3.2.1 öĄō■│ķ╚Ī┼c╝»│╔
┤¾öĄō■Ą─ę╗éĆųžę¬╠ž³cŠ═╩ŪČÓśėąįŻ¼▀@Š═ęŌ╬Čų°öĄō■üĒį┤śOŲõÅVĘ║Ż¼öĄō■ŅÉą═śO×ķĘ▒ļsĪŻ▀@ĘNÅ═ļsĄ─öĄō■ŁhŠ│Įo┤¾öĄō■Ą─╠Ä└ĒĦüĒśO┤¾Ą─╠¶æĪŻę¬Žļ╠Ä└Ē┤¾öĄō■Ż¼╩ūŽ╚▒žĒÜī”╦∙ąĶöĄō■į┤Ą─öĄō■▀Mąą│ķ╚Ī║═╝»│╔Ż¼Å─ųą╠ß╚Ī│÷ĻPŽĄ║═īŹ¾wŻ¼Įø▀^ĻP┬ō║═Š█║Žų«║¾▓╔ė├Įyę╗Č©┴xĄ─ĮYśŗüĒ┤µā”▀@ą®öĄō■ĪŻį┌öĄō■╝»│╔║═╠ß╚ĪĢrąĶę¬ī”öĄō■▀MąąŪÕŽ┤Ż¼▒ŻūCöĄō■┘|┴┐╝░┐╔ą┼ąįĪŻ═¼Ģr▀Ćę¬╠žäeūóęŌŪ░├µ╠ß╝░Ą─┤¾öĄō■Ģr┤·─Ż╩Į║═öĄō■Ą─ĻPŽĄŻ¼┤¾öĄō■Ģr┤·Ą─öĄō■═∙═∙╩ŪŽ╚ėąöĄō■į┘ėą─Ż╩ĮŻ¼Ūę─Ż╩Į╩Ūį┌▓╗öÓĄ─äėæBč▌╗»ų«ųąĄ─ĪŻ
öĄō■│ķ╚Ī║═╝»│╔╝╝ąg▓╗╩Ūę╗ĒŚ╚½ą┬Ą─╝╝ągŻ¼é„ĮyöĄō■ÄņŅIė“ęčī”┤╦å¢Ņ}ėą┴╦▒╚▌^│╔╩ņĄ─蹊┐ĪŻļSų°ą┬Ą─öĄō■į┤Ą─ė┐¼FŻ¼öĄō■╝»│╔ĘĮĘ©ę▓į┌▓╗öÓĄ─░lš╣ų«ųąĪŻÅ─öĄō■╝»│╔─Żą═üĒ┐┤Ż¼¼FėąĄ─öĄō■│ķ╚Ī┼c╝»│╔ĘĮ╩Į┐╔ęį┤¾ų┬Ęų×ķęįŽ┬╦─ĘNŅÉą═Ż║╗∙ė┌╬’╗»╗“╩ŪETL ĘĮĘ©Ą─ę²Ūµ(Materialization or ETL engine)Īó╗∙ė┌┬ō░ŅöĄō■Äņ╗“ųąķg╝■ĘĮĘ©Ą─ę²Ūµ(Federation engine orMediator)Īó╗∙ė┌öĄō■┴„ĘĮĘ©Ą─ę²Ūµ(Stream engine)╝░ ╗∙ė┌╦č╦„ę²ŪµĄ─ĘĮĘ©(Search engine)ĪŻ
3.2.2 öĄō■Ęų╬÷
öĄō■Ęų╬÷╩Ūš¹éĆ┤¾öĄō■╠Ä└Ē┴„│╠Ą─║╦ą─Ż¼ę“×ķ┤¾öĄō■Ą─ārųĄ«a╔·ė┌Ęų╬÷▀^│╠ĪŻÅ─«ÉśŗöĄō■į┤│ķ╚Ī║═╝»│╔Ą─öĄō■śŗ│╔┴╦öĄō■Ęų╬÷Ą─įŁ╩╝öĄō■ĪŻĖ∙ō■▓╗═¼æ¬ė├Ą─ąĶŪ¾┐╔ęįÅ─▀@ą®öĄō■ųą▀xō±╚½▓┐╗“▓┐Ęų▀MąąĘų╬÷ĪŻé„ĮyĄ─Ęų╬÷╝╝ąg╚ńöĄō■═┌Š“ĪóÖCŲ„īW┴ĢĪóĮyėŗĘų╬÷Ą╚į┌┤¾öĄō■Ģr┤·ąĶę¬ū÷│÷š{š¹Ż¼ę“×ķ▀@ą®╝╝ągį┌┤¾öĄō■Ģr┤·├µ┼Rų°ę╗ą®ą┬Ą─╠¶æŻ¼ų„ę¬ėąŻ║
1ĪóöĄō■┴┐┤¾▓ó▓╗ę╗Č©ęŌ╬Čų°öĄō■ārųĄĄ─į÷╝ėŻ¼ŽÓĘ┤▀@═∙═∙ęŌ╬Čų°öĄō■įļ궥─į÷ČÓĪŻę“┤╦į┌öĄō■Ęų╬÷ų«Ū░▒žĒÜ▀MąąöĄō■ŪÕŽ┤Ą╚ŅA╠Ä└Ē╣żū„Ż¼Ą½╩ŪŅA╠Ä└Ē╚ń┤╦┤¾┴┐Ą─öĄō■ī”ė┌ÖCŲ„ė▓╝■ęį╝░╦ŃĘ©Č╝╩Ūć└Š■Ą─┐╝“×ĪŻ
2Īó┤¾öĄō■Ģr┤·Ą─╦ŃĘ©ąĶę¬▀Mąąš{š¹ĪŻ╩ūŽ╚┤¾öĄō■Ą─æ¬ė├│Ż│ŻŠ▀ėąīŹĢrąįĄ─╠ž³cŻ¼╦ŃĘ©Ą─£╩┤_┬╩▓╗į┘╩Ū┤¾öĄō■æ¬ė├Ą─ūŅų„ę¬ųĖś╦ĪŻ║▄ČÓł÷Š░ųą╦ŃĘ©ąĶę¬į┌╠Ä└ĒĄ─īŹĢrąį║═£╩┤_┬╩ų«ķg╚ĪĄ├ę╗éĆŲĮ║ŌŻ¼▒╚╚ńį┌ŠĆĄ─ÖCŲ„īW┴Ģ╦ŃĘ©(online machine learning)ĪŻŲõ┤╬įŲėŗ╦Ń╩Ū▀Mąą┤¾öĄō■╠Ä└ĒĄ─ėą┴”╣żŠ▀Ż¼▀@Š═ę¬Ū¾║▄ČÓ╦ŃĘ©▒žĒÜū÷│÷š{š¹ęį▀mæ¬įŲėŗ╦ŃĄ─┐“╝▄Ż¼╦ŃĘ©ąĶę¬ūāĄ├Š▀ėą┐╔öUš╣ąįĪŻūŅ║¾į┌▀xō±╦ŃĘ©╠Ä└Ē┤¾öĄō■Ģr▒žĒÜųö╔„Ż¼«ööĄō■┴┐į÷ķLĄĮę╗Č©ęÄ─Żęį║¾Ż¼┐╔ęįÅ─ąĪ┴┐öĄō■ųą═┌Š“│÷ėąą¦ą┼ŽóĄ─╦ŃĘ©▓óę╗Č©▀mė├ė┌┤¾öĄō■ĪŻĮyėŗīWųąĄ─░ŅĖź└╩─ßįŁ└Ē(Bonferroni’s Principle)Š═╩Ūę╗éĆĄõą═Ą─└²ūėĪŻ
