝»╚║▄ø╝■ŽĄĮy(t©»ng)Ż╗ė├ė┌╠Ä└Ē┼c╔·│╔║Ż┴┐öĄ(sh©┤)ō■(j©┤)╝»Ą─Ęų▓╝╩Įėŗ(j©¼)╦Ń─Żą═Ė▀Č╚│ķŽ¾Ż¼į┌öĄ(sh©┤)ō■(j©┤)├▄╝»ą═śI(y©©)äš(w©┤)ųąæ¬(y©®ng)ė├ÅVĘ║Ż╗öĄ(sh©┤)ō■(j©┤)╣▄└ĒŽĄĮy(t©»ng)▓╗ų¦│ų═Ļš¹Ą─ĻP(gu©Īn)ŽĄ─Żą═Ż¼ĮY(ji©”)śŗ(g©░u)║åå╬Č°▌p┴┐ĪŻ
ĪĪĪĪHadoop īŹ(sh©¬)¼F(xi©żn)┴╦ę╗éĆ(g©©)Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż¼║åĘQHDFSĪŻė├æ¶┐╔ęįį┌▓╗┴╦ĮŌĘų▓╝╩ĮĄūīė╝Ü(x©¼)╣Ø(ji©”)Ą─ŪķørŽ┬Ż¼ķ_░l(f©Ī)Ęų▓╝╩Į│╠ą“ĪŻ│õĘų└¹ė├╝»╚║Ą─═■┴”Ė▀╦┘▀\(y©┤n)╦Ń║═┤µā”(ch©│)ĪŻHDFS ėąų°Ė▀╚▌Õe(cu©░)ąįĄ─╠ž³c(di©Żn)Ż¼▓óŪęįO(sh©©)ėŗ(j©¼)ė├üĒ▓┐╩į┌Ą═┴«Ą─ė▓╝■╔ŽĪŻČ°Ūę╦³╠ß╣®Ė▀é„▌ö┬╩üĒįLå¢æ¬(y©®ng)ė├│╠ą“Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▀m║Ž─Ūą®ėąų°│¼┤¾öĄ(sh©┤)ō■(j©┤)╝»Ą─æ¬(y©®ng)ė├│╠ą“ĪŻHDFS ▓╔ė├master/slave ╝▄śŗ(g©░u)ĪŻę╗éĆ(g©©)Namenod ęį╝░ę╗Č©öĄ(sh©┤)─┐Ą─Datanode ĮM│╔ę╗éĆ(g©©)HDFS ╝»╚║ĪŻį┌╝»╚║ųąŻ¼├┐ę╗éĆ(g©©)╣Ø(ji©”)³c(di©Żn)░³║¼ę╗éĆ(g©©)DatanodeĪŻę╗éĆ(g©©)╬─╝■ätĘųĖŅ│╔ę╗éĆ(g©©)╗“ČÓéĆ(g©©)blockŻ¼ė╔Datanode ╝»║Ž╠ß╣®┤µā”(ch©│)blockĪŻHDFS ▓╔ė├java šZčįķ_░l(f©Ī)Ż¼▀@Įo▀\(y©┤n)┤µā”(ch©│)Ą─▓┐╩ĦüĒ║▄┤¾Ą─ĘĮ▒ŃĪŻ
ĪĪĪĪDynamo ╩Ūüå±R▀dĄ─key-value ─Ż╩ĮĄ─┤µā”(ch©│)ŲĮ┼_(t©ói)Ż¼┐╔ė├ąį║═öU(ku©░)š╣ąįČ╝║▄║├Ż¼ąį─▄ę▓▓╗Õe(cu©░)Ż║ūxīæįLå¢ųą99.9% Ą─Ēææ¬(y©®ng)Ģr(sh©¬)ķgČ╝į┌300ms ā╚(n©©i)ĪŻDynamo Ą─┐╔öU(ku©░)š╣ąį║═┐╔ė├ąį▓╔ė├Ą─Č╝▒╚▌^│╔╩ņĄ─╝╝ąg(sh©┤)Ż¼öĄ(sh©┤)ō■(j©┤)Ęųģ^(q©▒)▓╔ė├Ė─▀M(j©¼n)Ą─ę╗ų┬ąį╣■ŽŻ(consistentĪĪhashing) ĘĮ╩Į▀M(j©¼n)ąąÅ═(f©┤)ųŲŻ¼└¹ė├öĄ(sh©┤)ō■(j©┤)ī”Ž¾Ą─░µ▒Š╗»īŹ(sh©¬)¼F(xi©żn)ę╗ų┬ąįĪŻÅ═(f©┤)ųŲĢr(sh©¬)ę“?y©żn)ķĖ³ą┬«a(ch©Żn)╔·Ą─ę╗ų┬ąįå¢Ņ}Ą─ŠSūo(h©┤)▓╔╚ĪNRW