4.1.4 öĄō■Ęų╬÷╝╝ąg
öĄō■Ęų╬÷╩ŪGoogle ūŅ║╦ą─śI䚯¼├┐ę╗┤╬║åå╬Ą─ŠWĮj³cō¶▒│║¾Č╝ąĶę¬▀MąąÅ═ļsĄ─Ęų╬÷▀^│╠Ż¼ę“┤╦Googleī”ŲõĘų╬÷ŽĄĮy▀Mąą▓╗öÓĄ─╔²╝ēĖ─įņų«ųąĪŻMapReduce╩ŪGoogleūŅįń▓╔ė├Ą─ėŗ╦Ń─Żą═Ż¼▀mė├ė┌┼·╠Ä└ĒŻ¼ŲõŠ▀¾wā╚╚▌ęčį┌╔Žę╗╣ØĮķĮBĪŻłD╩ŪšµīŹ╔ńĢ■ųąÅVĘ║┤µį┌Ą─╩┬╬’ų«ķg┬ōŽĄĄ─ę╗ĘNėąą¦▒Ē╩Š╩ųČ╬Ż¼ę“┤╦ī”łDĄ─ėŗ╦Ń╩Ūę╗ĘN│ŻęŖĄ─ėŗ╦Ń─Ż╩ĮŻ¼Č°łDėŗ╦ŃĢ■╔µ╝░ĄĮį┌ŽÓ═¼öĄō■╔ŽĄ─▓╗öÓĖ³ą┬ęį╝░┤¾┴┐Ą─Ž¹Žóé„▀fŻ¼╚ń╣¹▓╔ė├MapReduce╚źīŹ¼FŻ¼Ģ■«a╔·┤¾┴┐▓╗▒žę¬Ą─ą“┴ą╗»║═Ę┤ą“┴ą╗»ķ_õNĪŻ¼FėąĄ─łDėŗ╦ŃŽĄĮy▓ó▓╗▀mė├ė┌GoogleĄ─æ¬ė├ł÷Š░Ż¼ę“┤╦Google įOėŗ▓óīŹ¼F┴╦Pregel łDėŗ╦Ń─Żą═ĪŻPregel╩ŪGoogle └^MapReduce ų«║¾╠ß│÷Ą─ėųę╗éĆėŗ╦Ń─Żą═Ż¼┼cMapReduce Ą─ļxŠĆ┼·╠Ä└Ē─Ż╩Į▓╗═¼Ż¼╦³ų„ę¬ė├ė┌łDĄ─ėŗ╦ŃĪŻįō─Żą═Ą─║╦ą─╦╝Žļį┤ė┌ų°├¹Ą─BSPėŗ╦Ń─Żą═ĪŻDremel╩ŪGoogle ╠ß│÷Ą─ę╗éĆ▀mė├ė┌Web öĄō■╝ēäeĄ─Į╗╗ź╩ĮöĄō■Ęų╬÷ŽĄĮyŻ¼═©▀^ĮY║Ž┴ą┤µā”║═ČÓīė┤╬Ą─▓ķįāśõŻ¼Dremel ─▄ē“īŹ¼FśOČ╠Ģrķgā╚Ą─║Ż┴┐öĄō■Ęų╬÷ĪŻDremel ų¦│ųų°Google ā╚▓┐Ą─ę╗ą®ųžę¬Ę■䚯¼▒╚╚ńGoogle Ą─įŲČ╦┤¾öĄō■Ęų╬÷ŲĮ┼_Big QueryĪŻGoogle į┌VLDB 2012 ░l▒ĒĄ─╬─š┬ųąĮķĮB┴╦ę╗éĆā╚▓┐├¹ĘQ×ķPowerDrillĄ─Ęų╬÷╣żŠ▀Ż¼PowerDrill ═¼śė▓╔ė├┴╦┴ą┤µā”Ż¼Ūę╩╣ė├┴╦ē║┐s╝╝ągīó▒M┐╔─▄ČÓĄ─öĄō■čb▌d▀Mā╚┤µĪŻPowerDrill ┼cDremel Š∙╩ŪGoogle Ą─┤¾öĄō■Ęų╬÷╣żŠ▀Ż¼Ą½╩ŪŲõĻPūóĄ─æ¬ė├ł÷Š░▓╗═¼Ż¼īŹ¼F╝╝ągę▓ėą║▄┤¾▓Ņ«ÉĪŻDremel ų„ę¬ė├ė┌ČÓöĄō■╝»Ą─Ęų╬÷Ż¼Č°PowerDrill ätų„ę¬æ¬ė├ė┌┤¾öĄō■┴┐Ą─║╦ą─öĄō■╝»Ęų╬÷Ż¼öĄō■╝»Ą─ĘNŅÉŽÓ▌^ė┌Dremel Ą─æ¬ė├ł÷Š░Ģ■╔┘║▄ČÓĪŻė╔ė┌PowerDrill ╩ŪįOėŗė├üĒ╠Ä└Ē╔┘┴┐Ą─║╦ą─öĄō■╝»Ż¼ę“┤╦ī”öĄō■╠Ä└Ē╦┘Č╚ę¬Ū¾śOĖ▀Ż¼╦∙ęįŲõöĄō■欫ö▒M┐╔─▄Ą─±v┴¶į┌ā╚┤µŻ¼Č°Dremel Ą─öĄō■ät┤µā”į┌┤┼▒PųąĪŻ│²┤╦ų«═ŌŻ¼PowerDrill ┼cDremel į┌öĄō■─Żą═ĪóöĄō■Ęųģ^Ą╚ĘĮ├µČ╝ėą├„’@Ą─▓ŅäeĪŻÅ─īŹļHĄ─ł╠ąąą¦┬╩üĒ┐┤Ż¼ Dremel┐╔ęįį┌Äū├ļā╚╠Ä└ĒPB ╝ēĄ─öĄō■▓ķįāŻ¼Č°PowerDrill ät┐╔ęįį┌30 ų┴40 ├ļ└’╠Ä└Ē7820 ā|éĆå╬į¬Ė±Ą─öĄō■Ż¼╠Ä└Ē╦┘Č╚┐ņė┌DremelĪŻČ■š▀Ą─æ¬ė├ł÷Š░▓╗═¼Ż¼┐╔ęįŽÓ╗źča│õĪŻ
╬ó▄ø╠ß│÷┴╦ę╗éĆŅÉ╦ŲMapReduce Ą─öĄō■╠Ä└Ē─Żą═Ż¼ĘQų«×ķDryadŻ¼Dryad ─Żą═ų„ę¬ė├üĒśŗĮ©ų¦│ųėąŽ“¤oŁhłD(Directed Acycline GraphŻ¼DAG)ŅÉą═öĄō■┴„Ą─▓óąą│╠ą“ĪŻCascading═©▀^ī”Hadoop MapReduce API Ą─ĘŌčbŻ¼ų¦│ųėąŽ“¤oŁhłDŅÉą═Ą─æ¬ė├ĪŻSector/sphere┐╔ęįęĢ×ķę╗ĘN┴„╩ĮĄ─MapReduceŻ¼╦³ė╔Ęų▓╝╩Į╬─╝■ŽĄĮySector ║═▓óąąėŗ╦Ń┐“╝▄sphere ĮM│╔ĪŻNephele/PACTs [68]ät░³└©PACTs(Parallelization Contracts)ŠÄ│╠─Żą═║═▓óąąėŗ╦Ńę²ŪµNepheleĪŻMapReduce ─Żą═╗∙▒Š│╔×ķ┴╦┼·╠Ä└ĒŅÉæ¬ė├Ą─ś╦£╩╠Ä└Ē─Żą═Ż¼║▄ČÓæ¬ė├ķ_╩╝ćLįć└¹ė├MapReduce ╝ė╦┘ŲõöĄō■╠Ä└ĒĪŻ
īŹĢröĄō■╠Ä└Ē╩Ū┤¾öĄō■Ęų╬÷Ą─ę╗éĆ║╦ą─ąĶŪ¾ĪŻ║▄ČÓ蹊┐╣żū„š²╩Ūć·└@▀@ę╗ąĶŪ¾š╣ķ_Ą─ĪŻŪ░├µĮķĮB┴╦┤¾öĄō■╠Ä└ĒĄ─ā╔ĘN╗∙▒Š─Ż╩ĮŻ¼Č°į┌īŹĢr╠Ä└ĒĄ──Ż╩Į▀xō±ųąŻ¼ų„ę¬ėą╚²ĘN╦╝┬ĘŻ║
1) ▓╔ė├┴„╠Ä└Ē─Ż╩ĮĪŻļm╚╗┴„╠Ä└Ē─Ż╩Į╠ņ╚╗▀m║ŽīŹĢr╠Ä└ĒŽĄĮyŻ¼Ą½Ųõ▀mė├ŅIė“ŽÓī”ėąŽ▐ĪŻ┴„╠Ä└Ē─Żą═Ą─æ¬ė├ų„ę¬╝»ųąį┌īŹĢrĮyėŗŽĄĮyĪóį┌ŠĆĀŅæB▒O┐žĄ╚ĪŻ
2) ▓╔ė├┼·╠Ä└Ē─Ż╩ĮĪŻĮ³Äū─ĻüĒŻ¼└¹ė├┼·╠Ä└Ē─Żą═ķ_░līŹĢrŽĄĮyęčĮø│╔×ķ蹊┐¤ß³c▓ó╚ĪĄ├┴╦║▄ČÓ│╔╣¹ĪŻÅ─į÷┴┐ėŗ╦ŃĄ─ĮŪČ╚│÷░lŻ¼Google ╠ß│÷┴╦į÷┴┐╠Ä└ĒŽĄĮyPercolatorŻ¼╬ó▄øät╠ß│÷┴╦Nectar║═DryadIncĪŻ╚²š▀Š∙īŹ¼F┴╦┤¾ęÄ─ŻöĄō■Ą─į÷┴┐ėŗ╦ŃŻ¼Ą½╩Ū▀@ą®ŽĄĮy║═MapReduce ▓ó▓╗╝µ╚▌Ż¼ę“┤╦Incoop║═IncMRīŹ¼F┴╦MapReduce ┐“╝▄Ž┬Ą─į÷┴┐ėŗ╦ŃĪŻYahoo Ą─Novaätų¦│ųėąĀŅæBĄ─į÷┴┐öĄō■ėŗ╦Ń─Ż╩ĮĪŻHOPį┌MapReduce ╠Ä└ĒĄ─▀^│╠ųąę²╚ļ╣▄Ą└(pipeline)Ą─Ė┼─ŅĪŻį┌▒ŻūCHadoop ╚▌ÕeąįĄ─Ū░╠ߎ┬Ż¼╩╣öĄō■į┌Ė„éĆ╚╬äšķgęį╣▄Ą└Ą─ĘĮ╩ĮĮ╗╗źŻ¼į÷╝ė┴╦╚╬䚥─▓ó░ląįŻ¼╠ßĖ▀┴╦öĄō■╠Ä└ĒĄ─īŹĢrąįĪŻųąć°╚╦├±┤¾īWWAMDM