3ĪóöĄō■ĮY╣¹║├ē─Ą─║Ō┴┐ĪŻĄ├ĄĮĘų╬÷ĮY╣¹▓ó▓╗ļyŻ¼Ą½╩ŪĮY╣¹║├ē─Ą─║Ō┴┐ģs╩Ū┤¾öĄō■Ģr┤·öĄō■Ęų╬÷Ą─ą┬╠¶æĪŻ┤¾öĄō■Ģr┤·Ą─öĄō■┴┐┤¾ĪóŅÉą═²ŗļsŻ¼▀MąąĘų╬÷Ą─Ģr║“═∙═∙ī”š¹éĆöĄō■Ą─Ęų▓╝╠ž³cšŲ╬šĄ─▓╗╠½ŪÕ│■Ż¼▀@Ģ■ī¦ų┬ūŅ║¾į┌įOėŗ║Ō┴┐Ą─ĘĮĘ©ęį╝░ųĖś╦Ą─Ģr║“ė÷ĄĮųTČÓ└¦ļyĪŻ┤¾öĄō■Ęų╬÷ęč▒╗ÅVĘ║æ¬ė├ė┌ųTČÓŅIė“Ż¼Ąõą═Ą─ėą═Ų╦]ŽĄĮyĪó╔╠śIųŪ─▄ĪóøQ▓▀ų¦│ųĄ╚ĪŻ
3.2.3 öĄō■ĮŌßī
öĄō■Ęų╬÷╩Ū┤¾öĄō■╠Ä└ĒĄ─║╦ą─Ż¼Ą½╩Ūė├æ¶═∙═∙Ė³ĻPą─ĮY╣¹Ą─š╣╩ŠĪŻ╚ń╣¹Ęų╬÷Ą─ĮY╣¹š²┤_Ą½╩Ūø]ėą▓╔ė├▀m«öĄ─ĮŌßīĘĮĘ©Ż¼ät╦∙Ą├ĄĮĄ─ĮY╣¹║▄┐╔─▄ūīė├æ¶ļyęį└ĒĮŌŻ¼śOČ╦ŪķørŽ┬╔§ų┴Ģ■š`ī¦ė├æ¶ĪŻöĄō■ĮŌßīĄ─ĘĮĘ©║▄ČÓŻ¼▒╚▌^é„ĮyĄ─Š═╩Ūęį╬─▒Šą╬╩Į▌ö│÷ĮY╣¹╗“š▀ų▒Įėį┌ļŖ─XĮKČ╦╔Ž’@╩ŠĮY╣¹ĪŻ▀@ĘNĘĮĘ©į┌├µī”ąĪöĄō■┴┐Ģr╩Ūę╗ĘN║▄║├Ą─▀xō±ĪŻĄ½╩Ū┤¾öĄō■Ģr┤·Ą─öĄō■Ęų╬÷ĮY╣¹═∙═∙ę▓╩Ū║Ż┴┐Ą─Ż¼═¼ĢrĮY╣¹ų«ķgĄ─ĻP┬ōĻPŽĄśOŲõÅ═ļsŻ¼▓╔ė├é„ĮyĄ─ĮŌßīĘĮĘ©╗∙▒Š▓╗┐╔ąąĪŻ
┐╔ęį┐╝æ]Å─Ž┬├µā╔éĆĘĮ├µ╠ß╔²öĄō■ĮŌßī─▄┴”ĪŻ
1Īóę²╚ļ┐╔ęĢ╗»╝╝ągĪŻ┐╔ęĢ╗»ū„×ķĮŌßī┤¾┴┐öĄō■ūŅėąą¦Ą─╩ųČ╬ų«ę╗┬╩Ž╚▒╗┐ŲīW┼c╣ż│╠ėŗ╦ŃŅIė“▓╔ė├ĪŻ═©▀^ī”Ęų╬÷ĮY╣¹Ą─┐╔ęĢ╗»ė├ą╬Ž¾Ą─ĘĮ╩ĮŽ“ė├涚╣╩ŠĮY╣¹Ż¼Č°ŪęłDą╬╗»Ą─ĘĮ╩Į▒╚╬─ūųĖ³ęū└ĒĮŌ║═Įė╩▄ĪŻ│ŻęŖĄ─┐╔ęĢ╗»╝╝ągėąś╦║×įŲ(Tag Cloud)ĪóÜv╩Ę┴„(history flow)Īó┐šķgą┼Žó┴„(Spatial information flow)Ą╚ĪŻ┐╔ęįĖ∙ō■Š▀¾wĄ─æ¬ė├ąĶę¬▀xō±║Ž▀mĄ─┐╔ęĢ╗»╝╝ągĪŻ
2Īóūīė├æ¶─▄ē“į┌ę╗Č©│╠Č╚╔Ž┴╦ĮŌ║═ģó┼cŠ▀¾wĄ─Ęų╬÷▀^│╠ĪŻ▀@éĆ╝╚┐╔ęį▓╔ė├╚╦ÖCĮ╗╗ź╝╝ągŻ¼└¹ė├Į╗╗ź╩ĮĄ─öĄō■Ęų╬÷▀^│╠üĒę²ī¦ė├æ¶ų▓ĮĄ─▀MąąĘų╬÷Ż¼╩╣Ą├ė├æ¶į┌Ą├ĄĮĮY╣¹Ą─═¼ĢrĖ³║├Ą─└ĒĮŌĘų╬÷ĮY╣¹Ą─ė╔üĒĪŻę▓┐╔ęį▓╔ė├öĄō■Ųį┤╝╝ągŻ¼═©▀^įō╝╝ąg┐╔ęįÄ═ų·ūĘ╦▌š¹éĆöĄō■Ęų╬÷Ą─▀^│╠Ż¼ėąų·ė┌ė├æ¶└ĒĮŌĮY╣¹ĪŻ
4ĪóĻPµI╝╝ągĘų╬÷
┤¾öĄō■ārųĄĄ─═Ļš¹¾w¼FąĶę¬ČÓĘN╝╝ągĄ─ģf═¼ĪŻ╬─╝■ŽĄĮy╠ß╣®ūŅĄūīė┤µā”─▄┴”Ą─ų¦│ųĪŻ×ķ┴╦▒Ńė┌öĄō■╣▄└ĒŻ¼ąĶę¬į┌╬─╝■ŽĄĮyų«╔ŽĮ©┴óöĄō■ÄņŽĄĮyĪŻ═©▀^╦„ę²Ą╚Ą─śŗĮ©Ż¼ī”═Ō╠ß╣®Ė▀ą¦Ą─öĄō■▓ķįāĄ╚│Żė├╣”─▄ĪŻūŅĮK═©▀^öĄō■Ęų╬÷╝╝ągÅ─öĄō■ÄņųąĄ─┤¾öĄō■╠ß╚Ī│÷ėąęµĄ─ų¬ūRĪŻ
4.1 įŲėŗ╦ŃŻ║┤¾öĄō■Ą─╗∙ĄAŲĮ┼_┼cų¦ō╬╝╝ąg
╚ń╣¹īóĖ„ĘN┤¾öĄō■Ą─æ¬ė├▒╚ū„ę╗▌v▌v“Ų¹▄攥─įÆŻ¼ų¦ō╬Ų▀@ą®“Ų¹▄ć”▀\ąąĄ─“Ė▀╦┘╣½┬Ę”Š═╩ŪįŲėŗ╦ŃĪŻš²╩ŪįŲėŗ╦Ń╝╝ągį┌öĄō■┤µā”Īó╣▄└Ē┼cĘų╬÷Ą╚ĘĮ├µĄ─ų¦ō╬Ż¼▓┼╩╣Ą├┤¾öĄō■ėąė├╬õų«ĄžĪŻ