ÖC(j©®)ųŲęį╝░╚źųąą─╗»Ą─Å═(f©┤)ųŲ═¼▓Įģf(xi©”)ūhĪŻDynamo ╩Ū═Ļ╚½╚źųąą─╗»Ą─ŽĄĮy(t©»ng)Ż¼╚╦╣ż╣▄└Ē╣żū„║▄ąĪĪŻDynamo ░┤Ęų▓╝╩ĮŽĄĮy(t©»ng)│Żė├Ą─╣■ŽŻ╦ŃĘ©ŪąĘų?j©½n)?sh©┤)ō■(j©┤)Ż¼ĘųĘ┼į┌▓╗═¼Ą─node ╔ŽĪŻRead ▓┘ū„Ģr(sh©¬)Ż¼ę▓╩ŪĖ∙ō■(j©┤)key Ą─╣■ŽŻųĄīżšęī”æ¬(y©®ng)Ą─nodeĪŻDynamo ╩╣ė├┴╦ConsistentHashing ╦ŃĘ©Ż¼node ī”æ¬(y©®ng)Ą─▓╗į┘╩Ūę╗éĆ(g©©)┤_Č©Ą─hash ųĄŻ¼Č°╩Ūę╗éĆ(g©©)hash ųĄĘČć·Ż¼key Ą─hash ųĄ┬õį┌▀@éĆ(g©©)ĘČć·ā╚(n©©i)Ż¼ätĒśĢr(sh©¬)ßśčžring šęŻ¼┼÷ĄĮĄ─Ą┌ę╗éĆ(g©©)node ╝┤×ķ╦∙ąĶĪŻDynamo ī”Consistent Hashing ╦ŃĘ©Ą─Ė─▀M(j©¼n)į┌ė┌Ż║╦³Ę┼į┌Łh(hu©ón)╔Žū„×ķę╗éĆ(g©©)node Ą─╩Ūę╗ĮMÖC(j©®)Ų„Ż©Č°▓╗╩Ūmemcached ░čę╗┼_(t©ói)ÖC(j©®)Ų„ū„×ķnodeŻ®Ż¼▀@ę╗ĮMÖC(j©®)Ų„╩Ū═©▀^═¼▓ĮÖC(j©®)ųŲ▒ŻūCöĄ(sh©┤)ō■(j©┤)ę╗ų┬Ą─ĪŻ╚ń╣¹ę╗éĆ(g©©)ring ā╚(n©©i)Ą─įLå¢┴┐┤¾┴╦Ż¼ät┐╔ęįį┌ā╔éĆ(g©©)node ķg╝ė╚ļę╗éĆ(g©©)ą┬node ęįŠÅĮŌē║┴”Ż¼▀@Ģr(sh©¬)Ģ■(hu©¼)ė░ĒæĄĮŲõ║¾└^node Ą─hash ĘČć·Ż¼ąĶ꬚{(di©żo)š¹öĄ(sh©┤)ō■(j©┤)ĪŻ╝┘įO(sh©©)ę╗éĆ(g©©)ring ųąįŁ▒Šų╗ėąnode2Īónode3Īónode4Ż¼į┌╝ė╚ļą┬Ą─node1 ų«║¾Ż¼įŁŽ╚Å─node2 ▓ķįāĄ─▓┐Ęųkey īóĖ─×ķÅ─node1 ▓ķįāŻ¼node1 ║═node2 ųąĄ─öĄ(sh©┤)ō■(j©┤)Š═ąĶ꬚{(di©żo)š¹Ż¼ų„ę¬╩Ūnode1 Å─node2 ųą╠ß╚Ī│÷ī┘ė┌╦³Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▀@śėū÷ąĶę¬▀x╚Īąį─▄ē║┴”▓╗Ė▀Ą─Ģr(sh©¬)║“ĪŻDynamo Ą─ę╗éĆ(g©©)node