īŹ“×╩ęį┌HOP ╗∙ĄA╔Žķ_░lĄ─COLA ŽĄĮyį┌HOP ŽĄĮyĄ─╗∙ĄA╔Žį÷╝ė┴╦öĄō■▓╔śėĪóĮY╣¹╣└ėŗĪóų├ą┼ģ^ķgėŗ╦ŃĄ╚╣”─▄─ŻēKŻ¼ę╗Č©│╠Č╚╔Ž╠ßĖ▀┴╦HOP Ą─īŹĢrąįĪŻįŁ╬╗Ęų╬÷┐╔ęį▒▄├Ōīó╬─╝■╝»ųąé„▌öĄĮĘų╬÷Ę■äšŲ„╔ŽĄ─═©ėŹķ_õNŻ¼┤¾┤¾╠ßĖ▀┴╦īŹĢrąįĪŻ║═Å─įŁ╬╗Ęų╬÷Ą─ĮŪČ╚│÷░lŻ¼ĘųäeīŹ¼F┴╦ßśī”┤¾ęÄ─Ż╚šųŠĘų╬÷Ą─įŁ╬╗MapReduce(In-situ MapReduce)║═ContinuousMapReduceĪŻįŁ╩╝Ą─MapReduce ─Żą═▓ó▓╗─▄║▄║├Ą─ų¦│ųĄ³┤·ėŗ╦ŃŻ¼ėŗ╦Ń┤·ār║▄┤¾ĪŻČ°Ą³┤·ėŗ╦Ń╩ŪłDėŗ╦ŃĪóöĄō■═┌Š“ĪóÖCŲ„īW┴ĢĄ╚ŅIė“│ŻęŖĄ─▀\╦Ń─Ż╩ĮŻ¼▓╗╔┘蹊┐╣żū„═©▀^Ė─▀MMapReduce ─Żą═Ą³┤·ėŗ╦ŃĄ─ą¦┬╩üĒ╠ßĖ▀ŲõīŹĢrąįĪŻHaLoop═©▀^į┌Ė„éĆtask tracker ī”öĄō■▀MąąŠÅ┤µ(cache)║═äōĮ©╦„ę²(index)Ą─ĘĮ╩ĮüĒ£p╔┘┤┼▒PIOŻ¼▓ó╠ß╣®┴╦ę╗╠ūą┬Ą─ŠÄ│╠Įė┐┌ĪŻĄ½╩ŪHaLoopĄ─äėņoæBöĄō■¤oĘ©ĘųļxŻ¼Ūęø]ėąę╗éĆ┐═ė^Ą─═Żų╣Ą³┤·Ą─ś╦£╩ĪŻTwisterŽĄĮyīóHadoop Ą─╚½▓┐öĄō■┤µĘ┼į┌ā╚┤µųąŻ¼▓╔ė├¬Ü┴ó─ŻēKé„▀f╦∙ėąĄ─Ž¹Žó║═öĄō■ĪŻĄ½╩ŪöĄō■±v┴¶ā╚┤µĄ─Ž▐ųŲ╩╣ŲõļyęįīŹė├Ż¼ŪęŲõėŗ╦Ń─Żą═Ą─│ķŽ¾Č╚▓╗Ė▀Ż¼ų¦│ųĄ─æ¬ė├ę▓║▄ėąŽ▐ĪŻTwister ╚į╠Äė┌│§▓ĮĄ─蹊┐ļAČ╬ĪŻ
iMapReduceĮķĮB┴╦ę╗ĘN╗∙ė┌MapReduce Ą─Ą³┤·─Żą═Ż¼Ą½╩Ū╦³Ą─ņoæBš{Č╚▓▀┬į║═┤ų┴ŻČ╚Ą─task ┐╔─▄Ģ■ī¦ų┬┘Yį┤└¹ė├▓╗╝č║═žō▌d▓╗Š∙ĪŻiHadoopīŹ¼F┴╦MapReduce Ą─«É▓ĮĄ³┤·Ż¼Ą½╩Ūį┌task ų«ķgĄ─Å═ė├╔Ž▓ó¤o╠½┤¾Ė─▀MĪŻPrIter╩Ūį┌Hadoop Ą─╗∙ĄA╔Žķ_░lĄ─Ż¼ų¦│ųĦā׎╚╝ēĄ─Ą³┤·ėŗ╦ŃŻ¼─▄ē“▒ŻūCĄ³┤·▀^│╠Ą─┐ņ╦┘╩šö┐Ż¼▀m║Žtop-k ų«ŅÉĄ─į┌ŠĆ▓ķįāĪŻūŅą┬░µ▒ŠĄ─PrIter ęčĮøų¦│ų╗∙ė┌ā╚┤µ║═╗∙ė┌╬─╝■Ą─öĄō■┤µā”ĘĮ╩ĮĪŻSparkīóųąķgĮY╣¹┤µĘ┼į┌ā╚┤µųąŻ¼ų¦│ų│²Map ║═Reduce ų«═ŌĄ─ČÓĘN▓┘ū„ŅÉą═ĪŻĄ½╩ŪSpark ▓╗▀mė├«É▓Į╝Ü┴ŻČ╚Ė³ą┬ĀŅæBĄ─æ¬ė├Ż¼═¼Ģrį┌╚▌ÕeąįĘĮ├µėą┤²╠ß╔²ĪŻFacebook ĮY║Žūį╝║Ą─æ¬ė├ł÷Š░śŗĮ©┴╦īŹĢrĄ─Hadoop ŽĄĮy,ų„ę¬╩ŪīŹ¼F┴╦Ė▀┐╔ė├Ą─NameNodeŻ¼ī”▓ó░lūx║═īŹĢržō▌dąį─▄▀Mąą┴╦ā×╗»Ż¼Ė─įņHBase ╩╣Ųõ▀m║ŽšµīŹĄ─īŹĢr╔·«aŁhŠ│ĪŻ
3) Č■š▀Ą─╚┌║ŽĪŻėą▓╗╔┘蹊┐╚╦åTćLįćīó┴„╠Ä└Ē║═┼·╠Ä└Ē─Ż╩Į▀Mąą╚┌║ŽŻ¼ų„ę¬╦╝┬Ę╩Ū└¹ė├MapReduce ─Żą═īŹ¼F┴„╠Ä└ĒĪŻDEDUCE ŽĄĮyöUš╣┴╦IBM Ą─┴„╠Ä└Ē▄ø╝■System SŻ¼╩╣Ųõų¦│ųMapReduceĪŻC-MR ŽĄĮy ═©▀^3 éĆĘĮ├µĄ─╣żū„īŹ¼F┴╦ų¦│ų┴„╠Ä└ĒĄ─│ų└mą═MapReduce( Continuous-MapReduce)Ż║
a)īó▓óąą┴„╠Ä└ĒųąĄ─┤░┐┌Ė┼─Ņ═Ė├„Ą─öUš╣ĄĮMapReduce ─Żą═ųąŻ╗
b) ėąą¦ĮY║Ž┴╦░³└©CPUĪóGPU į┌ā╚Ą─ČÓĘN«Éśŗėŗ╦Ń─▄┴”Ż╗
į┌Hadoop ŽĄĮy╗∙ĄA╔Ž▀MąąöUš╣Ż¼└@ķ_HDFS Ą─Ž▐ųŲŻ¼īŹ¼F┴╦ę╗éĆ╚½ā╚┤µ╠Ä└ĒĄ─Ė▀ą¦┴„╠Ä└ĒŽĄĮyĪŻStreamMapReduceĮY║Ž╩┬╝■┴„╠Ä└Ē(Event Stream Processing)Ą─╠ž³cŻ¼ī”MapReduce ųąĄ─Mapper ║═Reducer ▀Mąąųžą┬Č©┴xŻ¼į÷╝ė┴╦│ų└mĄ─ĪóĄ═čė▀tĄ─öĄō■╠Ä└Ē─▄┴”ĪŻ
į┌│õĘųš{čą╗∙ĄA╔ŽŻ¼ū„š▀šJ×ķįŁ╩╝Ą─MapReduce ┐“╝▄▓╗▀m║Ž╠Ä└Ē┐ņ╦┘öĄō■ĪŻĮY║Ž┐ņ╦┘öĄō■Ą─╠ž³cŻ¼╬─ųąįOėŗ┴╦ę╗éĆŅÉ╦ŲMapReduce Ą─┐“╝▄——MapUpdateŻ¼▓óį┌įō┐“╝▄╗∙ĄA╔ŽīŹ¼F┴╦ę╗éĆįŁą═ŽĄĮyMuppetĪŻ║═╔Ž╩÷▀@ą®ŽĄĮyŽÓ▒╚Ż¼SSSūŅ┤¾Ą─╠ž³cŠ═╩Ūį┌ų¦│ų┐ņ╦┘┴„╠Ä└ĒĄ─═¼Ģrę▓─▄ē“ų¦│ų┤¾ęÄ─ŻņoæBöĄō■Ą─╠Ä└ĒŻ¼ę▓Š═╩Ūšf╝µŠ▀┴„╠Ä└Ē║═┼·╠Ä└ĒĪŻųą╠ß│÷├¹×ķļx╔ó┴„(Discretized Streams)Ą─ŠÄ│╠─Żą═Ż¼▓óį┌Spark╗∙ĄA╔ŽīŹ¼F┴╦ę╗éĆįŁą═ŽĄĮySpark StreamingĪŻ
4.2 ┤¾öĄō■╠Ä└Ē╣żŠ▀
ĻPŽĄöĄō■Äņį┌║▄ķLĄ─Ģrķg└’│╔×ķöĄō■╣▄└ĒĄ─ūŅ╝č▀xō±Ż¼Ą½╩Ūį┌┤¾öĄō■Ģr┤·Ż¼öĄō■╣▄└ĒĪóĘų╬÷Ą╚Ą─ąĶŪ¾ČÓśė╗»╩╣Ą├ĻPŽĄöĄō■Äņį┌║▄ČÓł÷Š░▓╗į┘▀mė├ĪŻ▒Š╣Øīóī”¼FĮ±ų„┴„Ą─┤¾öĄō■╠Ä└Ē╣żŠ▀▀Mąąę╗éĆ║åå╬Ą─Üw╝{║═┐éĮYĪŻ