į┌╦∙ėąĄ─“Ė▀╦┘╣½┬Ę”ųąŻ¼Google ¤oę╔╩Ū╝╝ągūŅ×ķŽ╚▀MĄ─ę╗éĆĪŻąĶŪ¾═Ųäėäōą┬Ż¼├µī”║Ż┴┐Ą─Web öĄō■Ż¼ Google ė┌2006 ─Ļ╩ūŽ╚╠ß│÷┴╦įŲėŗ╦ŃĄ─Ė┼─ŅĪŻų¦ō╬Google ā╚▓┐Ė„ĘN┤¾öĄō■æ¬ė├Ą─š²╩ŪŲõūįąąčą░lĄ─ę╗ŽĄ┴ąįŲėŗ╦Ń╝╝ąg║═╣żŠ▀ĪŻļy─▄┐╔┘FĄ─╩ŪGoogle ▓ó╬┤īó▀@ą®╝╝ąg═Ļ╚½ĘŌķ]Ż¼Č°╩Ūęįšō╬─Ą─ą╬╩Įų▓Į╣½ķ_ŲõīŹ¼FĪŻš²╩Ū▀@ą®╣½ķ_Ą─šō╬─Ż¼╩╣Ą├ęįGFSĪóMapReduceĪóBigtable ×ķ┤·▒ĒĄ─ę╗ŽĄ┴ą┤¾öĄō■╠Ä└Ē╝╝ąg▒╗ÅVĘ║┴╦ĮŌ▓óĄ├ĄĮæ¬ė├Ż¼═¼Ģr▀Ć┤▀╔·│÷ęįHadoop×ķ┤·▒ĒĄ─ę╗ŽĄ┴ąįŲėŗ╦Ńķ_į┤╣żŠ▀ĪŻįŲėŗ╦Ń╝╝ąg║▄ČÓŻ¼Ą½╩Ū═©▀^Google įŲėŗ╦Ń╝╝ągĄ─ĮķĮB─▄ē“┐ņ╦┘Īó═Ļš¹Ą─░č╬šįŲėŗ╦Ń╝╝ągĄ─║╦ą─║═Š½╦ĶĪŻ▒Š╣ØęįGoogle Ą─ŽÓĻP╝╝ągĮķĮB×ķų„ŠĆŻ¼įö╝ÜĮķĮBGoogle ęį╝░Ųõ╦¹▒ŖČÓīWš▀║═蹊┐ÖCśŗį┌┤¾öĄō■╝╝ągĘĮ├µęčėąĄ─ę╗ą®╣żū„ĪŻĖ∙ō■Google ęč╣½ķ_Ą─šō╬─╝░ŽÓĻP┘Y┴ŽŻ¼ĮY║Ž┤¾öĄō■╠Ä└ĒĄ─ąĶŪ¾Ż¼╬ęéāī”Google Ą─╝╝ągč▌╗»▀Mąą┴╦š¹└ĒŻ¼╚ńłD4╦∙╩ŠŻ║
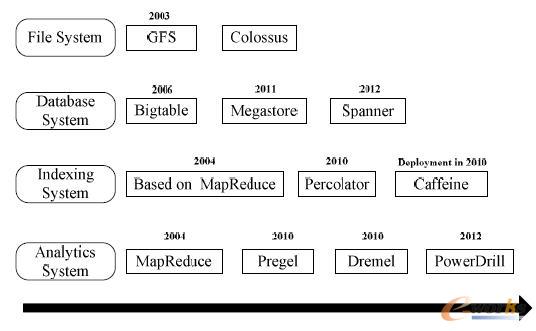
łD 4 Google ╝╝ągč▌╗»łD
4.1.1 ╬─╝■ŽĄĮy
╬─╝■ŽĄĮy╩Ūų¦ō╬╔Žīėæ¬ė├Ą─╗∙ĄAĪŻį┌Google ų«Ū░Ż¼╔ą╬┤ėą──éĆ╣½╦Š├µī”▀^╚ń┤╦ČÓĄ─║Ż┴┐öĄō■ĪŻę“┤╦ī”ė┌Google Č°čį▓óø]ėą═Ļ╚½│╔╩ņĄ─┤µā”ĘĮ░Ė┐╔ęįų▒Įė╩╣ė├ĪŻGoogle šJ×ķŽĄĮyĮM╝■╩¦öĪ╩Ūę╗ĘN│ŻæBČ°▓╗╩Ū«É│ŻŻ¼╗∙ė┌┤╦╦╝ŽļGoogle ūįąąįOėŗķ_░l┴╦Google ╬─╝■ŽĄĮyGFS(Google File System)ĪŻGFS ╩ŪśŗĮ©į┌┤¾┴┐┴«ārĘ■äšŲ„ų«╔ŽĄ─ę╗éĆ┐╔öUš╣Ą─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼GFS ų„ę¬ßśī”╬─╝■▌^┤¾Ż¼Ūęūx▀h┤¾ė┌īæĄ─æ¬ė├ł÷Š░Ż¼▓╔ė├ų„Å─(Master-Slave)ĮYśŗĪŻ═©▀^öĄō■ĘųēKĪóūĘ╝ėĖ³ą┬(Append-Only)Ą╚ĘĮ╩ĮīŹ¼F┴╦║Ż┴┐öĄō■Ą─Ė▀ą¦┤µā”ĪŻļSų°Ģrķg═ŲęŲŻ¼GFS Ą─╝▄śŗųØuķ_╩╝¤oĘ©▀mæ¬ąĶŪ¾ĪŻGoogle ī”GFS ▀Mąą┴╦ųžą┬Ą─įOėŗŻ¼įōŽĄĮyš²╩ĮĄ─├¹ĘQ×ķColosussŻ¼Š▀¾wīŹ¼F╔ą╬┤╣½ķ_Ż¼Ą½╩ŪÅ─ACM ī”GFS łFĻĀ║╦ą─╣ż│╠ĤĄ─įLšä┐╔ęį┴╦ĮŌŲõę╗ą®ą┬Ą─╠žąįĪŻŲõųąGFS Ą─å╬³c╣╩šŽ(ųĖāHėąę╗éĆų„╣سc╚▌ęū│╔×ķŽĄĮyĄ─Ų┐Ņi)Īó║Ż┴┐ąĪ╬─╝■Ą─┤µā”Ą╚å¢Ņ}į┌Colosuss ųąŠ∙Ą├ĄĮ┴╦ĮŌøQĪŻ