ųąę╗┼_(t©ói)ÖC(j©®)Ų„Į©ėąę╗éĆ(g©©)Merkle TreeŻ¼«ö(d©Īng)ā╔┼_(t©ói)ÖC(j©®)Ų„▓╗ę╗ų┬Ģr(sh©¬)Ż¼═©▀^▀@éĆ(g©©)tree ĮY(ji©”)śŗ(g©░u)Ż¼┐╔ęį┐ņ╦┘Č©╬╗▓╗ę╗ų┬Ą─Object üĒ╗ųÅ═(f©┤)öĄ(sh©┤)ō■(j©┤)ĪŻMerkle Tree ėųĮąHash TreeŻ¼╦³░čkey Ęų│╔ÄūéĆ(g©©)rangeŻ¼├┐éĆ(g©©)range ╦Ń│÷ę╗éĆ(g©©)hash ųĄŻ¼ū„×ķ╚~ūėŻ¼į┘ę╗īėīė║Ž▓óėŗ(j©¼)╦Ń╔Ž╚źŻ¼▀@śėŻ¼Å─root ķ_╩╝▒╚▌^hash ųĄŻ¼Š═┐╔ęį┐ņ╦┘šęĄĮ──ÄūČ╬range ųąĄ─hash ųĄūā╗»┴╦ĪŻ
ĪĪĪĪSAN ŽĄĮy(t©»ng)╩Ūį┌┤µā”(ch©│)Č╦śŗ(g©░u)Į©┤µā”(ch©│)Ą─ŠW(w©Żng)Įj(lu©░)Ż¼īóČÓéĆ(g©©)┤µā”(ch©│)įO(sh©©)éõśŗ(g©░u)│╔ę╗éĆ(g©©)┤µā”(ch©│)ģ^(q©▒)ė“ŠW(w©Żng)Įj(lu©░)ĪŻŪ░Č╦Ą─ų„ÖC(j©®)┐╔ęį═©▀^ŠW(w©Żng)Įj(lu©░)Ą─ĘĮ╩ĮįLå¢║¾Č╦Ą─┤µā”(ch©│)įO(sh©©)éõĪŻČ°ŪęŻ¼ė╔ė┌╠ß╣®┴╦ēKįO(sh©©)éõĄ─įLå¢ĘĮ╩ĮŻ¼┼cŪ░Č╦▓┘ū„ŽĄĮy(t©»ng)¤oĻP(gu©Īn)ĪŻį┌SAN ▀BĮėĘĮ╩Į╔ŽŻ¼┐╔ęįėąČÓĘN▀xō±ĪŻę╗ĘN▀xō±╩Ū╩╣ė├╣Ō└wŠW(w©Żng)Įj(lu©░)Ż¼─▄ē“▓┘ū„┐ņ╦┘Ą─╣Ō└w┤┼▒PĪŻ┴Ē═Ōę╗ĘN▀xō±╩Ū╩╣ė├ęį╠½ŠW(w©Żng)Ż¼▓╔╚ĪiSCSI ģf(xi©”)ūhŻ¼─▄ē“▀\(y©┤n)ąąį┌Ųš═©Ą─Šųė“ŠW(w©Żng)Łh(hu©ón)Š│Ž┬ĪŻė╔ė┌┤µā”(ch©│)ģ^(q©▒)ė“ŠW(w©Żng)Įj(lu©░)ųąĄ─┤┼▒PįO(sh©©)éõ▓óø]ėą┼c─│ę╗┼_(t©ói)ų„ÖC(j©®)ĮēČ©į┌ę╗ŲŻ¼Č°╩Ū▓╔ė├┴╦ĘŪ│Żņ`╗ŅĄ─ĮY(ji©”)śŗ(g©░u)Ż¼ę“┤╦ī”ė┌ų„ÖC(j©®)üĒšf┐╔ęįįLå¢ČÓéĆ(g©©)┤┼▒PįO(sh©©)éõŻ¼Å─Č°─▄ē“½@Ą├ąį─▄Ą─╠ß╔²ĪŻSAN ŽĄĮy(t©»ng)┼cĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)└²╚ńGoogle File System▓ó▓╗╩ŪŽÓ╗źī”┴óĄ─ŽĄĮy(t©»ng)Ż¼Č°╩Ūį┌śŗ(g©░u)Į©╝»╚║ŽĄĮy(t©»ng)Ą─Ģr(sh©¬)║“┐╔╣®▀xō±Ą─ā╔ĘNĘĮ░ĖĪŻŲõųąŻ¼į┌▀xō±SAN