Hadoop ╩Ū─┐Ū░ūŅ×ķ┴„ąąĄ─┤¾öĄō■╠Ä└ĒŲĮ┼_ĪŻHadoop ūŅŽ╚╩ŪDoug Cutting ─ŻĘ┬GFSĪóMapReduce īŹ¼FĄ─ę╗éĆįŲėŗ╦Ńķ_į┤ŲĮ┼_Ż¼║¾žĢ½IĮoApacheĪŻHadoop ęčĮø░lš╣│╔×ķ░³└©╬─╝■ŽĄĮy(HDFS)ĪóöĄō■Äņ(HBaseĪóCassandra)ĪóöĄō■╠Ä└Ē(MapReduce)Ą╚╣”─▄─ŻēKį┌ā╚Ą─═Ļš¹╔·æBŽĄĮy(Ecosystem)ĪŻ─│ĘN│╠Č╚╔Ž┐╔ęįšfHadoop ęčĮø│╔×ķ┴╦┤¾öĄō■╠Ä└Ē╣żŠ▀╩┬īŹ╔ŽĄ─ś╦£╩ĪŻī”Hadoop Ė─▀M▓óīóŲõæ¬ė├ė┌Ė„ĘNł÷Š░Ą─┤¾öĄō■╠Ä└ĒęčĮø│╔×ķą┬Ą─蹊┐¤ß³cĪŻų„ꬥ─蹊┐│╔╣¹╝»ųąį┌ī”Hadoop ŲĮ┼_ąį─▄Ą─Ė─▀MĪóĖ▀ą¦Ą─▓ķįā╠Ä└ĒĪó╦„ę²śŗĮ©║═╩╣ė├Īóį┌Hadoop ų«╔ŽśŗĮ©öĄō■é}ÄņĪóHadoop ║═öĄō■ÄņŽĄĮyĄ─▀BĮėĪóöĄō■═┌Š“Īó═Ų╦]ŽĄĮyĄ╚ĪŻ
│²┴╦HadoopŻ¼▀Ćėą║▄ČÓßśī”┤¾öĄō■Ą─╠Ä└Ē╣żŠ▀ĪŻ▀@ą®╣żŠ▀ėąą®╩Ū═Ļš¹Ą─╠Ä└ĒŲĮ┼_Ż¼ėąą®ät╩ŪīŻķTßśī”╠žČ©Ą─┤¾öĄō■╠Ä└Ēæ¬ė├ĪŻ▒Ē7 Üw╝{┐éĮY┴╦¼FĮ±ę╗ą®ų„┴„Ą─╠Ä└ĒŲĮ┼_║═╣żŠ▀Ż¼▀@ą®ŲĮ┼_║═╣żŠ▀╗“╩ŪęčĮø═Č╚ļ╔╠śI╩╣ė├Ż¼╗“╩Ūķ_į┤▄ø╝■ĪŻį┌ęčĮø═Č╚ļ╔╠śI╩╣ė├Ą─«aŲĘųąŻ¼Į^┤¾▓┐Ęųę▓╩Ūį┌Hadoop ╗∙ĄA╔Ž▀Mąą╣”─▄öUš╣Ż¼╗“š▀╠ß╣®┼cHadoop Ą─öĄō■Įė┐┌ĪŻ
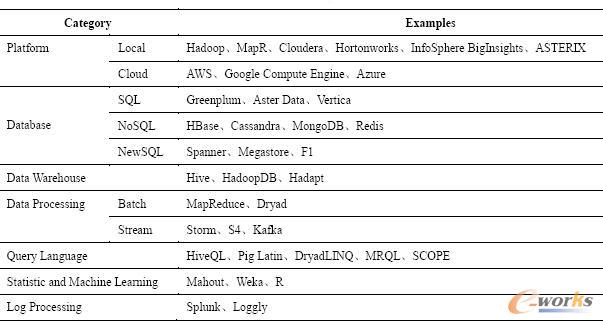
▒Ē7 ┤¾öĄō■╣żŠ▀┴ą▒Ē
5Īó┤¾öĄō■Ģr┤·├µ┼RĄ─ą┬╠¶æ
ŠC╔Ž╦∙╩÷Ż¼┤¾öĄō■Ģr┤·Ą─öĄō■┤µį┌ų°╚ńŽ┬ÄūéĆ╠ž³cŻ║ČÓį┤«ÉśŗŻ╗Ęų▓╝ÅVĘ║Ż╗äėæBį÷ķLŻ╗Ž╚ėąöĄō■║¾ėą─Ż╩ĮĪŻ
š²╩Ū▀@ą®┼cé„ĮyöĄō■╣▄└ĒÕ─╚╗▓╗═¼Ą─╠ž³cŻ¼╩╣Ą├┤¾öĄō■Ģr┤·Ą─öĄō■╣▄└Ē├µ┼Rų°ą┬Ą─╠¶æŻ¼Ž┬├µĢ■ī”ŲõųąĄ─ų„ę¬╠¶æ▀Mąąįö╝ÜĘų╬÷ĪŻ
5.1 ┤¾öĄō■╝»│╔
öĄō■Ą─ÅVĘ║┤µį┌ąį╩╣Ą├öĄō■įĮüĒįĮČÓĄ─╔ó▓╝ė┌▓╗═¼Ą─öĄō■╣▄└ĒŽĄĮyųąŻ¼×ķ┴╦▒Ńė┌▀MąąöĄō■Ęų╬÷ąĶę¬▀MąąöĄō■Ą─╝»│╔ĪŻöĄō■╝»│╔┐┤ŲüĒ▓ó▓╗╩Ūę╗éĆą┬Ą─å¢Ņ}Ż¼Ą½╩Ū┤¾öĄō■Ģr┤·Ą─öĄō■╝»│╔ģsėą┴╦ą┬Ą─ąĶŪ¾Ż¼ę“┤╦ę▓├µ┼Rų°ą┬Ą─╠¶æĪŻ
1ĪóÅVĘ║Ą─«ÉśŗąįĪŻé„ĮyĄ─öĄō■╝»│╔ųąę▓Ģ■├µī”öĄō■«ÉśŗĄ─å¢Ņ}Ż¼Ą½╩Ūį┌┤¾öĄō■Ģr┤·▀@ĘN«Éśŗąį│÷¼F┴╦ą┬Ą─ūā╗»ĪŻų„ę¬¾w¼Fį┌Ż║
1Ż®öĄō■ŅÉą═Å─ęįĮYśŗ╗»öĄō■×ķų„▐DŽ“ĮYśŗ╗»Īó░ļĮYśŗ╗»ĪóĘŪĮYśŗ╗»╚²š▀Ą─╚┌║ŽĪŻ
2Ż®öĄō■«a╔·ĘĮ╩ĮĄ─ČÓśėąįĦüĒĄ─öĄō■į┤ūā╗»ĪŻé„ĮyĄ─ļŖūėöĄō■ų„ꬫa╔·ė┌Ę■äšŲ„╗“š▀╩ŪéĆ╚╦ļŖ─XŻ¼▀@ą®įOéõ╬╗ų├ŽÓī”╣╠Č©ĪŻļSų°ęŲäėĮKČ╦Ą─┐ņ╦┘░lš╣Ż¼╩ųÖCĪóŲĮ░ÕļŖ─XĪóGPS Ą╚«a╔·Ą─öĄō■┴┐│╩¼F▒¼š©╩Įį÷ķLŻ¼Ūę«a╔·Ą─öĄō■Ħėą║▄├„’@Ą─Ģr┐š╠žąįĪŻ
3Ż®öĄō■┤µā”ĘĮ╩ĮĄ─ūā╗»ĪŻé„ĮyöĄō■ų„ę¬┤µā”į┌ĻPŽĄöĄō■ÄņųąŻ¼Ą½įĮüĒįĮČÓĄ─öĄō■ķ_╩╝▓╔ė├ą┬Ą─öĄō■┤µā”ĘĮ╩ĮüĒæ¬ī”öĄō■▒¼š©Ż¼▒╚╚ń┤µā”į┌Hadoop Ą─HDFS ųąĪŻ▀@Š═▒ž╚╗ę¬Ū¾į┌╝»│╔Ą─▀^│╠ųą▀MąąöĄō■▐DōQŻ¼Č°▀@ĘN▐DōQĄ─▀^│╠╩ŪĘŪ│ŻÅ═ļs║═ļyęį╣▄└ĒĄ─ĪŻ
2ĪóöĄō■┘|┴┐ĪŻöĄō■┴┐┤¾▓╗ę╗Č©Š═┤·▒Ēą┼Žó┴┐╗“š▀öĄō■ārųĄĄ─į÷┤¾Ż¼ŽÓĘ┤║▄ČÓĢr║“ęŌ╬Čų°ą┼Žó└¼╗°Ą─Ę║×EĪŻę╗ĘĮ├µ║▄ļyėąå╬éĆŽĄĮy─▄ē“╚▌╝{Ž┬Å─▓╗═¼öĄō■į┤╝»│╔Ą─║Ż┴┐öĄō■Ż╗┴Ēę╗ĘĮ├µ╚ń╣¹į┌╝»│╔Ą─▀^│╠ųąāHāH║åå╬Ą─īó╦∙ėąöĄō■Š█╝»į┌ę╗ŲČ°▓╗ū÷╚╬║╬öĄō■ŪÕŽ┤Ż¼Ģ■╩╣Ą├▀^ČÓĄ─¤oė├öĄō■Ė╔ö_║¾└mĄ─öĄō■Ęų╬÷▀^│╠ĪŻ┤¾öĄō■Ģr┤·Ą─öĄō■ŪÕŽ┤▀^│╠▒žĒÜĖ³╝ėųö╔„Ż¼ę“×ķŽÓī”╝Ü╬óĄ─ėąė├ą┼Žó╗ņļsį┌²ŗ┤¾Ą─öĄō■┴┐ųąĪŻ╚ń╣¹ą┼ŽóŪÕŽ┤Ą─┴ŻČ╚▀^╝ÜŻ¼║▄╚▌ęūīóėąė├Ą─ą┼Žó▀^×VĄ¶ĪŻŪÕŽ┤┴ŻČ╚▀^┤ųŻ¼ėų¤oĘ©▀_ĄĮšµš²Ą─ŪÕŽ┤ą¦╣¹Ż¼ę“┤╦į┌┘|┼c┴┐ų«ķgąĶę¬▀Mąąūą╝ÜĄ─┐╝┴┐║═ÖÓ║ŌĪŻ
5.2 ┤¾öĄō■Ęų╬÷Ż©AnalyticsŻ®
é„ĮyęŌ┴x╔ŽĄ─öĄō■Ęų╬÷(analysis)ų„ę¬ßśī”ĮYśŗ╗»öĄō■š╣ķ_Ż¼ŪęęčĮøą╬│╔┴╦ę╗š¹╠ūąąų«ėąą¦Ą─Ęų╬÷¾wŽĄĪŻ╩ūŽ╚└¹ė├öĄō■ÄņüĒ┤µā”ĮYśŗ╗»öĄō■Ż¼į┌┤╦╗∙ĄA╔ŽśŗĮ©öĄō■é}ÄņŻ¼Ė∙ō■ąĶ꬜ŗĮ©öĄō■┴óĘĮ¾w▀Mąą┬ōÖCĘų╬÷╠Ä└Ē (OLAP, Online Analytical Processing)Ż¼┐╔ęį▀MąąČÓéĆŠSČ╚Ą─Ž┬Ń@(Drill-down)╗“╔ŽŠĒ(Roll-up)▓┘ū„ĪŻī”ė┌Å─öĄō■ųą╠ߤÆĖ³╔Ņīė┤╬Ą─ų¬ūRĄ─ąĶŪ¾┤┘╩╣öĄō■═┌Š“╝╝ągĄ─«a╔·Ż¼▓ó░l├„┴╦Š█ŅÉĪóĻP┬ōĘų╬÷Ą╚ę╗ŽĄ┴ąį┌īŹ█`ųąąąų«ėąą¦Ą─ĘĮĘ©ĪŻ▀@ę╗š¹╠ū╠Ä└Ē┴„│╠į┌╠Ä└ĒŽÓī”▌^╔┘Ą─ĮYśŗ╗»öĄō■ĢrśO×ķĖ▀ą¦ĪŻĄ½╩ŪļSų°┤¾öĄō■Ģr┤·Ą─ĄĮüĒŻ¼░ļĮYśŗ╗»║═ĘŪĮYśŗ╗»öĄō■┴┐Ą─čĖ├═į÷ķLŻ¼Įoé„ĮyĄ─Ęų╬÷╝╝ągĦüĒ┴╦Š▐┤¾Ą─ø_ō¶║═╠¶æŻ¼ų„ę¬¾w¼Fį┌Ż║
