░ķļSų°öĄō■Äņ║═ą┼Žó╝╝ągĄ─░lš╣Ż¼«a╔·┴╦┤¾ęÄ─ŻĄ─║Ż┴┐öĄō■Ż¼öĄō■═┌Š“╝╝ąg─▄ē“ūįäėĄžĪó┐ņ╦┘ĄžĪóųŪ─▄Ąž░čÜv╩ĘöĄō■Üw╝{│╔×ķėąųĖī¦ęŌ┴xĄ─ą┼ŽóĪŻļSų°3G ╝╝ągŲš╝░Ż¼Ė„éĆ▀\ĀI╔╠ų«ķgĄ─ĖéĀÄĘŪ│Ż╝ż┴ęŻ¼Ė„éĆ▀\ĀI╔╠×ķ┴╦į÷╝ė┐═æ¶Ż¼┴¶ūĪ▓╗öÓōQŠWĄ─ė├æ¶Ż¼ę“┤╦ī”┐═æ¶ĻPŽĄ╣▄└ĒĄ─蹊┐╩«ĘųųžęĢĪŻ▒Š╬─īó╩╣ė├öĄō■═┌Š“╝╝ągī”┐═æ¶ĻPŽĄ╣▄└ĒŻ©║åĘQŻ║CRMŻ®▀Mąą╠Į╦„║═蹊┐ĪŻ
1 öĄō■═┌Š“╝╝ągĖ┼╩÷
öĄō■═┌Š“╝╝ąg╩Ūę╗ķT╚┌║Ž┴╦ĮyėŗīWĪó╚╦╣żųŪ─▄ĪóÖCŲ„īW┴ĢĪóöĄō■ÄņČÓĘĮ├µų¬ūRĄ─ŠC║ŽąįīW┐ŲŻ¼╚╦╣żųŪ─▄╠Ä└ĒĪóöĄō■Äņ╝╝ąg║═öĄ└ĒĮyėŗ╩Ū╦³Ą─╗∙ĄAĪŻöĄō■═┌Š“Ą─ų„ę¬╚╬äš╩Ū“ų¬ūR░l¼F”Ż¼╦³ę¬Å─▓╗═Ļ╚½Ą─Īó┤¾┴┐Ą─Īóėąįļ┬ĢĄ─ĪóļSÖCĄ─Īó─Ż║²Ą─īŹļHÜv╩ĘöĄō■ųą░lŠ“│÷╚╦éā╩┬Ž╚╬┤ų¬Ą─ĪóęÄ┬╔ąįĄ─Ż¼Ą½ėų╩ŪØōį┌ėąė├Ą─Ż¼▓óŪęūŅĮK┐╔ęį└ĒĮŌĄ─ų¬ūR║═ą┼ŽóĪŻ
2 öĄō■═┌Š“╝╝ągį┌ęŲäėCRMųąĄ─æ¬ė├
2.1 ęŲäėCRM¾wŽĄĮYśŗ
ęŲäė┐═æ¶ĻPŽĄ╣▄└ĒĄ─¾wŽĄĮYśŗų„ę¬Ęų×ķ║Žū„ą═CRMĪóĘų╬÷ą═CRM ║═▓┘ū„ą═CRM ╚²éĆ▓┐ĘųŻ¼ŲõĮYśŗ╚ńłD1╦∙╩ŠĪŻ
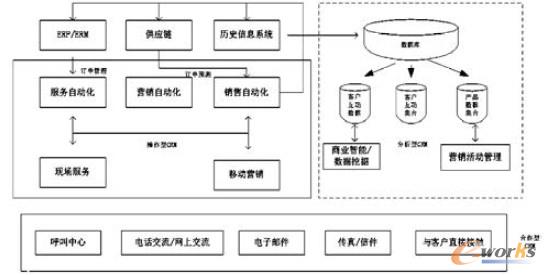
łD1 ęŲäėCRM ¾wŽĄĮYśŗłD
║Žū„ą═CRMų„ę¬ė├ė┌║Žū„Ę■äšĒŚ─┐Ż¼╦³░³└©Ą─ā╚╚▌ėą║¶Įąųąą─ĪóļŖūėÓ]╝■ĪóļŖūė╔ńģ^Ą╚Į╗┴„╩ųČ╬ĪŻĘų╬÷ą═CRM ų„ę¬Ęų╬÷į┌▓┘ū„īė┤╬Ą─öĄō■Ż¼░č▓┘ū„īėĄ─öĄō■║═┐═æ¶õN╩█▀BĮėŲüĒĪŻ▓┘ū„ą═CRM ─▄ē“īŹ¼FõN╩█┼c┐═æ¶Ę■äšśI䚥─ūįäė╗»ĪŻ
2.2 öĄō■═┌Š“╠Ä└ĒęŲäėCRMĄ─┴„│╠
ęŲäėCRM Ą─öĄō■═┌Š“┴„│╠╚ńłD2╦∙╩ŠĪŻ
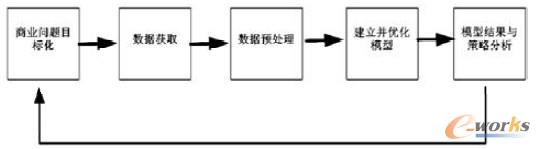