ŽĄĮy(t©»ng)Ą─Ģr(sh©¬)║“Ż¼×ķ┴╦æ¬(y©®ng)ė├│╠ą“Ą─ūxīæŻ¼▀ĆąĶę¬×ķæ¬(y©®ng)ė├│╠ą“╠ß╣®╔ŽīėĄ─šZ┴xĮė┐┌Ż¼┤╦Ģr(sh©¬)Š═ąĶę¬į┌SAN ų«╔Žśŗ(g©░u)Į©╬─╝■ŽĄĮy(t©»ng)ĪŻČ°Google File System š²║├╩Ūę╗éĆ(g©©)Ęų▓╝╩ĮĄ─╬─╝■ŽĄĮy(t©»ng)Ż¼ę“┤╦─▄ē“Į©┴óį┌SAN ŽĄĮy(t©»ng)ų«╔ŽĪŻ┐é¾wüĒšfŻ¼SAN ┼cĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Č╝┐╔ęį╠ß╣®ŅÉ╦ŲĄ─╣”─▄ĪŻ
ĪĪĪĪŻ©Č■Ż®╩╣ė├hadoop īŹ(sh©¬)¼F(xi©żn)╦ĮėąįŲ┤µā”(ch©│)
ĪĪĪĪHadoop ū„×ķGoogle Ą─ķ_į┤īŹ(sh©¬)¼F(xi©żn)Ż¼ŲõŠ▀ėąęįŽ┬ÄūéĆ(g©©)ā×(y©Łu)³c(di©Żn)ĪŻ┐╔öU(ku©░)š╣Ż¼▓╗šō╩Ū┤µā”(ch©│)Ą─┐╔öU(ku©░)š╣▀Ć╩Ūėŗ(j©¼)╦ŃĄ─┐╔öU(ku©░)š╣Č╝╩ŪHadoopĄ─įO(sh©©)ėŗ(j©¼)Ė∙▒ŠĪŻĮø(j©®ng)Ø·(j©¼)Ż¼┐“╝▄┐╔ęį▀\(y©┤n)ąąį┌╚╬║╬Ųš═©Ą─PC ╔ŽĪŻ┐╔┐┐Ż¼Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ą─éõĘ▌╗ųÅ═(f©┤)ÖC(j©®)ųŲęį╝░MapReduce Ą─╚╬äš(w©┤)▒O(ji©Īn)┐ž▒ŻūC┴╦Ęų▓╝╩Į╠Ä└ĒĄ─┐╔┐┐ąįĪŻĖ▀ą¦Ż║Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ą─Ė▀ą¦öĄ(sh©┤)ō■(j©┤)Į╗╗źīŹ(sh©¬)¼F(xi©żn)ęį╝░MapReduce ĮY(ji©”)║ŽLocalData ╠Ä└ĒĄ──Ż╩ĮŻ¼×ķĖ▀ą¦╠Ä└Ē║Ż┴┐Ą─ą┼Žóū„┴╦╗∙ĄA(ch©│)£╩(zh©│n)éõĪŻHDFS ▓╔ė├java šZčįķ_░l(f©Ī)Ż¼ę“┤╦║▄╔┘┤µį┌╝µ╚▌ąįå¢Ņ}ĪŻHadoop ▀@ą®╠ž³c(di©Żn)▀m║Žė┌Ų¾śI(y©©)īŹ(sh©¬)¼F(xi©żn)╦ĮėąįŲŲĮ┼_(t©ói)ĪŻ
ĪĪĪĪ╦∙įO(sh©©)ėŗ(j©¼)Ą─įŲ┤µā”(ch©│)ŽĄĮy(t©»ng)Ą─¾wŽĄĮY(ji©”)śŗ(g©░u)ė╔web ┐═æ¶Č╦ĪóWeb ▓┘ū„ŽĄĮy(t©»ng)ĪóįŲ┤µā”(ch©│)Ę■äš(w©┤)Ų„ĪóįŲ┤µā”(ch©│)ųąą─╬ÕéĆ(g©©)▓┐Ęųśŗ(g©░u)│╔ĪŻŲõĮY(ji©”)śŗ(g©░u)╚ńłD2 ╦∙╩ŠĪŻ
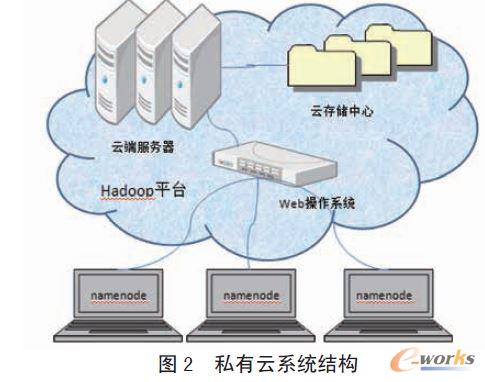