1ĪóöĄō■╠Ä└ĒĄ─īŹĢrąį(Timeliness)ĪŻļSų°ĢrķgĄ─┴„╩┼öĄō■ųą╦∙╠N║¼Ą─ų¬ūRārųĄ═∙═∙ę▓į┌╦ź£pŻ¼ę“┤╦║▄ČÓŅIė“ī”ė┌öĄō■Ą─īŹĢr╠Ä└ĒėąąĶŪ¾ĪŻļSų°┤¾öĄō■Ģr┤·Ą─ĄĮüĒŻ¼Ė³ČÓæ¬ė├ł÷Š░Ą─öĄō■Ęų╬÷Å─ļxŠĆ(offline)▐DŽ“┴╦į┌ŠĆ(online)Ż¼ķ_╩╝│÷¼FīŹĢr╠Ä└ĒĄ─ąĶŪ¾Ż¼▒╚╚ńKDD 2012ūŅ╝čšō╬─╦∙╠ĮėæĄ─īŹĢrÅVĖµĖéārå¢Ņ}ĪŻ┤¾öĄō■Ģr┤·Ą─öĄō■īŹĢr╠Ä└Ē├µ┼Rų°ę╗ą®ą┬Ą─╠¶æŻ¼ų„ę¬¾w¼Fį┌öĄō■╠Ä└Ē─Ż╩ĮĄ─▀xō±╝░Ė─▀MĪŻį┌īŹĢr╠Ä└ĒĄ──Ż╩Į▀xō±ųąŻ¼ų„ę¬ėą╚²ĘN╦╝┬ĘŻ║╝┤┴„╠Ä└Ē─Ż╩ĮĪó┼·╠Ä└Ē─Ż╩Įęį╝░Č■š▀Ą─╚┌║ŽĪŻŽÓĻP蹊┐│╔╣¹į┌╔Žę╗╣ØęčĮøėąįö╝ÜĮķĮBĪŻļm╚╗ęčėąĄ─蹊┐│╔╣¹║▄ČÓŻ¼Ą½╩Ū╚į╬┤ėąę╗éĆ═©ė├Ą─┤¾öĄō■īŹĢr╠Ä└Ē┐“╝▄ĪŻĖ„ĘN╣żŠ▀īŹ¼FīŹĢr╠Ä└ĒĄ─ĘĮĘ©▓╗ę╗Ż¼ų¦│ųĄ─æ¬ė├ŅÉą═Č╝ŽÓī”ėąŽ▐Ż¼▀@ī¦ų┬īŹļHæ¬ė├ųą═∙═∙ąĶę¬Ė∙ō■ūį╝║Ą─śIäšąĶŪ¾║═æ¬ė├ł÷Š░ī”¼FėąĄ─▀@ą®╝╝ąg║═╣żŠ▀▀MąąĖ─įņ▓┼─▄ØMūŃę¬Ū¾ĪŻ
2ĪóäėæBūā╗»ŁhŠ│ųą╦„ę²Ą─įOėŗĪŻĻPŽĄöĄō■ÄņųąĄ─╦„ę²─▄ē“╝ė╦┘▓ķįā╦┘┬╩Ż¼Ą½╩Ūé„ĮyĄ─öĄō■╣▄└Ēųą─Ż╩Į╗∙▒Š▓╗Ģ■░l╔·ūā╗»Ż¼ę“┤╦į┌Ųõ╔ŽśŗĮ©╦„ę²ų„ę¬┐╝æ]Ą─╩Ū╦„ę²äōĮ©ĪóĖ³ą┬Ą╚Ą─ą¦┬╩ĪŻ┤¾öĄō■Ģr┤·Ą─öĄō■─Ż╩ĮļSų°öĄō■┴┐Ą─▓╗öÓūā╗»┐╔─▄Ģ■╠Äė┌▓╗öÓĄ─ūā╗»ų«ųąŻ¼▀@Š═ę¬Ū¾╦„ę²ĮYśŗĄ─įOėŗ║åå╬ĪóĖ▀ą¦Ż¼─▄ē“į┌öĄō■─Ż╩Į░l╔·ūā╗»Ģr║▄┐ņĄ─▀Mąąš{š¹üĒ▀mæ¬ĪŻŪ░├µę▓ĮķĮB┴╦═©▀^į┌NoSQL öĄō■Äņ╔ŽśŗĮ©╦„ę²üĒæ¬ī”┤¾öĄō■╠¶æĄ─ę╗ą®ĘĮ░ĖŻ¼Ą½┐éĄ─üĒšfŻ¼▀@ą®ĘĮ░Ė╗∙▒ŠČ╝ėą╠žČ©Ą─æ¬ė├ł÷Š░Ż¼Ūę▀@ą®ł÷Š░Ą─öĄō■─Ż╩Į▓╗╠½Ģ■░l╔·ūā╗»ĪŻį┌öĄō■─Ż╩ĮūāĖ³Ą─╝┘įOŪ░╠ߎ┬įOėŗą┬Ą─╦„ę²ĘĮ░Ėīó╩Ū┤¾öĄō■Ģr┤·Ą─ų„ę¬╠¶æų«ę╗ĪŻ
3ĪóŽ╚“×ų¬ūRĄ─╚▒Ę”ĪŻé„ĮyĘų╬÷ų„ę¬ßśī”ĮYśŗ╗»öĄō■š╣ķ_Ż¼▀@ą®öĄō■į┌ęįĻPŽĄ─Żą═▀Mąą┤µā”Ą─═¼ĢrŠ═ļ[║¼┴╦▀@ą®öĄō■ā╚▓┐ĻPŽĄĄ╚Ž╚“×ų¬ūRĪŻ▒╚╚ń╬ęéāų¬Ą└╦∙ę¬Ęų╬÷Ą─ī”Ž¾Ģ■ėą──ą®ī┘ąįŻ¼═©▀^ī┘ąį╬ęéāėų─▄┤¾ų┬┴╦ĮŌŲõ┐╔─▄Ą─╚ĪųĄĘČć·Ą╚ĪŻ▀@ą®ų¬ūR╩╣Ą├╬ęéāį┌öĄō■Ęų╬÷ų«Ū░Š═ęčĮøī”öĄō■ėą┴╦ę╗Č©Ą─└ĒĮŌĪŻČ°į┌├µī”┤¾öĄō■Ęų╬÷ĢrŻ¼ę╗ĘĮ├µ╩Ū░ļĮYśŗ╗»║═ĘŪĮYśŗ╗»öĄō■Ą─┤µį┌Ż¼▀@ą®öĄō■║▄ļyęįŅÉ╦ŲĮYśŗ╗»öĄō■Ą─ĘĮ╩ĮśŗĮ©│÷Ųõā╚▓┐Ą─š²╩ĮĻPŽĄŻ╗┴Ēę╗ĘĮ├µ║▄ČÓöĄō■ęį┴„Ą─ą╬╩Įį┤į┤▓╗öÓĄ─ĄĮüĒŻ¼▀@ą®ąĶę¬īŹĢr╠Ä└ĒĄ─öĄō■║▄ļyėąūŃē“Ą─Ģrķg╚źĮ©┴óŽ╚“×ų¬ūRĪŻ
5.3 ┤¾öĄō■ļ[╦Įå¢Ņ}
ļ[╦Įå¢Ņ}ė╔üĒęčŠ├Ż¼ėŗ╦ŃÖCĄ─│÷¼F╩╣Ą├įĮüĒįĮČÓĄ─öĄō■ęįöĄūų╗»Ą─ą╬╩Į┤µā”į┌ļŖ─XųąŻ¼╗ź┬ōŠWĄ─░lš╣ät╩╣öĄō■Ė³╝ė╚▌ęū«a╔·║═é„▓źŻ¼öĄō■ļ[╦Įå¢Ņ}įĮüĒįĮć└ųžĪŻ
1Īóļ[ąįĄ─öĄō■▒®┬ČĪŻ║▄ČÓĢr║“╚╦éāėąęŌūRĄ─īóūį╝║Ą─ąą×ķļ[▓žŲüĒŻ¼įćłD▀_ĄĮļ[╦Į▒ŻūoĄ──┐Ą─ĪŻĄ½╩Ū╗ź┬ōŠWŻ¼ė╚Ųõ╩Ū╔ńĮ╗ŠWĮjĄ─│÷¼FŻ¼╩╣Ą├╚╦éāį┌▓╗═¼Ą─Ąž³c«a╔·įĮüĒįĮČÓĄ─öĄō■ūŃ█EĪŻ▀@ĘNöĄō■Š▀ėą└█Ęeąį║═ĻP┬ōąįŻ¼å╬éĆĄž³cĄ─ą┼Žó┐╔─▄▓╗Ģ■▒®┬Čė├æ¶Ą─ļ[╦ĮŻ¼Ą½╩Ū╚ń╣¹ėą▐kĘ©īó─│éĆ╚╦Ą─║▄ČÓąą×ķÅ─▓╗═¼Ą─¬Ü┴óĄž³cŠ█╝»į┌ę╗ŲĢrŻ¼╦¹Ą─ļ[╦ĮŠ═║▄┐╔─▄Ģ■▒®┬ČŻ¼ę“×ķėąĻP╦¹Ą─ą┼ŽóęčĮøūŃē“ČÓ┴╦Ż¼▀@ĘNļ[ąįĄ─öĄō■▒®┬Č═∙═∙╩ŪéĆ╚╦¤oĘ©ŅAų¬║═┐žųŲĄ─ĪŻÅ─╝╝ągīė├µüĒšfŻ¼┐╔ęį═©▀^öĄō■│ķ╚Ī║═╝»│╔üĒīŹ¼Fė├æ¶ļ[╦ĮĄ─½@╚ĪĪŻČ°į┌¼FīŹųą═©▀^╦∙ų^Ą─“╚╦╚Ō╦č╦„”Ą─ĘĮ╩Į═∙═∙─▄Ė³┐ņ╦┘Īó£╩┤_Ą─Ą├ĄĮĮY╣¹Ż¼▀@ĘN╚╦╚Ō╦č╦„Ą─ĘĮ╩ĮīŹ┘|Š═╩Ū▒Ŗ░³(Crowdsourcing)ĪŻ┤¾öĄō■Ģr┤·Ą─ļ[╦Į▒Żūo├µ┼Rų°╝╝ąg║═╚╦┴”īė├µĄ─ļpųž┐╝“×ĪŻ
2ĪóöĄō■╣½ķ_┼cļ[╦Į▒ŻūoĄ─├¼Č▄ĪŻ╚ń╣¹āHāH×ķ┴╦▒Żūoļ[╦ĮŠ═īó╦∙ėąĄ─öĄō■Č╝╝ėęįļ[▓žŻ¼─Ū├┤öĄō■Ą─ārųĄĖ∙▒Š¤oĘ©¾w¼FĪŻöĄō■╣½ķ_╩ŪĘŪ│Żėą▒žę¬Ą─Ż¼š■Ė«┐╔ęįÅ─╣½ķ_Ą─öĄō■ųąüĒ┴╦ĮŌš¹éĆć°├±ĮøØ·╔ńĢ■Ą─▀\ąąŻ¼ęį▒ŃĖ³║├Ą─ųĖī¦╔ńĢ■Ą─▀\▐DĪŻŲ¾śIät┐╔ęįÅ─╣½ķ_Ą─öĄō■ųą┴╦ĮŌ┐═æ¶Ą─ąą×ķŻ¼Å─Č°═Ų│÷ßśī”ąįĄ─«aŲĘ║═Ę■䚯¼ūŅ┤¾╗»Ųõ└¹ęµĪŻčąŠ┐š▀ät┐╔ęį└¹ė├╣½ķ_Ą─öĄō■Ż¼Å─╔ńĢ■ĪóĮøØ·Īó╝╝ągĄ╚▓╗═¼Ą─ĮŪČ╚üĒ▀MąąčąŠ┐ĪŻę“┤╦┤¾öĄō■Ģr┤·Ą─ļ[╦Įąįų„ę¬¾w¼Fį┌▓╗▒®┬Čė├æ¶├¶Ėąą┼ŽóĄ─Ū░╠ߎ┬▀Mąąėąą¦Ą─öĄō■═┌Š“Ż¼▀@ėąäeė┌é„ĮyĄ─ą┼Žó░▓╚½ŅIė“Ė³╝ėĻPūó╬─╝■Ą─╦Į├▄ąįĄ╚░▓╚½ī┘ąįĪŻĮyėŗöĄō■ÄņöĄō■蹊┐ųąūŅįńķ_š╣öĄō■ļ[╦Įąį╝╝ągĘĮ├µĄ─蹊┐Ż¼Į³─ĻüĒųØu│╔×ķŽÓĻPŅIė“Ą─蹊┐¤ß³cĪŻDwork į┌2006 ─Ļ╠ß│÷┴╦ą┬Ą─▓ŅĘųļ[╦Į(Differential Privacy)ĘĮĘ©ĪŻ▓ŅĘųļ[╦Į▒Żūo╝╝ąg┐╔─▄╩ŪĮŌøQ┤¾öĄō■ųąļ[╦Į▒Żūoå¢Ņ}Ą─ę╗éĆĘĮŽ“Ż¼Ą½╩Ū▀@ĒŚ╝╝ągļxīŹļHæ¬ė├▀Ć║▄▀hĪŻ