│²┴╦GoogleŻ¼▒ŖČÓŲ¾śI║═īWš▀ę▓Å─▓╗═¼ĘĮ├µī”ØMūŃ┤¾öĄō■┤µā”ąĶŪ¾Ą─╬─╝■ŽĄĮy▀Mąą┴╦įö▒MĄ─蹊┐ĪŻ╬ó▄øūįąąķ_░lĄ─Cosmosų¦ō╬ų°Ųõ╦č╦„ĪóÅVĖµĄ╚śIäšĪŻHDFS║═CloudStoreČ╝╩Ū─ŻĘ┬GFS Ą─ķ_į┤īŹ¼FĪŻGFS ŅÉĄ─╬─╝■ŽĄĮyų„ę¬╩Ūßśī”▌^┤¾╬─╝■įOėŗĄ─Ż¼Č°į┌łDŲ¼┤µā”Ą╚æ¬ė├ł÷Š░Ż¼╬─╝■ŽĄĮyų„ę¬┤µā”║Ż┴┐ąĪ╬─╝■Ż¼┤╦ĢrGFS Ą╚╬─╝■ŽĄĮyę“×ķŅlĘ▒ūx╚Īį¬öĄō■Ą╚įŁę“Ż¼ą¦┬╩║▄Ą═ĪŻßśī”▀@ĘNŪķørŻ¼Facebook ═Ų│÷┴╦īŻķTßśī”║Ż┴┐ąĪ╬─╝■Ą─╬─╝■ŽĄĮyHaystackŻ¼═©▀^ČÓéĆ▀ē▌ŗ╬─╝■╣▓ŽĒ═¼ę╗éĆ╬’└Ē╬─╝■Īóį÷╝ėŠÅ┤µīėĪó▓┐Ęųį¬öĄō■╝ė▌dĄĮā╚┤µĄ╚ĘĮ╩Įėąą¦Ą─ĮŌøQ┴╦Facebook ║Ż┴┐łDŲ¼┤µā”å¢Ņ}ĪŻ╠įīÜ═Ų│÷┴╦ŅÉ╦ŲĄ─╬─╝■ŽĄĮyTFS(Tao File System)Ż¼═©▀^īóąĪ╬─╝■║Ž▓ó│╔┤¾╬─╝■Īó╬─╝■├¹ļ[║¼▓┐Ęųį¬öĄō■Ą╚ĘĮ╩ĮīŹ¼F┴╦║Ż┴┐ąĪ╬─╝■Ą─Ė▀ą¦┤µā”ĪŻFastDFSßśī”ąĪ╬─╝■Ą─ā×╗»ŅÉ╦Ųė┌TFSĪŻ
4.1.2 öĄō■ÄņŽĄĮy
įŁ╩╝Ą─öĄō■┤µā”į┌╬─╝■ŽĄĮyų«ųąŻ¼Ą½╩Ūė├æ¶┴ĢæT═©▀^öĄō■ÄņŽĄĮyüĒ┤µ╚Ī╬─╝■ĪŻę“×ķ▀@śėĢ■Ų┴▒╬Ą¶ĄūīėĄ─╝Ü╣ØŻ¼ŪęĘĮ▒ŃöĄō■╣▄└ĒĪŻų▒Įė▓╔ė├ĻPŽĄ─Żą═Ą─Ęų▓╝╩ĮöĄō■Äņ▓ó▓╗─▄▀mæ¬┤¾öĄō■Ģr┤·Ą─öĄō■┤µā”Ż¼ų„ę¬ę“×ķŻ║
1)ęÄ─Żą¦æ¬╦∙ĦüĒĄ─ē║┴”ĪŻ┤¾öĄō■Ģr┤·Ą─öĄō■┴┐▀h▀h│¼▀^å╬ÖC╦∙─▄╚▌╝{Ą─öĄō■┴┐Ż¼ę“┤╦▒žĒÜ▓╔ė├Ęų▓╝╩Į┤µā”Ą─ĘĮ╩ĮĪŻ▀@Š═ąĶꬎĄĮyŠ▀ėą║▄║├Ą─öUš╣ąįŻ¼Ą½▀@ŪĪŪĪ╩Ūé„ĮyöĄō■ÄņĄ─╚§ä▌ų«ę╗ĪŻę“×ķé„ĮyĄ─öĄō■Äņ«aŲĘī”ė┌ąį─▄Ą─öUš╣Ė³āAŽ“ė┌Scale-Up(┐vŽ“öUš╣)Ą─ĘĮ╩ĮŻ¼Č°▀@ĘNĘĮ╩Įī”ė┌ąį─▄Ą─į÷╝ė╦┘Č╚▀hĄ═ė┌ąĶę¬╠Ä└ĒöĄō■Ą─į÷ķL╦┘Č╚Ż¼Ūęąį─▄╠ß╔²┤µį┌╔ŽŽ▐ĪŻ▀mæ¬┤¾öĄō■Ą─öĄō■ÄņŽĄĮy欫öŠ▀ėą┴╝║├Ą─Scale-Out(ÖMŽ“öUš╣)─▄┴”Ż¼Č°▀@ĘNąį─▄öUš╣ĘĮ╩ĮŪĪŪĪ╩Ūé„ĮyöĄō■Äņ╦∙▓╗Š▀éõĄ─ĪŻ╝┤▒Ń╩Ūąį─▄ūŅ║├Ą─▓óąąöĄō■Äņ«aŲĘŲõScale-Out ─▄┴”ę▓ŽÓī”ėąŽ▐ĪŻ
2)öĄō■ŅÉą═Ą─ČÓśė╗»ĪŻé„ĮyĄ─öĄō■Äņ▒╚▌^▀m║ŽĮYśŗ╗»öĄō■Ą─┤µā”Ż¼Ą½╩ŪöĄō■Ą─ČÓśėąį╩Ū┤¾öĄō■Ģr┤·Ą─’@ų°╠žš„ų«ę╗ĪŻ▀@ę▓Š═╩ŪęŌ╬Čų°│²┴╦ĮYśŗ╗»öĄō■Ż¼░ļĮYśŗ╗»║═ĘŪĮYśŗ╗»öĄō■ę▓īó╩Ū┤¾öĄō■Ģr┤·Ą─ųžę¬öĄō■ŅÉą═ĮM│╔▓┐ĘųĪŻ╚ń║╬Ė▀ą¦Ą─╠Ä└ĒČÓĘNöĄō■ŅÉą═╩Ū┤¾öĄō■Ģr┤·öĄō■Äņ╝╝ąg├µ┼RĄ─ųžę¬╠¶æų«ę╗ĪŻ
3)įOėŗ└Ē─ŅĄ─ø_═╗ĪŻĻPŽĄöĄō■ÄņūĘŪ¾Ą─╩Ū“One size fits all”Ą──┐ś╦Ż¼ŽŻ═¹īóė├æ¶Å─Ę▒ļsĄ─öĄō■╣▄└ĒųąĮŌ├ō│÷üĒŻ¼į┌├µī”▓╗═¼Ą─å¢Ņ}Ģr▓╗ąĶę¬ųžą┬┐╝æ]öĄō■╣▄└Ēå¢Ņ}Ż¼Å─Č°┐╔ęįīóųžą─▐DŽ“Ųõ╦¹Ą─▓┐ĘųĪŻĄ½į┌┤¾öĄō■Ģr┤·▓╗═¼Ą─æ¬ė├ŅIė“į┌öĄō■ŅÉą═ĪóöĄō■╠Ä└ĒĘĮ╩Įęį╝░öĄō■╠Ä└ĒĢrķgĄ─ę¬Ū¾╔ŽėąśO┤¾Ą─▓Ņ«ÉĪŻį┌īŹļHĄ─╠Ä└ĒųąÄū║§▓╗┐╔─▄ėąę╗ĘNĮyę╗Ą─öĄō■┤µā”ĘĮ╩Į─▄ē“æ¬ī”╦∙ėął÷Š░ĪŻ▒╚╚ńī”ė┌║Ż┴┐Web öĄō■Ą─╠Ä└ĒŠ═▓╗┐╔─▄║═╠ņ╬─łDŽ±öĄō■▓╔╚Ī═¼śėĄ─╠Ä└ĒĘĮ╩ĮĪŻį┌▀@ĘNŪķørŽ┬Ż¼║▄ČÓ╣½╦Šķ_╩╝ćLįćÅ─“One size fits one”║═“One size fits domain”Ą─įOėŗ└Ē─Ņ│÷░lüĒ蹊┐ą┬Ą─öĄō■╣▄└ĒĘĮ╩ĮŻ¼▓ó«a╔·┴╦ę╗ŽĄ┴ąĘŪ│Żėą┤·▒ĒąįĄ─╣żū„ĪŻ