ĪĪĪĪ1. ┐═æ¶Č╦
ĪĪĪĪ┐═æ¶Č╦ÖC(j©®)╚║╩ŪįŲ┤µā”(ch©│)ŽĄĮy(t©»ng)Ą─Ū░┼_(t©ói)ŽĄĮy(t©»ng)Ż¼┐═æ¶Č╦ÖC(j©®)Ų„╔Žų╗ąĶę¬░▓čb×gė[Ų„Š═─▄ē“ØMūŃė├æ¶įLå¢ąĶŪ¾ĪŻė├æ¶═©▀^×gė[Ų„įLå¢įŲ┤µā”(ch©│)ŽĄĮy(t©»ng)Ż¼Ųõ╦¹Ą─Ę■äš(w©┤)Č╝ė╔įŲ┤µā”(ch©│)ŽĄĮy(t©»ng)į┌║¾┼_(t©ói)ūįäė(d©░ng)ĪŻ
ĪĪĪĪ2.Web ▓┘ū„ŽĄĮy(t©»ng)
ĪĪĪĪ▀@└’Ą─web ▓┘ū„ŽĄĮy(t©»ng)▓╔ė├┴╦eysOSĪŻEyeOS žō(f©┤)ž¤(z©”)Įė╩š┐═æ¶Ą─įL墚łŪ¾Ż¼ī”┐═æ¶Ą─įL墚łŪ¾īŹ(sh©¬)╩®║ŽĘ©ąį“×(y©żn)ūCĪŻEyeOSųą╠ß╣®┴╦┤¾┴┐Ą─æ¬(y©®ng)ė├Ż¼į╩įSė├æ¶Ė∙ō■(j©┤)ūį╝║Ą─Ž▓║├Ž┬▌d║═╩╣ė├▀@ą®æ¬(y©®ng)ė├Ż¼īŹ(sh©¬)¼F(xi©żn)ŽĄĮy(t©»ng)Ą─éĆ(g©©)ąį╗»┼õų├Ż¼šµš²▀_(d©ó)ĄĮ“ę╗┤╬┼õų├Ż¼ĄĮ╠Ä╩╣ė├”ĪŻeysOS ═¼Ģr(sh©¬)╠ß╣®ė├æ¶╬─╝■Ą─┤µ╚ĪĮė┐┌Ż¼═©▀^įōĮė┐┌┐╔ęįīó╬─╝■┤µā”(ch©│)ĄĮHadoop įŲČ╦Ż¼═¼Ģr(sh©¬)┐╔ęį═©▀^╦³ī”╬─╝■▀M(j©¼n)ąąĖ„ĘN▓┘ū„ĪŻ
ĪĪĪĪ3. įŲ┤µā”(ch©│)Ę■äš(w©┤)Ų„
ĪĪĪĪįŲ┤µā”(ch©│)Ę■äš(w©┤)Ų„ė╔┤¾┴┐Ą─╝»╚║“įŲČ╦Ę■äš(w©┤)Ų„”śŗ(g©░u)│╔Ż¼═¼Ģr(sh©¬)×ķHadoop ╠ß╣®╣▄└Ē╣Ø(ji©”)³c(di©Żn)(NameNode)Ż¼žō(f©┤)ž¤(z©”)╣▄└Ē╬─╝■ŽĄĮy(t©»ng)├¹ĘQ┐šķg║═┐žųŲ═Ō▓┐┐═æ¶ÖC(j©®)Ą─įLå¢ĪŻ«ö(d©Īng)╚╗ė├æ¶Ą─öĄ(sh©┤)ō■(j©┤)ę▓Č╝╩Ū┤µā”(ch©│)į┌▀@└’Ą─ĪŻ
ĪĪĪĪ4. įŲ┤µā”(ch©│)ųąą─
ĪĪĪĪįŲ┤µā”(ch©│)ųąą─ė╔▒ŖČÓĄ─Ę■äš(w©┤)Ų„śŗ(g©░u)│╔Hadoop Ą─öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c(di©Żn)(DataNodes)Ż¼žō(f©┤)ž¤(z©”)▒Ż┤µ╬─╝■öĄ(sh©┤)ō■(j©┤)Ż¼īŹ(sh©¬)¼F(xi©żn)╬─╝■Ą─Ęų▓╝╩Į┤µā”(ch©│)Īóžō(f©┤)▌dŲĮ║Ōęį╝░╬─╝■Ą─╚▌Õe(cu©░)┐žųŲĪŻ
ĪĪĪĪŲõīŹ(sh©¬)╩®▀^│╠ų„ę¬░³└©Ż║
ĪĪĪĪ1. ą┬Į©ŽĄĮy(t©»ng)Hadoop ė├æ¶