3ĪóöĄō■äėæBąįĪŻ┤¾öĄō■Ģr┤·öĄō■Ą─┐ņ╦┘ūā╗»│²┴╦ę¬Ū¾ėąą┬Ą─öĄō■╠Ä└Ē╝╝ągæ¬ī”ų«═ŌŻ¼ę▓Įoļ[╦Į▒ŻūoĦüĒ┴╦ą┬Ą─╠¶æĪŻ¼Fėąļ[╦Į▒Żūo╝╝ągų„ę¬╗∙ė┌ņoæBöĄō■╝»Ż¼Č°į┌¼FīŹųąöĄō■─Ż╩Į║═öĄō■ā╚╚▌Ģr┐╠Č╝į┌░l╔·ų°ūā╗»ĪŻę“┤╦į┌▀@ĘNĖ³╝ėÅ═ļsĄ─ŁhŠ│Ž┬īŹ¼Fī”äėæBöĄō■Ą─└¹ė├║═ļ[╦Į▒ŻūoīóĖ³Š▀╠¶æĪŻ
5.4 ┤¾öĄō■─▄║─å¢Ņ}
į┌─▄į┤ārĖ±╔ŽØqĪóöĄō■ųąą─┤µā”ęÄ─Ż▓╗öÓöU┤¾Ą─Į±╠ņŻ¼Ė▀─▄║─ęčųØu│╔×ķųŲ╝s┤¾öĄō■┐ņ╦┘░lš╣Ą─ę╗éĆų„ę¬Ų┐ŅiĪŻÅ─ąĪą═╝»╚║ĄĮ┤¾ęÄ─ŻöĄō■ųąą─Č╝├µ┼Rų°ĮĄĄ═─▄║─Ą─å¢Ņ}Ż¼Ą½╩Ū╔ą╬┤ę²ŲūŃē“ČÓĄ─ųžęĢŻ¼ŽÓĻPĄ─蹊┐│╔╣¹ę▓▌^╔┘ĪŻį┌┤¾öĄō■╣▄└ĒŽĄĮyųąŻ¼─▄║─ų„ę¬ė╔ā╔┤¾▓┐ĘųĮM│╔Ż║ė▓╝■─▄║─║═▄ø╝■─▄║─Ż¼Č■š▀ų«ųąėųęįė▓╝■─▄║─×ķų„ĪŻ└ĒŽļĀŅæBŽ┬Ż¼š¹éĆ┤¾öĄō■╣▄└ĒŽĄĮyĄ──▄║─æ¬įō║═ŽĄĮy└¹ė├┬╩│╔š²▒╚ĪŻĄ½╩ŪīŹļHŪķør▓ó▓╗Ž±ŅAŲ┌ŪķørŻ¼ŽĄĮy└¹ė├┬╩×ķ0Ą─Ģr║“╚į╚╗ėą─▄┴┐Ž¹║─ĪŻßśī”▀@éĆå¢Ņ}Ż¼ĪČ╝~╝sĢrł¾ĪĘ║═¹£┐ŽÕaĮø▀^ę╗─ĻĄ─┬ō║Žš{▓ķŻ¼ūŅĮKį┌ĪČ╝~╝sĢrł¾ĪĘ╔Ž░l▒Ē╬─š┬ĪČPower, Pollution and the InternetĪĘĪŻš{▓ķ’@╩ŠGoogleöĄō■ųąą──Ļ║─ļŖ┴┐╝s×ķ300╚f═▀Ż¼Č°Facebookätį┌60╚f═▀ū¾ėęĪŻūŅ┴Ņ╚╦¾@ėĀĄ─╩Ūį┌▀@ą®Š▐┤¾Ą──▄║─ųąŻ¼ų╗ėą6%-12%Ą──▄┴┐▒╗ė├üĒĒææ¬ė├æ¶Ą─▓ķįā▓ó▀Mąąėŗ╦ŃĪŻĮ^┤¾▓┐ĘųĄ─ļŖ─▄ė├ęį┤_▒ŻĘ■äšŲ„╠Äė┌ķeų├ĀŅæBŻ¼ęįæ¬ī”═╗╚ńŲõüĒĄ─ŠWĮj┴„┴┐Ė▀ĘÕŻ¼▀@ĘNŅÉą═Ą─╣”║─ūŅĖ▀┐╔ęįš╝ĄĮöĄō■ųąą─╦∙ėą─▄║─Ą─80%ĪŻÅ─ęčėąĄ─ę╗ą®čąŠ┐│╔╣¹üĒ┐┤Ż¼┐╔ęį┐╝æ]ęįŽ┬ā╔éĆĘĮ├µüĒĖ─╔Ų┤¾öĄō■─▄║─å¢Ņ}Ż║
1Īó▓╔ė├ą┬ą═Ą═╣”║─ė▓╝■ĪŻÅ─╝~╝sĢrł¾Ą─š{▓ķųą┐╔ęįų¬Ą└Į^┤¾▓┐ĘųĄ──▄┴┐Č╝║─┘Mį┌┤┼▒P╔ŽĪŻį┌┐šķeĄ─ĀŅæBŽ┬Ż¼é„ĮyĄ─┤┼▒P╚į╚╗Š▀ėą║▄Ė▀Ą──▄║─Ż¼▓óŪęļSų°ŽĄĮy└¹ė├┬╩Ą─╠ßĖ▀Ż¼─▄║─ę▓į┌ųØu╔²Ė▀ĪŻą┬ą═ĘŪęū╩¦┤µā”Ų„╝■Ą─│÷¼FŻ¼Įo┤¾öĄō■╣▄└ĒŽĄĮyĦüĒĄ─ą┬Ą─ŽŻ═¹ĪŻķW┤µĪóPCMĄ╚ą┬ą═┤µā”ė▓╝■Š▀ėąĄ═─▄║─Ą─╠žąįĪŻļm╚╗ļSų°ŽĄĮy└¹ė├┬╩Ą─╠ßĖ▀Ż¼ķW┤µĪóPCMĄ╚Ą──▄║─ę▓ėą╦∙╔²Ė▀Ż¼Ą½╩ŪŲõ┐é¾w─▄║─╚į▀h▀hĄ═ė┌é„Įy┤┼▒PĪŻ
2Īóę²╚ļ┐╔į┘╔·Ą─ą┬─▄į┤ĪŻöĄō■ųąą─╦∙╩╣ė├Ą─ļŖ─▄Į^┤¾▓┐ĘųČ╝╩ŪÅ─▓╗┐╔į┘╔·Ą──▄į┤ųą«a╔·Ą─ĪŻ╚ń╣¹─▄ē“į┌┤¾öĄō■┤µā”║═╠Ä└Ēųąę²╚ļųT╚ń╠½Ļ¢─▄Īó’L─▄ų«ŅÉĄ─┐╔į┘╔·─▄į┤Ż¼īóį┌║▄┤¾│╠Č╚╔ŽŠÅĮŌ─▄║─å¢Ņ}ĪŻ
5.5 ┤¾öĄō■╠Ä└Ē┼cė▓╝■Ą─ģf═¼
ė▓╝■Ą─┐ņ╦┘╔²╝ēōQ┤·ėą┴”Ą─┤┘▀M┴╦┤¾öĄō■Ą─░lš╣Ż¼Ą½╩Ū▀@ę▓į┌ę╗Č©│╠Č╚╔Žįņ│╔┴╦┤¾┴┐▓╗═¼╝▄śŗė▓╝■╣▓┤µĄ─Šų├µĪŻ╚šęµÅ═ļsĄ─ė▓╝■ŁhŠ│Įo┤¾öĄō■╣▄└ĒĦüĒĄ─ų„ę¬╠¶æėąŻ║
1Īóė▓╝■«ÉśŗąįĦüĒĄ─┤¾öĄō■╠Ä└ĒļyŅ}ĪŻš¹éĆöĄō■ųąą─Ż©╝»╚║Ż®ā╚▓┐▓╗═¼ÖCŲ„ų«ķgĄ─ąį─▄Ģ■┤µį┌ų°├„’@Ą─▓ŅäeŻ¼ę“×ķ▓╗═¼ĢrŲ┌┘Å╚ļĄ─▓╗═¼ÅS╔╠Ą─Ę■äšŲ„į┌IOPSĪóCPU╠Ä└Ē╦┘Č╚Ą╚ąį─▄ĘĮ├µĢ■ėą║▄┤¾Ą─▓Ņ«ÉĪŻ▀@Š═ī¦ų┬┴╦ė▓╝■ŁhŠ│Ą─«Éśŗąį(Heterogeneous)Ż¼Č°▀@ĘN«ÉśŗąįĢ■Įo┤¾öĄō■Ą─╠Ä└ĒĦüĒųTČÓå¢Ņ}ĪŻę╗éĆĄõą═Ą─└²ūėŠ═╩ŪMapReduce╚╬äš▀^│╠ųąŻ¼Ųõ┐éĄ─╠Ä└ĒĢrķg║▄┤¾│╠Č╚╔Ž╚ĪøQė┌Map▀^│╠ųą╠Ä└ĒĢrķgūŅķLĄ─╣سcĪŻ╚ń╣¹╝»╚║ųąė▓╝■Ą─ąį─▄▓Ņ«É▀^┤¾Ż¼ätĢ■ī¦ų┬┤¾┴┐Ą─ėŗ╦ŃĢrķg└╦┘Mį┌ąį─▄▌^║├Ą─Ę■äšŲ„Ą╚┤²ąį─▄▌^▓ŅĄ─Ę■äšŲ„╔ŽĪŻ▀@ĘNŪķørŽ┬Ę■äšŲ„Ą─ŠĆąįį÷ķL▓ó▓╗ę╗Č©Ģ■ĦüĒėŗ╦Ń─▄┴”Ą─ŠĆąįį÷ķLŻ¼ę“×ķ“─Š═░ą¦æ¬”ųŲ╝s┴╦š¹éĆ╝»╚║Ą─ąį─▄ĪŻę╗░ŃĄ─ĮŌøQĘĮ░Ė╩Ū┐╝æ]ė▓╝■«ÉśŗĄ─ŁhŠ│Ž┬īó▓╗═¼ėŗ╦ŃÅŖČ╚Ą─╚╬äšųŪ─▄Ą─Ęų┼õĮoėŗ╦Ń─▄┴”▓╗═¼Ą─Ę■äšŲ„Ż¼Ą½╩Ū«ö▀@ĘN«ÉśŗŁhŠ│Ą─ęÄ─ŻöUš╣ĄĮöĄęį╚fėŗĄ─╝»╚║Ģrå¢Ņ}īóūāĄ├śO×ķÅ═ļsĪŻ