4)öĄō■Äņ╩┬äš╠žąįĪŻ▒Ŗ╦∙ų▄ų¬ĻPŽĄöĄō■Äņųą╩┬䚥─š²┤_ł╠ąą▒žĒÜØMūŃACID ╠žąįŻ¼╝┤įŁūėąį(Atomicity)Īóę╗ų┬ąį(Consistency)ĪóĖ¶ļxąį(Isolation)║═│ųŠ├ąį(Durability)ĪŻī”ė┌öĄō■ÅŖę╗ų┬ąįĄ─ć└Ė±ę¬Ū¾╩╣Ųõį┌║▄ČÓ┤¾öĄō■ł÷Š░ųą¤oĘ©æ¬ė├ĪŻ▀@ĘNŪķørŽ┬│÷¼F┴╦ą┬Ą─BASE ╠žąįŻ¼╝┤ų╗ę¬Ū¾ØMūŃBasically Available(╗∙▒Š┐╔ė├), Soft state(╚ßąįĀŅæB)║═ Eventually consistent(ūŅĮKę╗ų┬)ĪŻÅ─Ęų▓╝╩ĮŅIė“ų°├¹Ą─CAP └ĒšōĄ─ĮŪČ╚üĒ┐┤Ż¼ACID ūĘŪ¾ę╗ų┬ąįCŻ¼Č°BASEĖ³╝ėĻPūó┐╔ė├ąįAĪŻš²╩Ūį┌╩┬äš╠Ä└Ē▀^│╠ųąī”ė┌ACID ╠žąįĄ─ć└Ė±ę¬Ū¾Ż¼╩╣Ą├ĻPŽĄą═öĄō■ÄņĄ─┐╔öUš╣ąįśOŲõėąŽ▐ĪŻ
├µī”▀@ą®╠¶æŻ¼ęįGoogle ×ķ┤·▒ĒĄ─ę╗┼·╝╝ąg╣½╦Š╝Ŗ╝Ŗ═Ų│÷┴╦ūį╝║Ą─ĮŌøQĘĮ░ĖĪŻBigtable╩ŪGoogle įńŲ┌ķ_░lĄ─öĄō■ÄņŽĄĮyŻ¼╦³╩Ūę╗éĆČÓŠSŽĪ╩Ķ┼┼ą“▒ĒŻ¼ė╔ąą║═┴ąĮM│╔Ż¼├┐éĆ┤µā”å╬į¬Č╝ėąę╗éĆĢrķg┤┴Ż¼ą╬│╔╚²ŠSĮYśŗĪŻ▓╗═¼Ą─Ģrķgī”═¼ę╗éĆöĄō■å╬į¬Ą─ČÓéĆ▓┘ū„ą╬│╔Ą─öĄō■Ą─ČÓéĆ░µ▒Šų«ķgė╔Ģrķg┤┴üĒģ^ĘųĪŻ│²┴╦BigtableŻ¼Amazon Ą─Dynamo║═Yahoo Ą─PNUTSę▓Č╝╩ŪĘŪ│ŻŠ▀ėą┤·▒ĒąįĄ─ŽĄĮyĪŻDynamo ŠC║Ž╩╣ė├┴╦µI/ųĄ┤µā”ĪóĖ─▀MĄ─Ęų▓╝╩Į╣■ŽŻ▒Ē(DHT)ĪóŽ“┴┐ĢrńŖ(Vector Clock)Ą╚╝╝ągīŹ¼F┴╦ę╗éĆ═Ļ╚½Ą─Ęų▓╝╩ĮĪó╚źųąą─╗»Ą─Ė▀┐╔ė├ŽĄĮyĪŻPNUTS╩Ūę╗éĆĘų▓╝╩ĮĄ─öĄō■ÄņŻ¼į┌įOėŗ╔Ž╩╣ė├╚§ę╗ų┬ąįüĒ▀_ĄĮĖ▀┐╔ė├ąįĄ──┐ś╦Ż¼ų„ꬥ─Ę■äšī”Ž¾╩ŪŽÓī”▌^ąĪĄ─ėøõøŻ¼▒╚╚ńį┌ŠĆĄ─┤¾┴┐å╬éĆėøõø╗“š▀ąĪĘČć·ėøõø╝»║ŽĄ─ūx║═īæįLå¢ĪŻ▓╗▀m║Ž┤µā”┤¾╬─╝■Īó┴„├Į¾wĄ╚ĪŻBigtableĪóDynamoĪóPNUTS Ą╚Ą─│╔╣”┤┘╩╣╚╦éāķ_╩╝ī”ĻPŽĄöĄō■Äņ▀MąąĘ┤╦╝Ż¼ė╔┤╦«a╔·┴╦ę╗┼·╬┤▓╔ė├ĻPŽĄ─Żą═Ą─öĄō■ÄņŻ¼▀@ą®ĘĮ░Ė¼Fį┌▒╗Įyę╗Ą─ĘQ×ķNoSQL(NotOnly SQL)ĪŻNoSQL ▓óø]ėąę╗éĆ£╩┤_Ą─Č©┴xŻ¼Ą½ę╗░ŃšJ×ķNoSQL öĄō■Äņ欫öŠ▀ėąęįŽ┬Ą─╠žš„Ż║─Ż╩Įūįė╔(schema-free)Īóų¦│ų║åęūéõĘ▌(easy replication support)Īó║åå╬Ą─æ¬ė├│╠ą“Įė┐┌(simple API)ĪóūŅĮKę╗ų┬ąį(╗“š▀šfų¦│ųBASE ╠žąįŻ¼▓╗ų¦│ųACID)Īóų¦│ų║Ż┴┐öĄō■(Huge amountof data)ĪŻNoSQL ║═ĻPŽĄą═öĄō■ÄņĄ─║åå╬▒╚▌^╚ń▒Ē3 ╦∙╩ŠŻ║
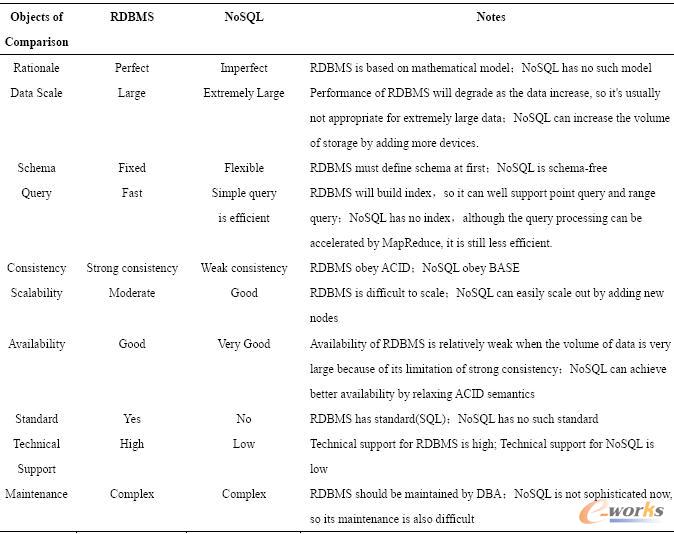
▒Ē3 NoSQL öĄō■Äņ║═ĻPŽĄöĄō■ÄņĄ─ī”▒╚
Ąõą═Ą─NoSQL öĄō■ÄņĘųŅÉ╚ń▒Ē4╦∙╩ŠŻ║
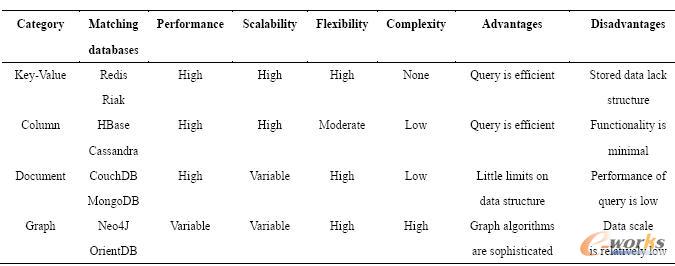
▒Ē4 Ąõą═NoSQL öĄō■Äņ