ĪĪĪĪHadoop ę¬Ū¾╦∙ėąÖC(j©®)Ų„╔Žhadoop Ą─▓┐╩─┐õøĮY(ji©”)śŗ(g©░u)ꬎÓ═¼Ż¼▓óŪęČ╝ėąę╗éĆ(g©©)ŽÓ═¼Ą─ė├æ¶├¹Ą─Äżæ¶Ż¼╦∙ęįąĶę¬├┐┼_(t©ói)ÖC(j©®)Ų„Į©ę╗éĆ(g©©)═¼├¹Ą─ė├æ¶ĪŻį┌▀@4 ┼_(t©ói)ÖC(j©®)Ų„╔ŽĮ©hadoop ė├æ¶▓ó╝ė╚ļĄĮroot ĮMŻ¼├▄┤aŻ║hadoopŻ¼─¼šJ(r©©n)┬ĘÅĮ/home/hadoop/ĪŻ
ĪĪĪĪ2.SSH įO(sh©©)ų├
ĪĪĪĪHadoop ąĶę¬namenode ĄĮdatanode Ą─¤o├▄┤aSSHŻ¼╦∙ęįąĶę¬įO(sh©©)ų├namenode ĄĮŲõ╦¹3 ┼_(t©ói)datanode Ą─¤o├▄┤a╣½ĶĆšJ(r©©n)ūCĘĮ╩ĮĄ─SSHĪŻįO(sh©©)ų├═Ļ│╔║¾Ż¼£yįćę╗Ž┬namenode ĄĮĖ„éĆ(g©©)╣Ø(ji©”)³c(di©Żn)Ą─SSH µ£ĮėŻ¼░³└©ĄĮ▒ŠÖC(j©®)Ż¼╚ń╣¹▓╗ąĶę¬▌ö╚ļ├▄┤aŠ═┐╔ęįSSH ĄŪõøŻ¼šf├„įO(sh©©)ų├│╔╣”┴╦ĪŻ
ĪĪĪĪ3. ░▓čbJDK
ĪĪĪĪĄĮsun ŠW(w©Żng)šŠŽ┬▌dJDK ░▓čb░³Ż¼▓óį┌├┐┼_(t©ói)ÖC(j©®)Ų„Ą─root ė├涎┬├µ░▓čbĪŻ░▓čb▄ø╝■Ģ■(hu©¼)īóJDK ūįäė(d©░ng)░▓čbĄĮ /usr/java/jdk1.6.0_26 ─┐õøŽ┬ĪŻ░▓čb═Ļ│╔║¾į┘įO(sh©©)ų├JDK Ą─Łh(hu©ón)Š│ūā┴┐ĪŻ┐╝æ]ĄĮJDK ┐╔─▄Ģ■(hu©¼)ėąŲõ╦¹ŽĄĮy(t©»ng)ė├æ¶ę▓Ģ■(hu©¼)ė├ĄĮŻ¼Į©ūhīóŁh(hu©ón)Š│ūā┴┐ų▒ĮėįO(sh©©)ų├į┌/etc/profile ųąĪŻ
ĪĪĪĪ4.Hadoop ╝»╚║┼õų├
ĪĪĪĪė├hadoop ė├æ¶ĄŪõønamenodeŻ¼ į┌ namenode ╔ŽŽ┬▌dhadoop-0.20.2.tar.gzŻ¼īóŲõĮŌē║ĄĮ/home/hadoop/ ─┐õøŽ┬Ż¼╚╗║¾į┌ hadoop Ž┬äō(chu©żng)Į©tmp ╬─╝■ŖA▓ó░čHadoop Ą─░▓čb┬ĘÅĮ╠Ē╝ėĄĮ/etc/profile ųąą▐Ė─/etc/profile ╬─╝■( ┼õų├ javaŁh(hu©ón)Š│ūā┴┐Ą─╬─╝■)Ż¼įO(sh©©)ų├HADOOP_HOME ║═PATH Ą─┬ĘÅĮŻ¼▓ó╩╣Ųõėąą¦ĪŻ┴Ē═Ōį┌datanode ╔Žę▓ąĶę¬╚ńnamenode ę╗śėą▐Ė─┼õų├HADOOP_HOME ║═PATHĪŻ