2Īóą┬ė▓╝■Įo┤¾öĄō■╠Ä└ĒĦüĒĄ─ūāĖ’ĪŻ╦∙ėąĄ─▄ø╝■ŽĄĮyČ╝╩ŪśŗĮ©į┌é„ĮyĄ─ėŗ╦ŃÖC¾wŽĄĮYśŗų«╔ŽŻ¼╝┤CPU-ā╚┤µ-ė▓▒P╚²╝ēĮYśŗĪŻCPUĄ─░lš╣ę╗ų▒ū±čŁų°─”Ā¢Č©┬╔Ż¼ŪęŲõ╝▄śŗęčĮøÅ─å╬║╦▐D╚ļČÓ║╦ĪŻę“┤╦ąĶę¬╔Ņ╚ļ蹊┐╚ń║╬ūī▄ø╝■Ė³║├Ą─└¹ė├CPUČÓ║╦ą─ų«ķgĄ─▓ó░lÖCųŲĪŻė╔ė┌ÖCąĄ╠žąįĄ─Ž▐ųŲŻ¼╗∙ė┌┤┼ąįĮķ┘|Ą─ė▓▒PŻ©Hard Disk Drive, HDDŻ®Ą─ūxīæ╦┘┬╩į┌▀^╚źÄū╩«─Ļųą╠ß╔²▓╗┤¾Ż¼Č°Ūę╬┤üĒę▓▓╗╠½┐╔─▄│÷¼FĖ’├³ąįĄ─╠ß╔²ĪŻ╗∙ė┌ķW┤µĄ─╣╠æBė▓▒P(Solid State Disk,SSD)Ą─│÷¼FÅ─ė▓╝■īė×ķ┤µā”ŽĄĮyĮYśŗĄ─Ė’ą┬╠ß╣®┴╦ų¦│ųŻ¼×ķėŗ╦ŃÖC┤µā”╝╝ągĄ─░lš╣║═┤µā”─▄ą¦Ą─╠ßĖ▀ĦüĒ┴╦ą┬Ą─Ų§ÖCĪŻSSDŠ▀ėą║▄ČÓā×┴╝╠žąįŻ¼ų„ę¬░³└©śOĖ▀Ą─ūxīæąį─▄Īó┐╣šąįĪóĄ═╣”║─Īó¾wĘeąĪĄ╚Ż¼ę“┤╦š²Ą├ĄĮįĮüĒįĮÅVĘ║Ą─æ¬ė├ĪŻĄ½╩Ūų▒ĮėīóSSDæ¬ė├ĄĮ¼FėąĄ─▄ø╝■╔Ž▓ó▓╗ę╗Č©Ģ■ĦüĒ▄ø╝■ąį─▄Ą─┤¾Ę∙╠ß╔²ĪŻSang-Won LeeĄ╚╚╦Ą─蹊┐▒Ē├„ļm╚╗SSDĄ─ūxīæ╦┘┬╩╩ŪHDDĄ─60~150▒ČŻ¼╗∙ė┌SSDĄ─öĄō■ÄņŽĄĮyĄ─▓ķįāĢrķgģsāHāH╠ß╔²┴╦▓╗ĄĮ10▒ČĪŻČ■š▀ų«ķgĄ─Š▐┤¾▓ŅŠÓų„ę¬╩Ūė╔SSDĄ─ę╗ą®╠žąįįņ│╔Ą─Ż¼▀@ą®╠žąį░³└©Ż║SSDīæŪ░▓┴│²╠žąįī¦ų┬Ą─ūxīæ▓┘ū„┤·ār▓╗ī”ĘQĪóSSD┤µā”ąŠŲ¼Ą─▓┴│²┤╬öĄėąŽ▐Ą╚ĪŻ▄ø╝■įOėŗų«Ģr▒žĒÜūą╝Ü┐╝æ]▀@ą®╠žąį▓┼─▄ē“│õĘų└¹ė├SSDĄ─ā×┴╝╠žąįĪŻ┼c┤¾╚▌┴┐┤┼▒P║═┤┼▒PĻć┴ąŽÓ▒╚Ż¼╣╠æBė▓▒PĄ─┤µā”╚▌┴┐ŽÓī”▌^Ą═Ż¼å╬╬╗╚▌┴┐Ą─ārĖ±▀hĖ▀ė┌┤┼▒PĪŻŪę▓╗═¼ŅÉą═Ą─╣╠æBė▓▒P«aŲĘąį─▄▓Ņ«É▌^┤¾Ż¼īó╣╠æBė▓▒Pų▒Įė╠µōQ┤┼▒Pæ¬ė├ĄĮ¼FėąĄ─┤µā”¾wŽĄųąļyęį│õĘų░lō]Ųõąį─▄ĪŻę“┤╦¼FļAČ╬┐╔ęį┐╝æ]═©▀^śŗĮ©HDD║═SSDĄ─╗ņ║Ž┤µā”ŽĄĮyüĒĮŌøQ┤¾öĄō■╠Ä└Ēå¢Ņ}ĪŻ«öŪ░╗ņ║Ž┤µā”ŽĄĮyĄ─īŹ¼Fų„ę¬ėą╚²ĘN╦╝┬ĘŻ║
HDDū„×ķā╚┤µĄ─öUš╣│õ«öSSDīæŠÅø_Ż╗HDD║═SSD═¼ū÷Č■╝ē┤µā”Ż╗SSDė├ū„ā╚┤µĄ─öUš╣│õ«öHDDūxīæŠÅø_ĪŻć°═ŌĄ─GoogleĪóFacebookŻ¼ć°ā╚Ą─░┘Č╚Īó╠įīÜĄ╚╣½╦ŠęčĮøķ_╩╝į┌īŹļH▀\ĀIŁhŠ│ųą┤¾ęÄ─ŻĄ─╩╣ė├╗ņ║Ž┤µā”ŽĄĮyüĒ╠ß╔²š¹¾wąį─▄ĪŻį┌▀@╚²╝ēĮYśŗų«ųąŻ¼ā╚┤µĄ─░lš╣╠Äė┌ę╗éĆŽÓī”ŠÅ┬²Ą─ļAČ╬Ż¼ę╗ų▒ø]ėą│÷¼FĖ’├³ąįĄ─ūā╗»ĪŻśŗĮ©╚╬║╬ę╗éĆ▄ø╝■ŽĄĮyČ╝Ģ■╝┘įOā╚┤µ╩Ūę╗éĆ╚▌┴┐ėąŽ▐Ą─ęū╩¦ĮYśŗ¾wĪŻļSų°ęįPCM×ķ┤·▒ĒĄ─SCMĄ─│÷¼FŻ¼╬┤üĒĄ─ā╚┤µśOėą┐╔─▄Ģ■╝µŠ▀¼Fį┌ā╚┤µ║═┤┼▒PĄ─ļpųž╠žąįŻ¼╝┤╠Ä└Ē╦┘Č╚śO┐ņŪęĘŪęū╩¦ĪŻļm╚╗PCM╔ą╬┤ėą┐╔ęį┤¾ęÄ─Ż┴┐«aĄ─«aŲĘ═Ų│÷Ż¼Ą½╩ŪĖ„┤¾ų„┴„ÅS╔╠Č╝ī”ŲõĘŪ│ŻųžęĢŻ¼╚²ąŪļŖūėį┌2012─Ļć°ļH╣╠æBļŖ┬ĘĢ■ūh(ISSCC 2012)╔Ž░l▒Ē┴╦▓╔ė├20nm╣ż╦ćųŲ│╠Ą─╚▌┴┐×ķ8GĄ─PCMį¬╝■ĪŻę╗Ą®PCM─▄ē“┤¾ęÄ─ŻĄ─═Č╚ļ╩╣ė├Ż¼▒žīóĮo¼FėąĄ─┤¾öĄō■╠Ä└ĒĦüĒę╗ł÷Ė∙▒ŠąįĄ─ūāĖ’ĪŻŲ®╚ńŪ░├µ╠ߥĮĄ─┴„╠Ä└Ē─Ż╩ĮŠ═┐╔ęį▓╗į┘īóā╚┤µĄ─┤¾ąĪŽ▐ųŲū„×ķ╦ŃĘ©įOėŗ▀^│╠ųąĄ─ę╗éĆų„ę¬┐╝æ]ę“╦žĪŻ
5.6 ┤¾öĄō■╣▄└Ēęūė├ąį(Usability)å¢Ņ}
Å─öĄō■╝»│╔ĄĮöĄō■Ęų╬÷Ż¼ų▒ĄĮūŅ║¾Ą─öĄō■ĮŌßīŻ¼ęūė├ąį欫öž×┤®š¹éĆ┤¾öĄō■Ą─┴„│╠ĪŻęūė├ąįĄ─╠¶æ═╗│÷¾w¼Fį┌ā╔éĆĘĮ├µŻ║╩ūŽ╚┤¾öĄō■Ģr┤·Ą─öĄō■┴┐┤¾Ż¼Ęų╬÷Ė³Å═ļsŻ¼Ą├ĄĮĄ─ĮY╣¹ą╬╩ĮĖ³╝ėĄ─ČÓśė╗»ĪŻŲõÅ═ļs│╠Č╚ęčĮø▀h▀h│¼│÷é„ĮyĄ─ĻPŽĄöĄō■ÄņĪŻŲõ┤╬┤¾öĄō■ęčĮøÅVĘ║ØB═ĖĄĮ╚╦éā╔·╗ŅĄ─Ė„éĆĘĮ├µŻ¼║▄ČÓąąśIČ╝ķ_╩╝ėą┴╦┤¾öĄō■Ęų╬÷Ą─ąĶŪ¾ĪŻĄ½╩Ū▀@ą®ąąśIĄ─Į^┤¾▓┐ĘųÅ─śIš▀Č╝▓╗╩ŪöĄō■Ęų╬÷Ą─īŻ╝ęŻ¼į┌Å═ļsĄ─┤¾öĄō■╣żŠ▀├µŪ░Ż¼╦¹éāų╗╩Ū│§╝ēĄ─╩╣ė├š▀(NaïveUsers)ĪŻÅ═ļsĄ─Ęų╬÷▀^│╠║═ļyęį└ĒĮŌĄ─Ęų╬÷ĮY╣¹Ž▐ųŲ┴╦╦¹éāÅ─┤¾öĄō■ųą½@╚Īų¬ūRĄ──▄┴”ĪŻ▀@ā╔éĆįŁę“ī¦ų┬ęūė├ąį│╔×ķ┤¾öĄō■Ģr┤·▄ø╝■╣żŠ▀įOėŗĄ─ę╗éĆŠ▐┤¾╠¶æĪŻĻPė┌┤¾öĄō■ęūė├ąįĄ─蹊┐╚į╠Äė┌ę╗éĆŲ▓ĮļAČ╬ĪŻÅ─įOėŗīWĄ─ĮŪČ╚üĒ┐┤ęūė├ąį▒Ē¼F×ķęūęŖ(Easy to discover)ĪóęūīW(Easyto learn)║═ęūė├ (Easy to use)ĪŻę¬Žļ▀_ĄĮęūė├ąįŻ¼ąĶę¬ĻPūóęįŽ┬╚²éĆ╗∙▒ŠįŁät[138]Ż║