Bigtable Ą──Żą═║åå╬Ż¼Ą½╩ŪŽÓ▌^é„ĮyĄ─ĻPŽĄöĄō■ÄņŲõų¦│ųĄ─╣”─▄ĘŪ│ŻėąŽ▐Ż¼▓╗ų¦│ųACID╠žąįĪŻę“┤╦Google ķ_░l┴╦Megastore]ŽĄĮyŻ¼ļm╚╗ŲõĄūīėöĄō■┤µā”ę└┘ćBigtableŻ¼Ą½╩Ū╦³īŹ¼F┴╦ŅÉ╦ŲRDBMS Ą─öĄō■─Żą═Ż¼═¼Ģr╠ß╣®öĄō■Ą─ÅŖę╗ų┬ąįĮŌøQĘĮ░ĖĪŻMegastore īóöĄō■▀Mąą╝Ü┴ŻČ╚Ą─Ęųģ^Ż¼öĄō■Ė³ą┬Ģ■į┌ÖCĘ┐ķg▀Mąą═¼▓ĮÅ═ųŲĪŻSpanner╩Ūęčų¬Ą─Google Ą─ūŅą┬Ą─öĄō■ÄņŽĄĮyŻ¼Google į┌OSDI2012 ╔Ž╣½ķ_┴╦Spanner Ą─īŹ¼FĪŻSpanner ╩ŪĄ┌ę╗éĆ┐╔ęįīŹ¼F╚½Ū“ęÄ─ŻöUš╣(Global Scale)▓óŪęų¦│ų═Ō▓┐ę╗ų┬Ą─╩┬äš(support externally-consistent distributedtransactions)Ą─öĄō■ÄņĪŻ═©▀^GPS ║═įŁūėĢrńŖ(atomic clocks)╝╝ągŻ¼Spanner īŹ¼F┴╦ę╗éĆĢrķgAPIĪŻĮĶų·įōAPIŻ¼öĄō■ųąą─ų«ķgĄ─Ģrķg═¼▓Į─▄ē“Š½┤_ĄĮ10ms ęįā╚ĪŻSpanner ŅÉ╦Ųė┌BigtableŻ¼Ą½╩Ū╦³Š▀ėąīė┤╬ąįĄ──┐õøĮYśŗęį╝░╝Ü┴ŻČ╚Ą─öĄō■Å═ųŲĪŻī”ė┌öĄō■ųąą─ų«ķg▓╗═¼▓┘ū„Ģ■Ęųäeų¦│ųÅŖę╗ų┬ąį╗“╚§ę╗ų┬ąįŻ¼Ūęų¦│ųĖ³ČÓĄ─ūįäė▓┘ū„ĪŻSpanner Ą──┐ś╦╩Ū┐žųŲę╗░┘╚fĄĮę╗Ū¦╚f┼_Ę■äšŲ„Ż¼ūŅČÓ░³║¼┤¾╝s10╚fā|─┐õø║═ę╗Ū¦╚fā|ūų╣ØĄ─┤µā”┐šķgĪŻ┴Ē═Ōį┌SIGMOD2012╔ŽŻ¼Google ╣½ķ_┴╦ė├ė┌ŲõÅVĖµŽĄĮyĄ─ą┬öĄō■Äņ«aŲĘF1Ż¼ū„×ķę╗ĘN╗ņ║Žą═öĄō■ÄņF1 ╚┌║Ž╝µėąBigtableĄ─Ė▀öUš╣ąįęį╝░SQLöĄō■ÄņĄ─┐╔ė├ąį║═╣”─▄ąįĪŻįō«aŲĘĄ─Ąūīė┤µā”š²╩Ū▓╔ė├SpannerŻ¼Š▀ėą║▄ČÓą┬Ą─╠žąįŻ¼░³└©╚½ŠųĘų▓╝╩ĮĪó═¼▓Į┐ńöĄō■ųąą─Å═ųŲĪó┐╔ęĢĘųŲ¼║═öĄō■ęŲäėĪó│ŻęÄ╩┬䚥╚ĪŻ
ėąą®▒╚▌^╝ż▀MĄ─ė^³cšJ×ķ“ĻPŽĄöĄō■Äņęč╦└”Ż¼╬ęéāšJ×ķĻPŽĄöĄō■Äņ║═NoSQL ▓ó▓╗╩Ū├¼Č▄Ą─ī”┴ó¾wŻ¼Č°╩Ū┐╔ęįŽÓ╗źča│õĄ─Īó▀mė├ė┌▓╗═¼æ¬ė├ł÷Š░Ą─╝╝ągĪŻ└²╚ńīŹļHĄ─╗ź┬ōŠWŽĄĮy═∙═∙Č╝╩ŪACID ║═BASE ā╔ĘNŽĄĮyĄ─ĮY║ŽĪŻĮ³ą®─ĻüĒŻ¼ęįSpanner ×ķ┤·▒ĒĄ─╚¶Ė╔ą┬ą═öĄō■ÄņĄ─│÷¼FŻ¼ĮoöĄō■┤µā”ĦüĒ┴╦SQLĪóNoSQL ų«═ŌĄ─ą┬╦╝┬ĘĪŻ▀@ĘN╚┌║Ž┴╦ę╗ų┬ąį║═┐╔ė├ąįĄ─NewSQL ╗“įSĢ■╩Ū╬┤üĒ┤¾öĄō■┤µā”ą┬Ą─░lš╣ĘĮŽ“ĪŻ
4.1.3 ╦„ę²┼c▓ķįā╝╝ąg
öĄō■▓ķįā╩ŪöĄō■ÄņūŅųžę¬Ą─æ¬ė├ų«ę╗ĪŻČ°╦„ę²ät╩ŪĮŌøQöĄō■▓ķįāå¢Ņ}Ą─ėąą¦ĘĮ░ĖĪŻŠ═Google ūį╔ĒČ°čįŻ¼╦„ę²Ą─śŗĮ©╩Ū╠ß╣®╦č╦„Ę■䚥─ĻPµI▓┐ĘųĪŻGoogle ūŅįńĄ─╦„ę²ŽĄĮy╩Ū└¹ė├MapReduce üĒĖ³ą┬Ą─ĪŻĖ∙ō■Ė³ą┬Ņl┬╩▀Mąąīė┤╬äØĘųŻ¼▓╗═¼Ą─īė┤╬ī”æ¬▓╗═¼Ą─Ė³ą┬Ņl┬╩ĪŻ├┐┤╬ąĶę¬┼·┴┐Ė³ą┬╦„ę²Ż¼╝┤╩╣ėąą®öĄō■▓ó╬┤Ė─ūāę▓ąĶę¬╠Ä└ĒĄ¶ĪŻ▀@ĘN╦„ę²Ė³ą┬ĘĮ╩Įą¦┬╩▌^Ą═ĪŻļS║¾Google ╠ß│÷┴╦PercolatorŻ¼▀@╩Ūę╗ĘNį÷┴┐╩ĮĄ─╦„ę²Ė³ą┬Ų„Ż¼├┐┤╬Ė³ą┬▓╗ąĶę¬╠µōQ╦∙ėąĄ─╦„ę²öĄō■Ż¼ą¦┬╩┤¾┤¾╠ßĖ▀ĪŻļm╚╗▓╗╩Ū╦∙ėąĄ─┤¾öĄō■æ¬ė├Č╝ąĶę¬╦„ę²Ż¼Ą½╩Ū▀@ĘNį÷┴┐ėŗ╦ŃĄ─╦╝ŽļĘŪ│ŻųĄĄ├╬ęéāĮĶĶbĪŻGoogle «öŪ░š²į┌╩╣ė├Ą─╦„ę²ŽĄĮy×ķCaffeineŻ¼ŲõŠ▀¾wīŹ¼F╔ą╬┤╣½▓╝ĪŻĄ½╩Ū┐╔ęį┤_Č©Caffeine ╩ŪśŗĮ©į┌Spanner ų«╔ŽŻ¼▓╔ė├Percolator Ė³ą┬╦„ę²ĪŻą¦┬╩ŽÓ▌^╔Žę╗┤·╦„ę²ŽĄĮyČ°čįėą┤¾Ę∙Č╚╠ßĖ▀ĪŻ
ĻPŽĄöĄō■Äņę▓╩Ū└¹ė├ī”öĄō■śŗĮ©╦„ę²Ą─ĘĮ╩Į▌^║├Ą─ĮŌøQ┴╦öĄō■▓ķįāĄ─å¢Ņ}ĪŻ▓╗═¼Ą─╦„ę²ĘĮ░Ė╩╣Ą├ĻPŽĄöĄō■Äņ┐╔ęįØMūŃ▓╗═¼ł÷Š░Ą─ę¬Ū¾ĪŻ╦„ę²Ą─Į©┴óęį╝░Ė³ą┬Č╝Ģ■║─┘M▌^ČÓĄ─ĢrķgŻ¼į┌├µī”é„ĮyöĄō■ÄņĄ─ąĪöĄō■┴┐Ģr▀@ą®Ģrķg║═Ųõ╦∙ĦüĒĄ─▓ķįā▒Ń└¹ąįŽÓ▒╚╩Ū┐╔ęįĮė╩▄Ą─Ż¼Ą½╩Ū▀@ą®Å═ļsĄ─╦„ę²ĘĮ░Ė╗∙▒Š¤oĘ©ų▒Įėæ¬ė├ĄĮ┤¾öĄō■ų«╔ŽĪŻ▒Ē5╩Ūī”ę╗ą®╦„ę²ĘĮ░Ėų▒Įėæ¬ė├į┌Facebook ╔ŽĄ─ąį─▄╣└ėŗŻ║
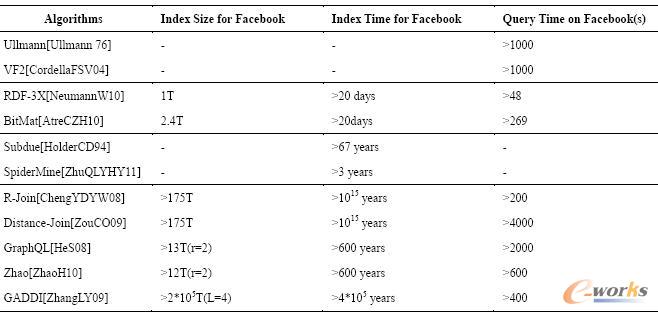
▒Ē5 ▓ķįā╦„ę²Ą─░Ė└²
Å─╔Ž▒Ē┐╔ęį┐┤│÷▓╗╠½┐╔─▄īóęčėąĄ─│╔╩ņ╦„ę²ĘĮ░Ėų▒Įėæ¬ė├ė┌┤¾öĄō■ĪŻNoSQL öĄō■Äņßśī”ų„µIĄ─▓ķįāą¦┬╩ę╗░Ń▌^Ė▀Ż¼ę“┤╦ėąĻPĄ─蹊┐╝»ųąį┌NoSQL öĄō■ÄņĄ─ČÓųĄ▓ķįāā×╗»╔ŽĪŻßśī”NoSQL öĄō■Äņ╔ŽĄ─▓ķįāā×╗»čąŠ┐ų„ę¬ėąā╔ĘN╦╝┬ĘŻ║
1Īó▓╔ė├MapReduce ▓óąą╝╝ągā×╗»ČÓųĄ▓ķįāŻ║«ö└¹ė├MapReduce ▓óąą▓ķįāNoSQL öĄō■ÄņĢrŻ¼├┐éĆMapTask ╠Ä└Ēę╗▓┐ĘųĄ─▓ķįā▓┘ū„Ż¼═©▀^īŹ¼FČÓéĆ▓┐Ęųų«ķgĄ─▓óąą▓ķįāüĒ╠ßĖ▀ČÓųĄ▓ķįāĄ─ą¦┬╩ĪŻ┤╦Ģr├┐éĆ▓┐ĘųĄ─ā╚▓┐╚į┼fąĶę¬▀MąąöĄō■Ą─╚½Æ▀├ĶĪŻ
2Īó▓╔ė├╦„ę²╝╝ągā×╗»ČÓųĄ▓ķįāŻ║║▄ČÓĄ─蹊┐╣żū„ćLįćÅ─╠Ē╝ėČÓŠS╦„ę²Ą─ĮŪČ╚üĒ╝ė╦┘NoSQL öĄō■ÄņĄ─▓ķįā╦┘Č╚ĪŻ▒Ē6 ┴ą┼e┴╦ęčėąĄ─ę╗ą®ĮŌøQĘĮ░ĖĄ─ī”▒╚ĪŻ
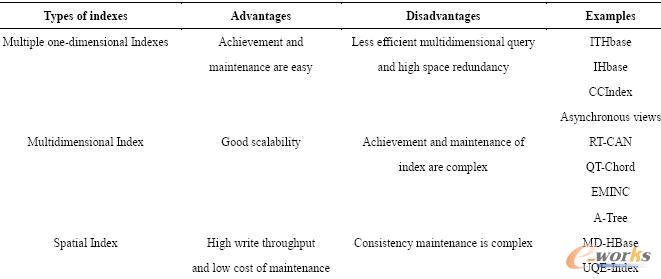
▒Ē6 ▓╔ė├╦„ę²╝ė╦┘ČÓųĄ▓ķįāĄ─ĘĮ░Ėī”▒╚
ITHbaseĪóIHbaseĪóCCIndex║═Asynchronous views╩ŪĄõą═Ą─▓╔ė├ČÓéĆę╗ŠSČ■╝ē╦„ę²üĒ╝ė╦┘ČÓųĄ▓ķįāā×╗»Ą─īŹ¼FĘĮ░ĖĪŻŲõųąITHbase ║═IHbase ╩Ūā╔éĆķ_į┤Ą─īŹ¼FĘĮ░ĖŻ¼ITHbase ų„ę¬ĻPūóė┌öĄō■ę╗ų┬ąįŻ¼╩┬äšąį╩ŪŲõųžę¬╠žąįĪŻIHbase┼cITHbaseŅÉ╦ŲŻ¼Å─HBase į┤┤a╝ēäe▀Mąą┴╦öUš╣Ż¼ųžą┬Č©┴x║═īŹ¼F┴╦ServerĪóClient Č╦╠Ä└Ē▀ē▌ŗĪŻCCIndex (ComplementalClustering Index)╩Ūųą┐Ųį║╠ß│÷Ą─┴Ē═Ōę╗ĘN╦„ę²ĮYśŗŻ¼╦³į┌╦„ę²ųą╝╚┤µā”╦„ę²ĒŚŻ¼ę▓┤µā”ėøõøĄ─Ųõ╦¹┴ąĄ─öĄō■Ż¼ęį▒Ńį┌▓ķįāĄ─Ģr║“ų▒Įėį┌╦„ę²▒Ēųą═©▀^Ēśą“Æ▀├ĶšęĄĮŽÓæ¬Ą─öĄō■Ż¼┤¾Ę∙Č╚£p╔┘▓ķįāĢrķgĪŻįōĘĮĘ©▒Š┘|╩Ūęį┐šķg┤·ārüĒōQ╚Ī▓ķįāą¦┬╩ĪŻCCIndex Ą─╦„ę²Ė³ą┬┤·ār▒╚▌^Ė▀Ż¼Ģ■ė░ĒæŽĄĮyĄ─═╠═┬┴┐ĪŻ╦„ę²äōĮ©ęį║¾Ż¼▓╗─▄ē“äėæBį÷╝ė╗“ą▐Ė─ĪŻAsynchronous views ęį«É▓ĮęĢłDĄ─ĘĮ╩ĮüĒīŹ¼FĘŪų„µIĄ─▓ķįāŻ¼╠ß│÷┴╦ā╔ĘNęĢłDĘĮ░ĖŻ║▀hČ╦ęĢłD▒Ē(Remote ViewTables: RVTs)║═Šų▓┐ęĢłD▒Ē(Local View Tables: LVTs)ĪŻ