łD2 ęŲäėCRMĄ─öĄō■═┌Š“┴„│╠łD
2.3 öĄō■═┌Š“╠Ä└ĒęŲäėCRMĄ─╦ŃĘ©īŹ¼F
×ķ┴╦╩╣ęŲäė╣½╦ŠĮo┐═æ¶╠ß╣®╚½ĘĮ╬╗Ą─Ę■䚯¼═©▀^┐═æ¶įÆå╬öĄō■Ż¼▓╔ė├Ą³┤·ūįĮM┐ŚöĄō■Ęų╬÷╦ŃĘ©ī”┐═æ¶╚║¾w▀Mąą┴╦Š█ŅÉĘų╬÷Ż¼Ųõ╦ŃĘ©īŹ¼F┴„│╠╚ńŽ┬Ż║
▓Į¾E1Ż║½@Ą├╦∙ėąśėŲĘĄ─╠žš„Ż╗
▓Į¾E2Ż║▌ö╚ļķōųĄTŻ¼ĘĮ▓ŅEŻ¼ŅÉųąą─öĄ─┐CŻ¼ūŅ┤¾Ą³┤·┤╬öĄIŻ©ėŗ╦ŃöĄō■śėŲĘų«ķgĄ─ŠÓļxĪóĘĮ▓ŅĄ─ūŅąĪ║═ūŅ┤¾ųĄŻ®Ż╗
▓Į¾E3Ż║╚╬ęŌ▀x╚ĪŪ░NéĆśėŲĘ«öū÷┼RĢrĄ─Š█ŅÉųąą─M(i)Ż╗
▓Į¾E4Ż║Ū¾╦∙Ą├ĄĮĄ─Ė„éĆśėŲĘĄĮęč▀xČ©Ą─┼RĢrŠ█ŅÉųąą─Ą─ŠÓļxŻ¼īó╦∙Ą├Ą─śėŲĘÜw╚ļ▀xČ©Ą─ūŅĮ³Ą─ŅÉųąą─M(i) Ż╗
▓Į¾E5Ż║Ė∙ō■ęčĮøŠ█ŅÉĄ─ĮY╣¹Ż¼ųžą┬ėŗ╦ŃĖ„éĆŠ█ŅÉųąą─Ą─╠žš„ųąą─Ż╗
▓Į¾E6Ż║Ė∙ō■ą┬Ą─ŅÉųąą─Ż¼ųžą┬ėŗ╦ŃĖ„Š█ŅÉė“ųąĢ║ĢręčĮøŠ█ŅÉĄ─śėŲĘĄĮą┬ŅÉųąą─ķgĄ─ŠÓļxŻ¼▓óŪęėŗ╦Ń├┐ę╗ŅÉśėŲĘĄĮŠ█ŅÉųąą─Ą─ŲĮŠ∙ŠÓļxŻ╗
▓Į¾E7Ż║Ą³┤·ėŗ╦Ń│÷╦∙ėąŠ█ŅÉė“ųąĖ„éĆśėŲĘĄ─ŲĮŠ∙ŠÓļxŻ¼į┘ėŗ╦Ń│÷Ųõ┐éŲĮŠ∙ŠÓļxŻ╗
▓Į¾E8Ż║Ė∙ō■╦∙Ą├ŲĮŠ∙ŠÓļxųĄ║═ķōųĄĄ─┤¾ąĪŻ¼┼ąöÓŠ█ŅÉė“Ą─Ęų┴čĪó║Ž▓ó║═Ą³┤·Ż╗
▓Į¾E9Ż║║Ž▓ó▓┘ū„Ż¼ėŗ╦Ń╚½▓┐öĄō■Ą─Š█ŅÉųąą─Ą─ŠÓļxųĄŻ╗
▓Į¾E10Ż║Ęų┴č▓┘ū„Ż¼Ū¾│÷╦∙ėąöĄō■Ą─Š█ŅÉųąą─╦∙ōĒėąĄ─ś╦£╩▓ŅŽ“┴┐Ż¼šę│÷╦∙ėąŠ█ŅÉė“Ą─Š▀ėąųąą─ś╦£╩▓ŅūŅ┤¾ųĄĄ─Š█ŅÉė“ĪŻ
▓Į¾E11Ż║╚ń╣¹╩ŪūŅ║¾ę╗┤╬Ą³┤·▀\╦ŃätĮY╩°čŁŁhĪŻĘ±ät裣h└^└m▓Į¾E4Ż¼Ą³┤·┤╬öĄ╝ė1ĪŻ
īŹ“×ĮY╣¹▒Ē├„ęŲäėė├æ¶Ęų×ķĖ▀Ž¹┘MĮMĪóųąĖ▀Ž¹┘MĮMĪóųąĄ╚Ž¹┘MĮM║═Ą═Ž¹┘MĮM╦─ŅÉė├æ¶ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║öĄō■═┌Š“╝╝ągį┌ęŲäėCRMųąĄ─æ¬ė├