1Īó┐╔ęĢ╗»įŁät(Visibility)ĪŻ┐╔ęĢąįę¬Ū¾ė├æ¶į┌ęŖĄĮ«aŲĘĢrŠ═─▄ē“┤¾ų┬┴╦ĮŌŲõ│§▓ĮĄ─╩╣ė├ĘĮĘ©Ż¼ūŅĮKĄ─ĮY╣¹ę▓ę¬─▄ē“ŪÕ╬·Ą─š╣¼F│÷üĒĪŻßśī”MapReduce ╩╣ė├Å═ļsĄ─ŪķørŻ¼╬┤üĒ╚ń║╬īŹ¼FĖ³ČÓ┤¾öĄō■╠Ä└ĒĘĮĘ©║═╣żŠ▀Ą─║åęū╗»║═ūįäė╗»īó╩Ūę╗éĆ║▄┤¾Ą─╠¶æĪŻ│²┴╦╣”─▄įOėŗų«═ŌŻ¼ūŅĮKĮY╣¹Ą─š╣╩Šę▓ę¬│õĘų¾w¼F┐╔ęĢ╗»Ą─įŁätĪŻ┐╔ęĢ╗»╝╝ąg╩ŪūŅ╝čĄ─ĮY╣¹š╣╩ŠĘĮ╩Įų«ę╗Ż¼═©▀^ŪÕ╬·Ą─łDą╬łDŽ±š╣╩Šų▒ė^Ą─Ę┤ė││÷ūŅĮKĮY╣¹ĪŻĄ½╩Ū│¼┤¾ęÄ─ŻĄ─┐╔ęĢ╗»ģs├µ┼Rų°ųTČÓ╠¶æŻ¼ų„ę¬ėąŻ║įŁ╬╗Ęų╬÷Ż╗ė├æ¶Įń├µ┼cĮ╗╗źįOėŗŻ╗┤¾öĄō■┐╔ęĢ╗»Ż╗öĄō■Äņ┼c┤µā”Ż╗╦ŃĘ©Ż╗öĄō■ęŲäėĪóé„▌ö║═ŠWĮj╝▄śŗŻ╗▓╗┤_Č©ąįĄ─┴┐╗»Ż╗▓óąą╗»Ż╗├µŽ“ŅIė“┼cķ_░lĄ─ÄņĪó┐“╝▄ęį╝░╣żŠ▀Ż╗╔ńĢ■Īó╔ńģ^ęį╝░š■Ė«ģó┼cĪŻ
2ĪóŲź┼õįŁät(Mapping)ĪŻ╚╦Ą─šJų¬ųąĢ■└¹ė├¼FėąĄ─Įø“×üĒ┐╝æ]ą┬Ą─╣żŠ▀Ą─╩╣ė├ĪŻŲ®╚ńę╗╠ߥĮöĄō■ÄņŻ¼┴╦ĮŌĄ─╚╦Č╝Ģ■ŽļĄĮ╩╣ė├SQL šZčįüĒł╠ąąöĄō■▓ķįāĪŻį┌ą┬╣żŠ▀Ą─įOėŗ▀^│╠ųą▒M┐╔─▄īó╚╦éāęčėąĄ─Įø“×ų¬ūR┐╝æ]▀M╚źŻ¼Ģ■╩╣Ą├ą┬╣żŠ▀ĘŪ│Ż▒Ńė┌╩╣ė├Ż¼▀@Š═╩Ū╦∙ų^Ą─Ųź┼õįŁätĪŻMapReduce ─Żą═ļm╚╗īóÅ═ļsĄ─┤¾öĄō■╠Ä└Ē▀^│╠║å╗»×ķMap ║═Reduce Ą─▀^│╠Ż¼Ą½╩ŪŠ▀¾wĄ─Map ║═Reduce ║»öĄ╚įąĶę¬ė├æ¶ūį╝║ŠÄīæŻ¼▀@ī”ė┌Į^┤¾▓┐Ęųø]ėąŠÄ│╠Įø“ץ─ė├æ¶Č°čį╚į▀^ė┌Å═ļsĪŻ╚ń║╬īóą┬Ą─┤¾öĄō■╠Ä└Ē╝╝ąg║═╚╦éāęčĮø┴ĢæTĄ─╠Ä└Ē╝╝ąg║═ĘĮĘ©▀MąąŲź┼õīó╩Ū╬┤üĒ┤¾öĄō■ęūė├ąįĄ─ę╗éĆŠ▐┤¾╠¶æĪŻ▀@ĘĮ├µ¼Fį┌ęčĮøėą┴╦ą®│§▓ĮĄ─蹊┐╣żū„ĪŻßśī” MapReduce ╝╝ąg╚▒Ę”ŅÉ╦ŲSQL ś╦£╩šZčįĄ─╚§³cŻ¼čąŠ┐╚╦åTķ_░l│÷Ė³Ė▀īėĄ─šZčį║═ŽĄĮyĪŻĄõą═┤·▒ĒėąHadoopĄ─HiveQL║═Pig LatinĪóGoogle Ą─ SawzallĪó╬ó▄øĄ─SCOPE║═DryadLINQęį╝░MRQLĄ╚ĪŻSQL ▓ķįāėąūįäėā×╗»Ą─▀^│╠Ż¼Č°MapReduce ▓óø]ėąĪŻßśī”▀@³cŻ¼║═īŹ¼F┴╦MapReduce Ą─▓ķįāā×╗»Ų„ĪŻ═©▀^š{čą░l¼FŽĄĮyI/O ╚▀ėÓ╩Ūė╔ė┌▓ķįāų«ķgĄ─ĻP┬ōŻ©correlationsŻ®Ż¼×ķ┴╦ĮŌøQ▀@éĆå¢Ņ}Ż¼ū„š▀ę²╚ļ┴╦BSP(Batched Stream Processing)─Żą═Ż¼▓óį┌DryadLINQ ųąīŹ¼F┴╦▓ķįāā×╗»ŽĄĮyCometĪŻ▀Ćėą▓┐ĘųīWš▀Ą─╣żū„╝»ųąį┌īóSQL šZčįūįäė▐D╗»│╔MapReduce ╚╬äšĪŻ▒╚▌^┤·▒ĒąįĄ─ŽĄĮyėąYSmartĪóTenzingĄ╚ĪŻ▀Ćėąę╗ą®Ųõ╦¹Ą─╣żū„Ż¼▒╚╚ńS4Latinį┌S4 Ą─╗∙ĄA╔ŽīŹ¼F┴╦ę╗éĆą┬Ą─öĄō■╠Ä└Ē┐“╝▄Ż¼╩╣Ą├ė├æ¶┐╔ęįų▒Įėė├ŅÉ╦Ų▓ķįāĄ─ĘĮ╩ĮČ°▓╗╩ŪŠÄ│╠Ą─ĘĮ╩ĮäōĮ©ą┬Ą─┴„æ¬ė├ĪŻ▀@į┌║▄┤¾│╠Č╚╔ŽĖ─╔Ų┴╦┤¾öĄō■┴„╠Ä└ĒŲĮ┼_S4 Ą─ęūė├ąįĪŻ
3ĪóĘ┤üįŁät(Feedback)ĪŻÄ¦ėąĘ┤üĄ─įOėŗ╩╣Ą├╚╦éā─▄ē“ļSĢršŲ╬šūį╝║Ą─▓┘ū„▀M│╠ĪŻ▀MČ╚ŚlŠ═╩Ūę╗éĆ¾w¼FĘ┤üįŁätĄ─ĮøĄõ└²ūėĪŻ┤¾öĄō■ŅIė“ĻPė┌▀@ĘĮ├µĄ─╣żū„▌^╔┘Ż¼ėą▓┐ĘųīWš▀ķ_╩╝ĻPūóMapReduce │╠ą“ł╠ąą▀M│╠Ą─╣└ėŗĪŻé„ĮyĄ─▄ø╝■╣ż│╠ŅIė“Ż¼│╠ą“│÷¼Få¢Ņ}ų«║¾ėą▒╚▌^│╔╩ņĄ─š{įć╣żŠ▀┐╔ęįī”Õeš`Ą─│╠ą“▀MąąĮ╗╗ź╩ĮĄ─š{įćŻ¼ŽÓī”╚▌ęūšęĄĮÕeš`Ą─Ė∙į┤ĪŻĄ½╩Ū┤¾öĄō■Ģr┤·║▄ČÓ╣żŠ▀Ųõā╚▓┐ĮYśŗÅ═ļsŻ¼ī”ė┌Ųš═©ė├æ¶Č°čį▀@ą®╣żŠ▀Į³╦Ųė┌║┌║ą(black box)Ż¼š{įć▀^│╠Å═ļsŻ¼╚▒╔┘Ę┤üąįĪŻPerfXplainįOėŗ▓óīŹ¼F┴╦MapReduce Ą─║å▒Ń╗»š{į接ĮyĪŻ×ķ┴╦ĮŌøQ┤¾öĄō■įŲ(Big Data Cloud)ųą│╠ą“▓┐╩║═š{įćĄ─å¢Ņ}Ż¼īŹ¼F┴╦ę╗éĆ┐╔öUš╣Ą─▌p┴┐╝ēHadoop ąį─▄Ęų╬÷Ų„HiTuneĪŻ╚ń╣¹╬┤üĒ─▄ē“į┌┤¾öĄō■Ą─╠Ä└Ēųą┤¾ĘČć·Ą─ę²╚ļ╚╦ÖCĮ╗╗ź╝╝ągŻ¼╩╣Ą├╚╦éā─▄ē“▌^═Ļš¹Ą─ģó┼cš¹éĆĘų╬÷▀^│╠Ż¼Ģ■ėąą¦Ą─╠ßĖ▀ė├æ¶Ą─Ę┤üĖąŻ¼į┌║▄┤¾│╠Č╚╔Ž╠ßĖ▀ęūė├ąįĪŻ
ØMūŃ╚²éĆ╗∙▒ŠįŁätĄ─įOėŗŠ═─▄ē“▀_ĄĮ┴╝║├Ą─ęūė├ąįĪŻÅ─╝╝ągīė├µüĒ┐┤Ż¼┐╔ęĢ╗»Īó╚╦ÖCĮ╗╗źęį╝░öĄō■Ųį┤╝╝ągČ╝┐╔ęįėąą¦Ą─╠ß╔²ęūė├ąįĪŻČ°į┌▀@ą®╝╝ągĄ─▒│║¾Ż¼║Ż┴┐į¬öĄō■╣▄└ĒĄ─å¢Ņ}╩ŪąĶę¬╬ęéā╠žäeĻPūóĄ─ę╗éĆå¢Ņ}ĪŻį¬öĄō■╩ŪĻPė┌öĄō■Ą─öĄō■Ż¼öĄō■ų«ķgĄ─ĻP┬ōĻPŽĄęį╝░öĄō■▒Š╔ĒĄ─ę╗ą®ī┘ąį┤¾Č╝╩Ū┐┐į¬öĄō■üĒ▒Ē╩ŠĄ─ĪŻ┐╔ęĢ╗»╝╝ągļx▓╗ķ_į¬öĄō■Ą─ų¦│ųŻ¼ę“×ķ╚ń╣¹¤oĘ©£╩┤_Ą─▒Ēš„│÷öĄō■ų«ķgĄ─ĻPŽĄŻ¼Š═¤oĘ©ī”öĄō■▀Mąą┐╔ęĢ╗»Ą─š╣╩ŠĪŻöĄō■Ųį┤╝╝ągĖ³╩Ūļx▓╗ķ_į¬öĄō■╣▄└Ē╝╝ągĪŻę“×ķöĄō■Ųį┤ąĶę¬└¹ė├į¬öĄō■üĒėøõøöĄō■ų«ķg░³└©ę“╣¹ĻPŽĄį┌ā╚Ą─Ė„ĘNÅ═ļsĻPŽĄŻ¼▓ó═©▀^▀@ą®ą┼ŽóüĒ▀MąąŽÓĻPĄ─═ŲöÓĪŻ╚ń║╬į┌┤¾ęÄ─Ż┤µā”ŽĄĮyųąīŹ¼F║Ż┴┐į¬öĄō■Ą─Ė▀ą¦╣▄└ĒīóĢ■ī”┤¾öĄō■Ą─ęūė├ąį«a╔·ųžę¬ė░ĒæĪŻ