RT-CAN▓╔ė├ČÓŠS╦„ę²╝ė╦┘ČÓųĄ▓ķįāĪŻŲõŠų▓┐╦„ę²▓╔ė├R-treeŻ¼╚½Šų╦„ę²ųą▓╔ė├┴╦─▄ē“ų¦│ųČÓŠS▓ķįāĄ─CANĖ▓╔wŠWĮjĪŻQT-Chord╩Ū┴Ēę╗ĘNļpīė╦„ę²ĮYśŗŻ¼╦³Ą─Šų▓┐╦„ę²▓╔ė├Ą─╩ŪĖ─▀MĄ─╦─▓µśõIMX-CIF quad-treeŻ¼╚½Šų╦„ę²▓╔ė├Ą─Chord Ė▓╔wŠWĮjĪŻEMINC[56]ßśī”├┐éĆŠų▓┐╣سcĮ©┴óę╗éĆKD-treeŻ¼╚╗║¾▀xō±KD-tree Ą─▓┐Ęų╣سcū„×ķ╚½Šų╦„ę²ĪŻ├┐ę╗éĆŠų▓┐╦„ę²╣سc▒╗┐┤│╔╩Ūę╗éĆČÓéĆŠSČ╚ĮM│╔Ą─┴óĘĮ¾wŻ¼╚╗║¾į┌╚½Šų╦„ę²ųąė├R-tree ī”▀@ą®┴óĘĮ¾w▀Mąą╦„ę²ĪŻA-Tree╠ß│÷┴╦┴Ē═Ōę╗ĘNĘĮ░ĖĪŻ╗∙▒Š╦╝┬Ę╩ŪŻ║ßśī”├┐ę╗éĆ┤µā”╣سcśŗĮ©R-treeŻ¼═¼ĢräōĮ©ę╗éĆBloom filter(▓╝┬Ī▀^×VŲ„)ĪŻ▀@śėį┌▀Mąą³c▓ķįāĄ─Ģr║“Ż¼╩ūŽ╚═©▀^Bloom filter▀Mąą“×ūCŻ¼╚ń╣¹▓ķįā³c▓╗į┌ŲõųąŻ¼ät▓╗į┘▀MąąR-tree ▓ķįāŻ¼Ę±ät└^└m▀MąąR-tree▓ķįāĪŻ
MD-HBase╠ß│÷ę╗ĘN╗∙ė┌┐šķg─┐ś╦┼┼ą“Ą─╦„ę²ĘĮ░ĖĪŻ╗∙ė┌┐šķg─┐ś╦┼┼ą“Ą─╦„ę²ĘĮĘ©Ą─╗∙▒Š╦╝Žļ╩ŪŻ║░┤ššę╗Č©ęÄätīóĖ▓╔wš¹éĆ蹊┐ģ^Ą─ĘČć·äØĘų×ķ┤¾ąĪŽÓĄ╚Ą─Ė±ūėŻ¼▓óĮo├┐ę╗Ė±ŠWĘų┼õę╗éĆŠÄ╠¢Ż¼ė├▀@ą®ŠÄ╠¢×ķ┐šķg─┐ś╦╔·│╔ę╗ĮMŠ▀ėą┤·▒ĒęŌ┴xĄ─öĄūųĪŻŲõīŹ┘|╩Ūīók ŠS┐šķgĄ─īŹ¾wė│╔õĄĮę╗ŠS┐šķgŻ¼ę“┤╦┐╔ęį└¹ė├¼FėąöĄō■Äņ╣▄└ĒŽĄĮyųą▒╚▌^│╔╩ņĄ─ę╗ŠS╦„ę²╝╝ągĪŻUQE-Indexų„ę¬ßśī”║Ż┴┐╬’┬ōŠWæ¬ė├ł÷Š░Ą─Ģr┐š╠žąįŻ¼į┌ĢrķgŠSČ╚╔Ž░čöĄō■Ęų│╔«öŪ░öĄō■║═Üv╩ĘöĄō■Ż¼ī”«öŪ░öĄō■║═Üv╩ĘöĄō■▀Mąą▓╗═¼┴ŻČ╚Ą─╦„ę²Ż¼ī”«öŪ░öĄō■Ż¼į┌ĢrķgČ╬║═ūė┐šķg╔Ž▀Mąą╦„ę²Ż¼Å─Č°£p╔┘╦„ę²Ė³ą┬Ą─┤╬öĄŻ¼ĮĄĄ═╦„ę²ŠSūoĄ─┤·ārŻ¼╠ßĖ▀ŽĄĮyĄ─═╠═┬┴┐Ż╗ī”Üv╩ĘöĄō■Ż¼┼·┴┐ĄžĮ©┴óėøõø╝ēäeĄ─╦„ę²Ż╗į┌Į©┴óūė┐šķg╦„ę²ĢrŻ¼×ķ┴╦┤_▒ŻöĄō■Ęų▓╝Š∙ä“Ż¼▓╔ė├KD Tree▀MąąäėæBäØĘųĪŻĄ½╩Ū╚ń╣¹╦∙ėąĄ─öĄō■Č╝ąĶę¬Įø▀^KD TreeüĒ╦„ę²Ą─įÆŻ¼ę▓Ģ■ĦüĒ▌^Ė▀Ą─┤·ārŻ¼Ģ■ė░ĒæöĄō■Ą─▓Õ╚ļ╦┘Č╚Ż¼ę“┤╦Ż¼┐╔ęįī”öĄō■▀Mąą▓╔śėŻ¼ī”▓╔śėĄ├ĄĮĄ─öĄō■└¹ė├KD Tree▀Mąą╦„ę²Ż¼Å─Č°Ą├ĄĮ┐šķg╔ŽĄ─äØĘųĘĮ░ĖĪŻ
Š═ęčėąĘĮ░ĖüĒ┐┤Ż¼ßśī”NoSQL öĄō■Äņ╔ŽĄ─▓ķįāā×╗»╝╝ągČ╝▓ó▓╗│╔╩ņŻ¼╚įėą║▄ČÓĻPµIąįå¢Ņ}žĮ┤²ĮŌøQĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║┤¾öĄō■╣▄└ĒŻ║Ė┼─ŅĪó╝╝ąg┼c╠¶æŻ©ųąŻ®