ĪĪĪĪŠÄ▌ŗHadoop ┼õų├╬─╝■ĪŻhadoop ┼õų├╬─╝■į┌conf ─┐õøŽ┬Ż¼░³└©Ż║hadoop-env.shŻ║ ┼õų├JAVA_HOME ┬ĘÅĮŻ╗core-site.xmlŻ║┼õų├Common ĮM╝■Ą─ī┘ąįŻ╗hdfs-site.xmlŻ║┼õų├HDFSĮM╝■Ą─ī┘ąįŻ╗mapred-site.xmlŻ║┼õų├map-reduce ĮM╝■Ą─ī┘ąįŻ╗┼õų├masters ╬─╝■Ż¼╝ė╚ļnamenode Ą─ip ĄžųĘŻ╗┼õų├slaves╬─╝■Ż¼╝ė╚ļ╦∙ėądatanode Ą─ip ĄžųĘĄ╚ĪŻ
ĪĪĪĪ╦─Īó╦ĮėąįŲųą╬─╝■ūxīæ┴„│╠
ĪĪĪĪūx╬─╝■Ą─┴„│╠Ż║ūxę╗éĆ(g©©)╬─╝■ė├æ¶╩ūŽ╚ąĶę¬Å─Hadoop Ą─öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c(di©Żn)░č╬─╝■Ž┬▌dĄĮ▒ŠĄžŻ¼╚╗║¾į┘ė╔ŽÓæ¬(y©®ng)Ą─▄ø╝■┤“ķ_’@╩ŠĮoė├æ¶ĪŻūx╬─╝■▀^│╠╚ńŽ┬Ż║Ż©1Ż®═©▀^×gė[Ų„Ż¼ė├æ¶įLå¢▀\(y©┤n)┤µā”(ch©│)Ą─Web ▓┘ū„ŽĄĮy(t©»ng)Ż¼ļpō¶Žļę¬įLå¢Ą─╬─╝■łDś╦(bi©Īo)Ż¼╩╣Ą├eyeOS Ž“Hadoop ╣▄└Ē╣Ø(ji©”)³c(di©Żn)░l(f©Ī)│÷½@╚Ī╬─╝■šłŪ¾ĪŻŻ©2Ż®╣▄└Ē╣Ø(ji©”)³c(di©Żn)▓ķšęę¬įLå¢Ą─╬─╝■ą┼ŽóŻ¼═Ė▀^öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c(di©Żn)░č╬─╝■ā╚(n©©i)╚▌░l(f©Ī)╦═ĄĮ┐═æ¶Č╦ĪŻŻ©3Ż®┐═æ¶Č╦Ž┬▌döĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c(di©Żn)é„▀^üĒĄ─╬─╝■ēKŻ¼▓óūįäė(d©░ng)īó▀@ą®ēK║Ž▓ó│╔ę╗éĆ(g©©)╬─╝■ĪŻ
ĪĪĪĪŻ©4Ż®į┌Web ▓┘ū„ŽĄĮy(t©»ng)ųąŻ¼ūįäė(d©░ng)åóäė(d©░ng)įō╬─╝■ĻP(gu©Īn)┬ō(li©ón)Ą─æ¬(y©®ng)ė├│╠ą“Ż¼’@╩Š╬─╝■ā╚(n©©i)╚▌ĪŻ
ĪĪĪĪīæ╬─╝■Ą─┴„│╠Ż║ė├æ¶ī”╬─╝■▀M(j©¼n)ąąą▐Ė─Ż¼▓ó╠ßĮ╗▒Ż┤µšłŪ¾Ż¼WEB ▓┘ū„ŽĄĮy(t©»ng)Ģ■(hu©¼)īóė├æ¶ą▐Ė─║¾Ą─╬─╝■ūįäė(d©░ng)╔Žé„ĄĮįŲųąĪŻ┴Ē═ŌŻ¼ė├æ¶ę▓┐╔ęįūįų„▀xō±╔Žé„╬─╝■ĄĮįŲ┤µā”(ch©│)ŽĄĮy(t©»ng)ĪŻŻ©1Ż®ė├æ¶╩╣ė├×gė[Ų„┐═æ¶Č╦Ż¼įLå¢▀\(y©┤n)┤µā”(ch©│)Ą─web ▓┘ū„ŽĄĮy(t©»ng)Ż¼ūįäė(d©░ng)åóäė(d©░ng)ŽÓĻP(gu©Īn)┬ō(li©ón)Ą─│╠ą“ą▐Ė─▓ó▒Ż┤µŽļę¬įLå¢Ą─╬─╝■Ż¼╩╣Ą├eyeOS Ž“Hadoop ╣Ø(ji©”)³c(di©Żn)░l(f©Ī)│÷╔Žé„╬─╝■šłŪ¾ĪŻŻ©2Ż®╣▄└Ē╣Ø(ji©”)³c(di©Żn)Įė╩šĄĮ╬─╝■╔Žé„šłŪ¾Ż¼ūįäė(d©░ng)ėŗ(j©¼)╦Ń╬─╝■┤¾ąĪŻ¼▓ķšęŽĄĮy(t©»ng)öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c(di©Żn)┤µā”(ch©│)ĀŅørŻ¼Ęų┼õ┤µā”(ch©│)┐šķgĪŻŻ©3Ż®┐═æ¶Č╦╔Žé„╬─╝■ēKĄĮĖ„éĆ(g©©)öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c(di©Żn)Ż¼═Ļ│╔╬─╝■Ą─ą▐Ė─┤µā”(ch©│)ĪŻ
ĪĪĪĪ╬ÕĪóĮY(ji©”)šō
ĪĪĪĪÜwĖ∙ĄĮĄūŻ¼įŲ┤µā”(ch©│)╩ŪĘų▓╝╩Į┤µā”(ch©│)╝╝ąg(sh©┤)Ą─░l(f©Ī)š╣║═čė└m(x©┤)ĪŻ═Ė▀^ÅVė“ŠW(w©Żng)Ż¼įŲ┤µā”(ch©│)īŹ(sh©¬)¼F(xi©żn)▒╚é„Įy(t©»ng)Ą─Ęų▓╝╩Į┤µā”(ch©│)Ė³═Ė├„ĪóĖ³┐ņ╦┘ĪóĖ³┐╔┐┐Ą─▀h(yu©Żn)│╠┤µā”(ch©│)įLå¢╝╝ąg(sh©┤)ĪŻ
ĪĪĪĪ▒Š╬─īŹ(sh©¬)¼F(xi©żn)┴╦śŗ(g©░u)Į©╦ĮėąįŲ┤µā”(ch©│)ŲĮ┼_(t©ói)╔ŽįŲ┤µā”(ch©│)Ą─╣▄└Ē┼cæ¬(y©®ng)ė├Ż¼ęįhadoop ķ_į┤ŲĮ┼_(t©ói)īŹ(sh©¬)¼F(xi©żn)┴╦ę╗éĆ(g©©)ęįWeb ▓┘ū„ŽĄĮy(t©»ng)×ķįŲ┤µā”(ch©│)Įė┐┌Ą─įŲ┤µā”(ch©│)ŽĄĮy(t©»ng)ĪŻŽ┬ę╗▓Įīó└^└m(x©┤)ī”ŽĄĮy(t©»ng)▀M(j©¼n)ąą─µŽ“£yįćĪóē║┴”£yįćĪó╝µ╚▌ąį£yįćĄ╚īŹ(sh©¬)ė├ąįĘĮ├µĄ─£yįćĪŻęį╝░▀M(j©¼n)ę╗▓Įā×(y©Łu)╗»Ą─╣żū„ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.vmgcyvh.cn/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╦ĮėąįŲ┤µā”(ch©│)ŲĮ┼_(t©ói)╝╝ąg(sh©┤)╝░æ¬(y©®ng)ė├
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.vmgcyvh.cn/html/consultation/10839712727.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")