5.7 ąį─▄Ą─£yįć╗∙£╩(Benchmark)
ĻPŽĄöĄō■Äņ«aŲĘĄ─│╔╣”ļx▓╗ķ_ęįTPC ŽĄ┴ą×ķ┤·▒ĒĄ─£yįć╗∙£╩Ą─«a╔·ĪŻš²╩Ūėą┴╦▀@ą®£yįć╗∙£╩Ż¼▓┼─▄ē“£╩┤_Ą─║Ō┴┐▓╗═¼öĄō■Äņ«aŲĘĄ─ąį─▄Ż¼▓óī”Ųõ┤µį┌Ą─å¢Ņ}▀MąąĖ─▀MĪŻ─┐Ū░╔ą╬┤ėąßśī”┤¾öĄō■╣▄└ĒĄ─£yįć╗∙£╩Ż¼śŗĮ©┤¾öĄō■£yįć╗∙£╩├µ┼RĄ─ų„ę¬╠¶æėąŻ║
1ĪóŽĄĮyÅ═ļsČ╚Ė▀ĪŻ┤¾öĄō■╣▄└ĒŽĄĮyĄ─ŅÉą═ĘŪ│ŻČÓŻ¼║▄ČÓ╣½╦Šßśī”ūį╝║Ą─æ¬ė├ł÷Š░įOėŗ┴╦ŽÓæ¬Ą─öĄō■Äņ«aŲĘĪŻ▀@ą®«aŲĘĄ─╣”─▄─ŻēKĖ„«ÉŻ¼║▄ļyė├ę╗éĆĮyę╗Ą──Żą═üĒī”╦∙ėąĄ─┤¾öĄō■«aŲĘ▀MąąĮ©─ŻĪŻ
2Īóė├æ¶░Ė└²Ą─ČÓśėąįĪŻ£yįć╗∙£╩ąĶę¬Č©┴xę╗ŽĄ┴ąŠ▀ėą┤·▒ĒąįĄ─ė├æ¶ąą×ķŻ¼Ą½╩Ū┤¾öĄō■Ą─öĄō■ŅÉą═ÅVĘ║Ż¼æ¬ė├ł÷Š░ę▓▓╗▒MŽÓ═¼Ż¼║▄ļyÅ─ųą╠ß╚Ī│÷Š▀ėą┤·▒ĒąįĄ─ė├æ¶ąą×ķĪŻ
3ĪóöĄō■ęÄ─Ż²ŗ┤¾ĪŻ▀@Ģ■ĦüĒ┴╦ā╔ĘĮ├µĄ─╠¶æĪŻ╩ūŽ╚öĄō■ęÄ─Ż▀^┤¾╩╣Ą├öĄō■ųž¼FĘŪ│Ż└¦ļyŻ¼┤·ār║▄┤¾ĪŻŲõ┤╬į┌é„ĮyĄ─ TPC ŽĄ┴ą£yįćųąŻ¼£yį接ĮyĄ─ęÄ─Ż═∙═∙┤¾ė┌īŹļH┐═æ¶╩╣ė├Ą─öĄō■╝»Ż¼ę“┤╦£yįćĄ─ĮY╣¹┐╔ęį£╩┤_Ą─┤·▒ĒŽĄĮyĄ─īŹļHąį─▄ĪŻĄ½╩Ūį┌┤¾öĄō■Ģr┤·Ż¼ė├æ¶īŹļH╩╣ė├ŽĄĮyĄ─öĄō■ęÄ─Ż═∙═∙┤¾ė┌£yį接ĮyĄ─öĄō■ęÄ─ŻŻ¼ę“┤╦─▄ʱė├ąĪęÄ─ŻöĄō■Ą─£yįć╗∙£╩üĒ┤·▒ĒīŹļH«aŲĘĄ─ąį─▄╩Ū─┐Ū░├µ┼RĄ─ę╗éĆ╠¶æĪŻöĄō■ųž¼FĄ─å¢Ņ}┐╔ęįćLįć└¹ė├ę╗Č©Ą─ĘĮĘ©üĒ╚ź«a╔·£yįćśė└²Ż¼Č°▓╗╩Ū▀xō±Ž┬▌d─│éĆīŹļHĄ─£yįćöĄō■╝»ĪŻĄ½╩Ū▀@ėų╔µ╝░ĄĮ╚ń║╬╩╣«a╔·Ą─öĄō■╝»─▄šµīŹĘ┤ė│įŁ╩╝öĄō■╝»Ą─å¢Ņ}ĪŻ
4ĪóŽĄĮyĄ─┐ņ╦┘č▌ūāĪŻé„ĮyĄ─ĻPŽĄöĄō■ÄņŲõŽĄĮy╝▄śŗę╗░Ń▒╚▌^ĘĆČ©Ż¼Ą½╩Ū┤¾öĄō■Ģr┤·Ą─ŽĄĮy×ķ┴╦▀mæ¬öĄō■ęÄ─ŻĄ─▓╗öÓį÷ķL║═ąį─▄ę¬Ū¾Ą─▓╗öÓ╠ß╔²Ż¼▒žĒÜ▓╗öÓĄ─▀Mąą╔²╝ēŻ¼▀@╩╣Ą├£yįć╗∙£╩Ą├ĄĮĄ─£yįćĮY╣¹║▄┐ņŠ═▓╗─▄Ę┤ė│ŽĄĮy«öŪ░Ą─īŹļHąį─▄ĪŻ
5Īóųžą┬śŗĮ©▀Ć╩ŪÅ═ė├¼FėąĄ─£yįć╗∙£╩ĪŻ╚ń╣¹─▄ē“į┌¼FėąĄ─£yįć╗∙£╩ųą▀xō±║Ž▀mĄ─▀MąąöUš╣Ą─įÆŻ¼─Ū├┤īóśO┤¾£p╔┘śŗĮ©ą┬Ą─┤¾öĄō■£yįć╗∙£╩Ą─╣żū„┴┐ĪŻ┐╔─▄Ą─║“▀x£yįćś╦£╩ėąSWIM(Statistical Workload Injector for MapReduce)ĪóMRBSĪóHadoop ūįĦĄ─GridMixĪóTPC-DSĪóYCSB++Ą╚ĪŻ
¼Fį┌ęčĮøķ_╩╝ėą╣żū„ćLįćśŗĮ©┤¾öĄō■Ą─£yįć╗∙£╩Ż¼▒╚╚ńę╗ą®ßśī”┤¾öĄō■£yįć╗∙£╩Ą─Ģ■ūhWBDB 2012ĪóTPCTC 2012 Ą╚ĪŻĄ½╩Ūę▓ėąė^³cšJ×ķ«öŪ░ėæšō┤¾öĄō■£yįć╗∙£╩Ą─śŗĮ©×ķĢr╔ąįńĪŻYanpei Chen Ą╚═©▀^ī”7 éĆæ¬ė├MapReduce ╝╝ągĄ─īŹļH«aŲĘĄ─žō▌d▀Mąą┴╦Ė·█Ö║═Ęų╬÷Ż¼šJ×ķ¼Fį┌Ė∙▒Š¤oĘ©┤_Č©┤¾öĄō■Ģr┤·Ą─Ąõą═ė├æ¶░Ė└²ĪŻę“┤╦Å─▀@éĆĮŪČ╚üĒ┐┤▓ó▓╗▀m║ŽśŗĮ©┤¾öĄō■Ą─£yįć╗∙£╩Ż¼▀Ćėą║▄ČÓ╗∙ĄAąįĄ─å¢Ņ}žĮ┤²ĮŌøQĪŻ
┐éĄ─üĒšfŻ¼śŗĮ©┤¾öĄō■Ą─£yįć╗∙£╩╩Ūėą▒žę¬Ą─ĪŻĄ½╩Ū├µ┼RĄ─╠¶æĘŪ│ŻČÓŻ¼ę¬ŽļśŗĮ©ę╗éĆŅÉ╦ŲTPC Ą─╣½šJĄ─£yįćś╦£╩ļyČ╚║▄┤¾ĪŻ
6ĪóĮYšō
ļSų°įŲėŗ╦ŃĪó╬’┬ōŠWĄ╚Ą─░lš╣Ż¼öĄō■│╩¼F▒¼š©╩ĮĄ─į÷ķLŻ¼╚╦éāš²▒╗öĄō■║ķ┴„╦∙░³ć·Ż¼┤¾öĄō■Ą─Ģr┤·ęčĮøĄĮüĒĪŻš²┤_└¹ė├┤¾öĄō■Įo╚╦éāĄ─╔·╗ŅĦüĒ┴╦śO┤¾Ą─▒Ń└¹Ż¼Ą½ė┌┤╦═¼Ģrę▓Įoé„ĮyĄ─öĄō■╣▄└ĒĘĮ╩ĮĦüĒ┴╦śO┤¾Ą─╠¶æĪŻ▒Š╬─ī”ūŅĮ³Äū─Ļć°ā╚═Ō┤¾öĄō■ŽÓĻPĄ─蹊┐│╔╣¹▀Mąą┴╦╚½├µĄ─╗žŅÖ║═┐éĮYŻ¼ĮķĮB┴╦┤¾öĄō■Ą─╗∙▒ŠĖ┼─ŅŻ¼įö╝ÜĘų╬÷┴╦┤¾öĄō■╣▄└ĒĄ─ĻPµI╝╝ągŻ¼ų„ę¬╩ŪĻU╩÷įŲėŗ╦Ń╝╝ągī”ė┌┤¾öĄō■╣▄└ĒĄ─╗∙ĄAąįū„ė├ĪŻ▒Š╬─▀Ćų°ųžĮķĮB┴╦─┐Ū░┤¾öĄō■蹊┐├µ┼RĄ─ą┬╠¶æęį╝░ŽÓæ¬Ą─ę╗ą®čąŠ┐│╔╣¹ĪŻ┐éĄ─üĒšfŻ¼č█Ž┬ī”ė┌┤¾öĄō■Ą─蹊┐╚į╠Äė┌ę╗éĆĘŪ│Ż│§▓ĮĄ─ļAČ╬Ż¼▀Ćėą║▄ČÓ╗∙ĄAąįĄ─å¢Ņ}ėą┤²ĮŌøQĪŻ┤¾öĄō■Ą─ÄūéĆ╠žš„ųąŠ┐Š╣──éĆūŅųžę¬Ż┐├µī”┤¾öĄō■╣▄└Ē╬ęéāąĶꬥ─╩Ū║åå╬Ą─╝╝ąg╔ŽĄ─č▌ūāŻ©EvolutionŻ®▀Ć╩ŪÅžĄūĄ─ūāĖ’Ż©RevolutionŻ®Ż┐▓╗═¼īW┐ŲĄ─蹊┐š▀ų«ķgį§śėģfū„▓┼─▄Ė³ėą└¹ė┌┤¾öĄō■å¢Ņ}Ą─ĮŌøQŻ┐ųT╚ń┤╦ŅÉĄ─å¢Ņ}▀ĆėąįSČÓŻ¼ę¬ĮŌøQ┤¾öĄō■å¢Ņ}╚įėą║▄ķLĄ─┬Ęę¬ū▀Ż¼Ų┌═¹▒Š╬─Ą─ĮķĮB─▄Įo┤¾öĄō■蹊┐═¼ąąīWš▀╠ß╣®ę╗Č©Ą─ģó┐╝ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║┤¾öĄō■╣▄└ĒŻ║Ė┼─ŅĪó╝╝ąg┼c╠¶æŻ©Ž┬Ż®